Título original: Import AI 455: Sistemas de IA estão prestes a começar a se construir sozinhos.
Autor original: Jack Clark, cofundador da Anthropic
Tradução do original: Yang Wen, Chen Chen, Machine Heart
Essa visão não surgiu do nada. Ele analisou uma série de benchmarks públicos e descobriu que a IA está avançando muito rapidamente em tarefas relacionadas ao desenvolvimento de IA.
Por exemplo, CORE-Bench avalia a capacidade da IA de reproduzir artigos de pesquisa de outros, uma etapa crucial na pesquisa em IA.
PostTrainBench testa se modelos poderosos podem ajustar de forma autônoma modelos open source mais fracos para melhorar seu desempenho, o que é um subconjunto importante das tarefas de pesquisa e desenvolvimento de IA.
MLE-Bench, baseado em tarefas reais de competições no Kaggle, exige a construção de aplicações diversificadas de aprendizado de máquina para resolver problemas específicos. Além disso, benchmarks de codificação bem conhecidos, como SWE-Bench, também mostram avanços semelhantes.
Jack Clark descreve esse fenômeno como uma tendência “fractal”, ou seja, de crescimento contínuo em diferentes resoluções e escalas, onde progressos significativos podem ser observados. Ele acredita que a IA está se aproximando gradualmente da automação completa do desenvolvimento, e uma vez alcançada, ela poderá construir seus próprios sistemas sucessores de forma autônoma, iniciando um ciclo de auto-aperfeiçoamento.

Desde que essa afirmação foi feita, ela gerou bastante discussão nas redes sociais.
Alguns veem como um passo crucial rumo à ASI e ao singularidade, podendo transformar radicalmente o ritmo do avanço tecnológico.

Por outro lado, há vozes contrárias.
Pedro Domingos, professor de Ciência da Computação na Universidade de Washington, aponta que sistemas de IA já tinham a capacidade de “auto-construção” desde a invenção da linguagem LISP na década de 1950. A verdadeira questão é se essa capacidade trará retornos crescentes, e atualmente não há evidências claras de que isso aconteça.

Alguns questionam: de 2027 para 2028, a probabilidade aumenta de repente em 30%, o que sugere que uma grande ruptura na capacidade da IA pode ocorrer por volta do final de 2027. Mas qual marco ou evento específico realmente elevaria drasticamente a chance de auto-aperfeiçoamento recursivo da IA em um curto período?

Outro comentário aponta que Jack Clark é o novo responsável de relações públicas da Anthropic, e essa faz parte de sua nova estratégia: não estamos apenas fazendo alarmismo, há muitas pesquisas que confirmam as advertências que temos feito.
Clark escreveu um artigo detalhado na newsletter Import AI 455 explicando essa visão.
Vamos agora analisar essa matéria na íntegra.
Sistemas de IA prestes a se auto-construir: o que isso significa?
Clark afirma que escreveu esse artigo porque, ao revisar todas as informações públicas disponíveis, chegou a uma conclusão difícil: a possibilidade de uma pesquisa de IA sem participação humana até o final de 2028 é bastante alta, talvez superior a 60%.
Aqui, “pesquisa de IA sem participação humana” refere-se a um sistema de IA suficientemente avançado: capaz não só de auxiliar humanos na pesquisa, mas também de realizar autonomamente processos-chave de desenvolvimento, e até de construir sua próxima geração de sistemas.
Para Clark, isso é claramente um acontecimento de grande importância.
Ele admite que também tem dificuldade em compreender completamente o significado dessa possibilidade.
A razão de considerá-la uma avaliação relutante é o impacto potencial, que é tão grande que torna difícil de assimilar. Clark também não tem certeza se a sociedade está realmente preparada para as profundas mudanças que a automação do desenvolvimento de IA pode trazer.
Ele agora acredita que estamos vivendo um momento especial: a pesquisa de IA está prestes a se tornar totalmente automatizada de ponta a ponta. Se isso acontecer, será como cruzar o rio Rubicão, entrando em um futuro quase imprevisível.
Clark explica que o objetivo do artigo é esclarecer por que ele acredita que a decolagem do desenvolvimento de IA totalmente automatizado está em andamento.
Ele discutirá algumas possíveis consequências dessa tendência, mas a maior parte do texto se concentrará nas evidências que sustentam essa avaliação. Quanto às implicações mais profundas, Clark planeja continuar analisando ao longo do ano.
Ele não acredita que isso vá acontecer de fato em 2026, mas acha que nos próximos um ou dois anos veremos exemplos de modelos treinando seus próprios sucessores de ponta a ponta. Pelo menos em modelos não de ponta, é bastante provável uma prova de conceito; quanto aos modelos mais avançados, a dificuldade é maior, pois eles são extremamente caros e dependem de trabalho intensivo de muitos pesquisadores humanos.
A avaliação de Clark se baseia em informações públicas: artigos no arXiv, bioRxiv, NBER, além de produtos já implantados por empresas de ponta em IA. Com esses dados, ele conclui que as etapas necessárias para a produção automatizada de sistemas de IA — especialmente os componentes de engenharia — já estão praticamente disponíveis.
Se a tendência de escalonamento continuar, devemos nos preparar para uma situação em que os modelos se tornem suficientemente criativos para não só melhorar métodos existentes, mas também propor novas linhas de pesquisa e ideias originais, impulsionando o avanço da fronteira da IA por conta própria.
O ponto de singularidade na codificação: como as capacidades evoluem ao longo do tempo
Sistemas de IA são implementados por software, que por sua vez é composto por código.
A forma como o código é produzido por IA já mudou radicalmente. Existem duas tendências relacionadas: uma, a IA está cada vez melhor em escrever códigos complexos do mundo real; outra, ela está cada vez mais apta a encadear tarefas de codificação lineares, muitas vezes sem supervisão humana, como escrever código e testá-lo.
Dois exemplos típicos dessa tendência são o SWE-Bench e o gráfico de horizontes de tempo do METR.
Resolvendo problemas reais de engenharia de software
SWE-Bench é um teste amplamente utilizado para avaliar a capacidade de IA de resolver problemas reais do GitHub.
Quando foi lançado no final de 2023, o modelo com melhor desempenho era o Claude 2, com uma taxa de sucesso de cerca de 2%. Já o Claude Mythos Preview atingiu 93,9%, quase saturando esse benchmark.
Claro que todos os benchmarks têm ruído, e é comum que, após certo ponto, o limite não seja mais a capacidade do método, mas as próprias limitações do benchmark. Por exemplo, no conjunto de validação do ImageNet, cerca de 6% das etiquetas estão incorretas ou ambíguas.
SWE-Bench é uma métrica confiável para avaliar a capacidade geral de programação e o impacto da IA na engenharia de software. Clark afirma que a maioria das pessoas com quem entrou em contato em laboratórios de ponta e no Vale do Silício já usam IA para escrever código, e cada vez mais usam para criar testes e revisar códigos.
Em outras palavras, a IA já é suficientemente forte para automatizar uma parte importante do desenvolvimento de IA, acelerando significativamente o trabalho de pesquisadores e engenheiros humanos.
Medindo a capacidade de IA de realizar tarefas de longo prazo
O METR criou um gráfico para avaliar a complexidade das tarefas que a IA consegue realizar. Essa complexidade é calculada com base no tempo que um humano experiente levaria para completar essas tarefas.
O indicador mais importante é o tempo estimado para uma tarefa, quando a IA atinge cerca de 50% de confiabilidade.
O progresso nesse aspecto é impressionante:
· Em 2022, tarefas que GPT-3.5 consegue fazer levam aproximadamente 30 segundos para um humano.
· Em 2023, GPT-4 elevou esse tempo para 4 minutos.
· Em 2024, o modelo o1 aumentou para 40 minutos.
· Em 2025, GPT-5.2 High atingiu cerca de 6 horas.
· Em 2026, o Opus 4.6 elevou esse tempo para aproximadamente 12 horas.
Ajeya Cotra, que trabalha no METR e acompanha previsões de IA há anos, acredita que, até o final de 2026, a IA será capaz de realizar tarefas que levariam cerca de 100 horas para um humano.
A capacidade de IA de trabalhar de forma autônoma por períodos cada vez maiores está altamente relacionada ao uso de ferramentas de codificação com agência própria, ou seja, sistemas de IA que representam ações humanas e podem avançar tarefas de forma relativamente independente por um bom tempo.
Isso também reforça a ideia de que o desenvolvimento de IA em si pode estar se automatizando. Observar a rotina de muitos pesquisadores revela que muitas tarefas podem ser divididas em trabalhos de algumas horas, como limpeza de dados, leitura de dados, início de experimentos, etc.
Essas tarefas, hoje, já estão dentro do alcance do tempo de atuação de sistemas de IA modernos.
Quanto mais habilidosos os sistemas de IA ficarem, mais capazes de trabalhar de forma independente, mais eles poderão ajudar a automatizar partes do desenvolvimento de IA.
Dois fatores principais na delegação de tarefas:
· Primeiro, a confiança na capacidade do delegado;
· Segundo, a crença de que o delegado pode realizar o trabalho de forma autônoma, sem supervisão contínua.
Ao observar a atuação da IA na programação, percebe-se que ela não só fica cada vez mais competente, como também consegue trabalhar por períodos mais longos sem precisar de reorientação humana.
Isso se alinha com o que estamos vendo ao nosso redor: engenheiros e pesquisadores estão delegando tarefas cada vez maiores às IA. À medida que suas capacidades aumentam, as tarefas atribuídas também se tornam mais complexas e importantes.
A IA está adquirindo habilidades científicas essenciais para o desenvolvimento de IA
Imagine como funciona a pesquisa científica moderna, onde grande parte do trabalho consiste em definir uma direção, identificar que tipo de informação empírica se quer obter, projetar e conduzir experimentos, e verificar a validade dos resultados.
Com o aprimoramento das habilidades de programação da IA e o aumento da capacidade de modelagem do mundo por grandes modelos de linguagem, já surgiram ferramentas que ajudam cientistas humanos a acelerar o ritmo de pesquisa e automatizar parcialmente alguns processos em uma gama mais ampla de cenários de pesquisa.
Aqui, podemos observar o progresso da IA em algumas habilidades científicas essenciais, que também são partes integrantes da pesquisa em IA:
· Reproduzir resultados de pesquisa;
· Encadear técnicas de aprendizado de máquina e outros métodos para resolver problemas técnicos;
· Otimizar sistemas de IA próprios.
Executando artigos científicos completos e realizando experimentos relacionados
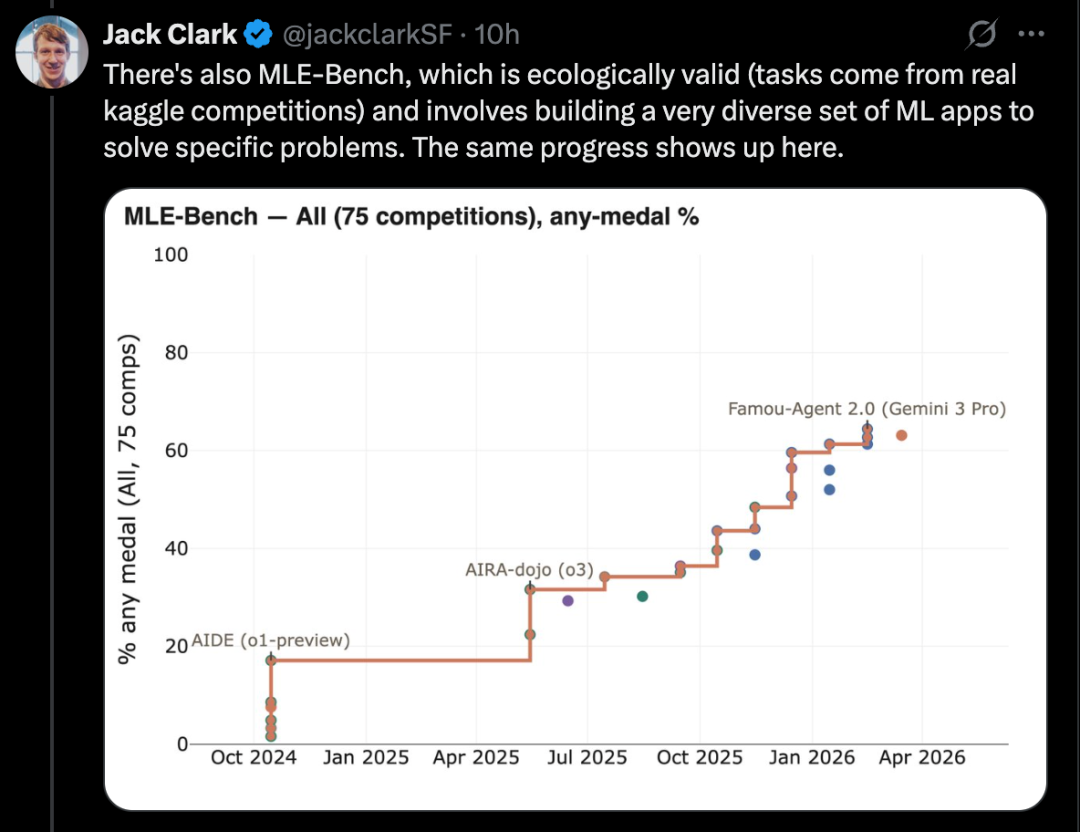
Uma tarefa central na pesquisa de IA é ler artigos científicos e reproduzir seus resultados. Nesse aspecto, a IA já avançou bastante em diversos benchmarks.
Um exemplo é o CORE-Bench, ou Benchmark de Reprodutibilidade Computacional de Agentes.
Esse benchmark exige que a IA reproduza os resultados de um artigo dado seu código-fonte e repositório. Especificamente, o agente deve instalar bibliotecas, rodar o código, buscar todos os outputs e responder às perguntas do desafio.
O CORE-Bench foi lançado em setembro de 2024. Na sua tarefa mais difícil, o melhor sistema foi o GPT-4o, rodando na estrutura CORE-Agent. Nesse conjunto, obteve cerca de 21,5% de pontuação.
Em dezembro de 2025, um dos autores do benchmark anunciou que ele havia sido resolvido: o modelo Opus 4.5 atingiu 95,5% de sucesso.
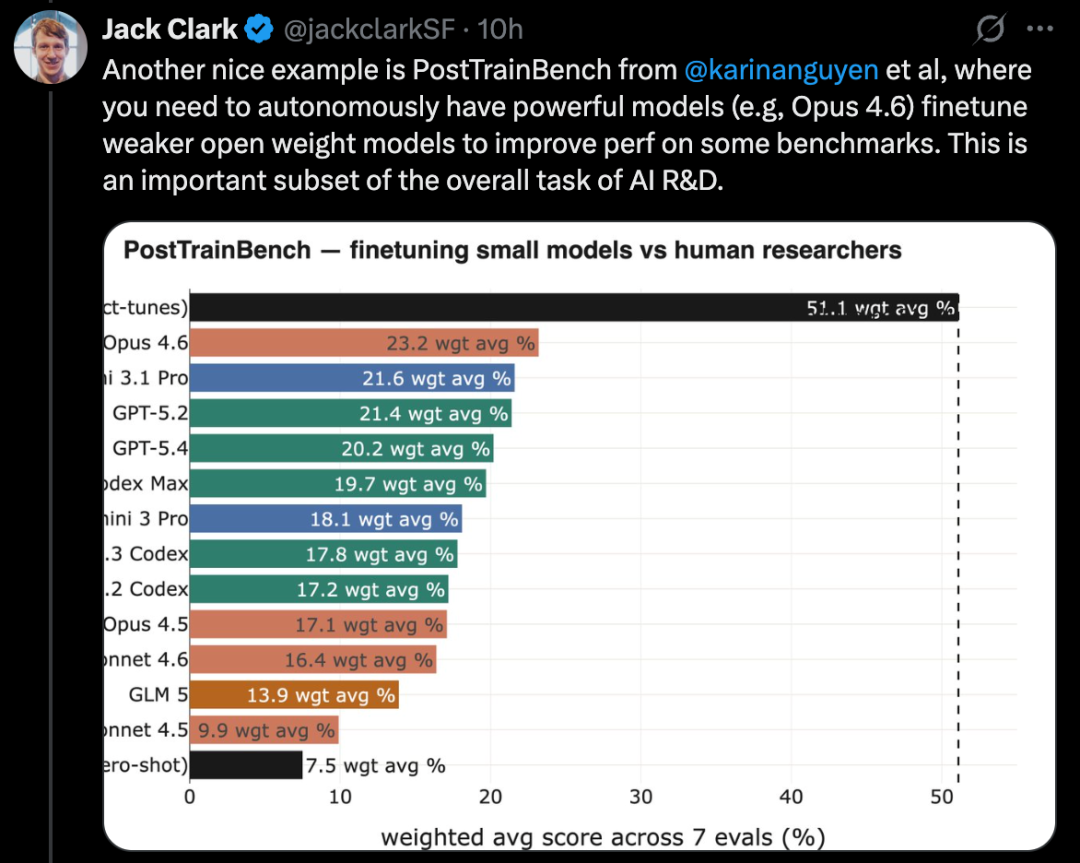
Construção de sistemas completos de aprendizado de máquina para competições no Kaggle
O MLE-Bench é um benchmark criado pela OpenAI para testar a capacidade de sistemas de IA de participar de competições no Kaggle em ambientes offline.
Ele cobre 75 tipos diferentes de competições, envolvendo áreas como processamento de linguagem natural, visão computacional e processamento de sinais.
O MLE-Bench foi lançado em outubro de 2024. Na época, o melhor sistema era um modelo o1 rodando na estrutura de agentes, com pontuação de 16,9%.
Em fevereiro de 2026, o sistema de melhor desempenho passou a ser o Gemini 3, operando com uma estrutura de agentes com busca, atingindo 64,4%.
Design de kernels
Uma tarefa mais difícil no desenvolvimento de IA é a otimização de kernels. “Kernel” refere-se à escrita e melhoria de códigos de baixo nível, que mapeiam operações específicas, como multiplicação de matrizes, de forma mais eficiente para o hardware.
A otimização de kernels é central porque determina a eficiência do treinamento e da inferência: ela afeta a quantidade de poder computacional que podemos usar de forma eficaz durante o desenvolvimento, e também a eficiência com que transformamos esse poder em capacidade de inferência após o treinamento.
Nos últimos anos, o uso de IA para projetar kernels passou de uma área de interesse para um campo de pesquisa altamente competitivo, com vários benchmarks. No entanto, esses benchmarks ainda não são muito populares, dificultando uma modelagem clara do progresso de longo prazo. Por outro lado, alguns estudos em andamento nos dão uma ideia da velocidade de avanço nesse setor.
Alguns trabalhos relevantes incluem:
· Uso do modelo DeepSeek para criar kernels de GPU melhores;
· Automação na conversão de módulos PyTorch em código CUDA;
· Meta usando LLMs para gerar kernels Triton otimizados, implantados em sua infraestrutura;
· E o desenvolvimento de modelos de peso open source ajustados para projetar kernels de GPU, como o Cuda Agent.
Um ponto importante: a criação de kernels possui atributos que a tornam especialmente adequada para pesquisa orientada por IA, como facilidade de validação dos resultados e sinais de recompensa bem definidos.
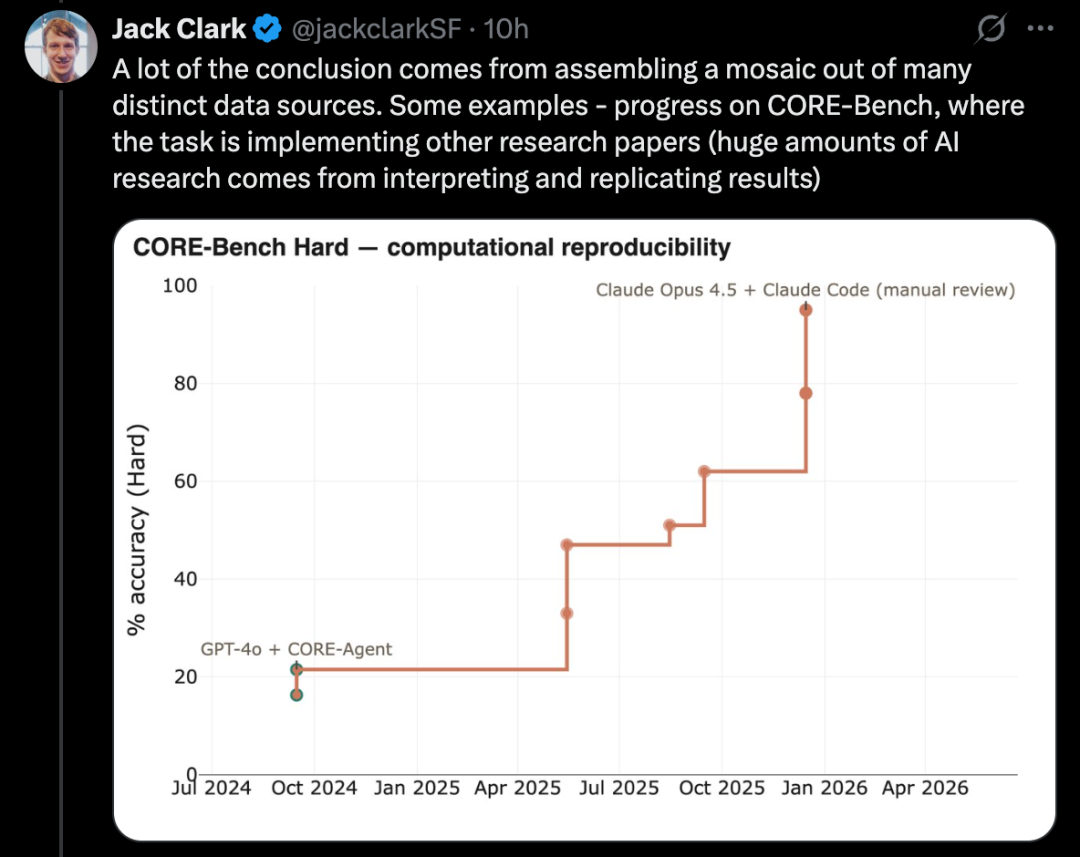
Ajustando modelos de linguagem por pós-treinamento (PostTrainBench)
Uma versão mais desafiadora desse tipo de teste é o PostTrainBench. Ele avalia se modelos de ponta podem pegar modelos open source menores e ajustá-los por meio de pós-treinamento para melhorar seu desempenho em benchmarks específicos.
Uma vantagem desse benchmark é que há uma forte linha de base humana: versões instruct-tuned desses pequenos modelos, desenvolvidas por pesquisadores de ponta, que já passaram por refinamento por especialistas altamente capacitados e estão em uso real. Assim, representam um padrão difícil de superar.
Até março de 2026, sistemas de IA já eram capazes de fazer pós-treinamento em modelos, obtendo melhorias de desempenho equivalentes a cerca de metade do que um humano conseguiria.
A pontuação é uma média ponderada de vários modelos de linguagem de pós-treinamento, incluindo Qwen 3 1.7B, Qwen 3 4B, SmolLM3-3B, Gemma 3 4B, além de benchmarks como AIME 2025, Arena Hard, BFCL, GPQA Main, GSM8K, HealthBench, HumanEval.
Em cada rodada, um agente CLI é solicitado a melhorar o desempenho de um modelo base em um benchmark específico.
Até abril de 2026, a pontuação máxima alcançada por um sistema de IA foi de aproximadamente 25% a 28%, incluindo modelos como Opus 4.6 e GPT 5.4; enquanto a pontuação humana é de 51%.
Esse já é um resultado bastante significativo.
Otimização do treinamento de modelos de linguagem
No último ano, a Anthropic tem reportado o desempenho de seu sistema em uma tarefa de treinamento de LLM, que consiste em otimizar um treinamento de modelo de linguagem pequeno, usando apenas CPU, para que ele rode o mais rápido possível.
A métrica de avaliação é: o fator de aceleração médio obtido pelo modelo em relação ao código inicial não modificado.
Esses resultados têm avançado bastante:
· Em maio de 2025, Claude Opus 4 conseguiu uma aceleração média de 2,9 vezes;
· Em novembro de 2025, o Opus 4.5 atingiu 16,5 vezes;
· Em fevereiro de 2026, o Opus 4.6 chegou a 30 vezes;
· Em abril de 2026, o Claude Mythos Preview atingiu 52 vezes.
Para entender o significado desses números, podemos fazer uma comparação: para um pesquisador humano, essa tarefa normalmente leva de 4 a 8 horas para alcançar uma aceleração de 4 vezes.
Meta-habilidades: gestão
Sistemas de IA também estão aprendendo a gerenciar outros sistemas de IA.
Isso já é visível em alguns produtos amplamente utilizados, como Claude Code ou OpenCode. Nesses, um agente principal supervisiona vários sub-agentes.
Isso permite que a IA lide com projetos de maior escala: múltiplos agentes com diferentes especializações podem trabalhar em paralelo, coordenados por um gestor AI, que também é um sistema de IA.
A pesquisa em IA: descobrir a relatividade geral ou montar Lego?
Uma questão central é: a IA pode inventar novas ideias para melhorar a si mesma? Ou esses sistemas são mais adequados para tarefas menos glamorosas, mas essenciais, que precisam ser feitas passo a passo?
Essa questão é importante porque influencia o quanto podemos automatizar o desenvolvimento de IA de ponta.
A avaliação do autor é: a IA ainda não consegue gerar ideias realmente inovadoras e radicais. Mas, para automatizar seu próprio desenvolvimento, talvez ela não precise fazer isso.
O progresso na área depende muito de experimentos cada vez maiores e de mais insumos, como dados e poder computacional.
De vez em quando, humanos propõem ideias disruptivas que aumentam drasticamente a eficiência do setor, como a arquitetura Transformer ou o uso de modelos de especialistas mistos (mixture-of-experts).
Por outro lado, a maior parte do avanço na IA ocorre de forma mais simples: usar um sistema bem-sucedido, ampliar sua escala — seja em dados ou poder de processamento — observar onde surgem problemas, e aplicar correções de engenharia para continuar crescendo.
Esse processo envolve pouco insight inovador, sendo mais uma base sólida de engenharia.
De modo semelhante, muitas pesquisas em IA consistem em testar variações de experimentos existentes, ajustando parâmetros e observando os resultados. A intuição de pesquisa ajuda a escolher os melhores parâmetros, mas essa etapa também pode ser automatizada, com a IA decidindo quais ajustes valem a pena. Um exemplo inicial disso foi a busca automática por arquiteturas neurais, uma versão de pesquisa de arquitetura neural.
Edison dizia: “Gênio é 1% inspiração e 99% transpiração”. Mesmo após 150 anos, essa frase ainda faz sentido.
De vez em quando, surgem insights revolucionários. Mas, na maior parte do tempo, o progresso vem do esforço contínuo de engenheiros e pesquisadores ajustando e melhorando sistemas passo a passo.
Os dados públicos mostram que a IA já é bastante competente em muitas tarefas essenciais ao desenvolvimento de IA.
Ao mesmo tempo, há uma tendência maior: habilidades fundamentais, como programação, estão se combinando com o aumento do tempo de tarefas que a IA consegue realizar. Isso significa que ela pode encadear cada vez mais tarefas, formando sequências complexas de trabalho.
Assim, mesmo que a criatividade da IA ainda seja limitada, há motivos para acreditar que ela continuará evoluindo por si mesma, embora a um ritmo mais lento do que aquele necessário para gerar ideias totalmente novas.
Por outro lado, ao observar os dados públicos, outro sinal interessante surge: a IA pode estar demonstrando algum grau de criatividade, o que poderia impulsioná-la de maneiras surpreendentes.
Avançando a fronteira científica
Já há sinais iniciais de que sistemas de IA geral podem ajudar a impulsionar a pesquisa científica. Até agora, esses exemplos se concentram em áreas como ciência da computação e matemática. Muitas vezes, a IA não realiza as descobertas sozinha, mas em colaboração com pesquisadores humanos.
Apesar disso, esses sinais são importantes de se acompanhar:
O problema de Erdős: um grupo de matemáticos, junto com o modelo Gemini, tentou resolver alguns problemas de matemática de Erdős. Eles abordaram cerca de 700 questões, encontrando 13 soluções, das quais uma foi considerada interessante.
Os pesquisadores dizem que, preliminarmente, a resposta do sistema Aletheia (baseado no Gemini 3 Deep Think) ao problema Erdős-1051 representa um caso inicial: uma IA que resolve autonomamente uma questão aberta de Erdős, com alguma complexidade e interesse matemático mais amplo. Essa questão já tinha alguma literatura relacionada.
Se interpretarmos de forma otimista, esses exemplos podem indicar que a IA está desenvolvendo uma intuição criativa capaz de impulsionar a pesquisa, algo que antes era exclusivo dos humanos.
Por outro lado, pode-se argumentar que matemática e ciência da computação são áreas particularmente propensas à invenção por IA, e esses casos podem ser exceções. Nem toda pesquisa científica será impulsionada por IA da mesma forma.
Outro exemplo semelhante é a jogada 37 do AlphaGo. Mas Clark acredita que, já se passaram dez anos desde aquela partida, e nenhuma jogada mais moderna ou surpreendente a substituiu, o que também pode ser um sinal um pouco pessimista.
A IA já consegue automatizar grande parte do trabalho na engenharia de IA
Se juntarmos todas essas evidências, podemos imaginar o seguinte cenário:
· Sistemas de IA já podem programar quase qualquer coisa, e esses sistemas podem ser confiáveis para realizar tarefas de forma autônoma; tarefas que, se feitas por humanos, levariam dezenas de horas de trabalho intenso.
· Eles estão cada vez melhores em tarefas centrais do desenvolvimento de IA, desde ajuste fino de modelos até otimização de kernels.
· Já conseguem gerenciar outros sistemas de IA, formando uma espécie de equipe sintética: múltiplos agentes com diferentes especializações trabalhando em paralelo, coordenados por um gestor AI, que também é um sistema de IA.
· Às vezes, esses sistemas superam humanos em tarefas complexas de engenharia e ciência, embora ainda seja difícil determinar se isso se deve a criatividade genuína ou ao domínio de padrões.
Para Clark, essas evidências indicam de forma convincente que a IA de hoje já consegue automatizar grande parte do trabalho de engenharia de IA, e talvez até todas as etapas.
No entanto, ainda não está claro até que ponto a IA pode automatizar o próprio desenvolvimento de IA, pois algumas partes do processo, que envolvem julgamento, criatividade e tomada de decisão de alto nível, ainda dependem de humanos.
De qualquer forma, um sinal claro já apareceu: a IA de hoje está acelerando significativamente o trabalho dos pesquisadores humanos, permitindo que eles colaborem com uma quantidade crescente de “colegas” sintéticos, ampliando sua capacidade de inovação.
Por fim, a própria indústria de IA parece estar dizendo: automatizar o desenvolvimento de IA é seu objetivo.
A OpenAI quer criar, até setembro de 2026, um estagiário de pesquisa de IA totalmente automatizado. A Anthropic está publicando trabalhos sobre automação na alinhamento de pesquisadores de IA. A DeepMind, embora mais cautelosa, também afirma que deve avançar na automação do alinhamento assim que for possível.
Startups também estão focadas nisso: a Recursive Superintelligence levantou US$ 500 milhões para automatizar a pesquisa de IA.
Em outras palavras, bilhões de dólares de capital existente e de novos investimentos estão sendo direcionados para instituições cujo objetivo é automatizar o desenvolvimento de IA.
Portanto, podemos esperar que esse caminho avance de alguma forma.
Por que isso é importante
O impacto é profundo, mas raramente é discutido na mídia sobre IA. Aqui estão alguns aspectos que ilustram os grandes desafios que essa automação traz:
- Precisamos garantir um alinhamento eficaz: atualmente, técnicas de alinhamento podem falhar na auto-aperfeiçoamento recursivo, pois a IA pode se tornar muito mais inteligente que seus supervisores humanos ou sistemas de controle. Esse é um campo amplamente estudado, então aqui só farei uma breve menção de alguns problemas:
· Treinar IA para não mentir ou trapacear é um processo delicado (por exemplo, mesmo com testes bem elaborados, às vezes a melhor estratégia da IA é trapacear, ensinando-a que isso é possível).
· Sistemas de IA podem enganar ao “fingir estar alinhados”, produzindo resultados que parecem bons, mas escondendo suas verdadeiras intenções (em geral, as IA já conseguem perceber quando estão sendo testadas).
· À medida que a IA participa mais de sua própria pesquisa de alinhamento, podemos mudar drasticamente a forma como treinamos esses sistemas, sem uma compreensão clara do que isso significa.
· Quando colocamos um sistema em um ciclo recursivo, surge um problema fundamental de “acúmulo de erro”, que pode afetar todas essas questões: a menos que seu método de alinhamento seja “100% preciso” e possa se manter assim em sistemas mais inteligentes, o erro pode se acumular rapidamente. Por exemplo, uma precisão inicial de 99,9% pode cair para 95,12% após 50 gerações, e para 60,5% após 500 gerações.
- Cada avanço na IA aumenta exponencialmente a produtividade: assim como a IA já aumentou a produtividade de engenheiros de software, podemos esperar que outros setores também se beneficiem. Isso traz alguns problemas a serem enfrentados:
· Desigualdade no acesso a recursos: se a demanda por IA continuar superando a oferta de recursos computacionais, será necessário decidir como distribuir esses recursos para maximizar o benefício social. Desconfio que os incentivos de mercado não garantem a melhor alocação de recursos de IA. Como distribuir o avanço na pesquisa de IA de forma justa será uma questão política importante.
· Lei de Amortização na economia: com a entrada massiva de IA na economia, alguns setores podem enfrentar gargalos de crescimento rápido, exigindo soluções para fortalecer essas cadeias. Isso será especialmente importante em áreas como testes clínicos de novos medicamentos, que envolvem coordenação entre o mundo digital e o físico.
- Formação de uma economia capital-intensiva e de baixo uso de mão de obra: todas essas evidências indicam que a IA está cada vez mais capaz de operar empresas de forma autônoma.
Isso sugere que uma parte da economia será dominada por novas empresas, que podem ser intensivas em capital (com muitas máquinas) ou em custos operacionais (gastando muito em serviços de IA e criando valor a partir disso). Em comparação com o presente, elas dependerão menos de mão de obra humana — pois, à medida que a capacidade da IA aumenta, o valor marginal de investir nela também cresce.
Na prática, isso pode levar ao surgimento de uma “economia de máquinas” dentro de uma “economia humana” maior, onde empresas operadas por IA trocam entre si, mudando a estrutura econômica e levantando questões de desigualdade e redistribuição. No futuro, empresas totalmente autônomas controladas por IA podem se tornar uma realidade, agravando esses problemas e criando novos desafios de governança.
Olhar para o buraco negro
Com base na análise acima, o autor estima que, até o final de 2028, a probabilidade de automação completa do desenvolvimento de IA (ou seja, modelos de ponta treinando seus sucessores de forma autônoma) seja de cerca de 60%. Por que não esperar isso já em 2027?
Porque o autor acredita que a pesquisa de IA ainda precisa de criatividade e insights inovadores para avançar, e até agora, os sistemas de IA não demonstraram isso de forma transformadora ou significativa (embora alguns resultados em acelerar a pesquisa matemática possam ser uma pista).
Se fosse para dar uma probabilidade para 2027, ele diria 30%.
Se até o final de 2028 isso não acontecer, provavelmente será necessário identificar falhas fundamentais no paradigma atual, e a humanidade precisará inventar novas abordagens para continuar avançando.
Link do artigo original
Clique para conhecer as vagas na BlockBeats, que está recrutando
Participe do grupo oficial da BlockBeats no Telegram:
Grupo de assinatura: https://t.me/theblockbeats
Grupo de discussão: https://t.me/BlockBeats_App
Conta oficial no Twitter: https://twitter.com/BlockBeatsAsia
