El desafío de la pila de datos blockchain moderna
Una startup moderna de indexación blockchain se enfrenta a varios desafíos, entre ellos:
- Volumen masivo de datos. A medida que crece la cantidad de datos en la cadena, el índice debe escalar para gestionar la mayor carga y garantizar un acceso eficiente. Esto implica mayores costes de almacenamiento, cálculos de métricas más lentos y una mayor carga sobre el servidor de bases de datos.
- Canal de procesamiento de datos complejo. La tecnología blockchain es compleja y construir un índice de datos integral y fiable requiere comprender en profundidad las estructuras de datos y algoritmos subyacentes. Esta complejidad se acentúa por la diversidad de implementaciones blockchain. Por ejemplo, los NFT en Ethereum suelen crearse en contratos inteligentes bajo los estándares ERC721 y ERC1155, mientras que en Polkadot, por ejemplo, se implementan directamente en el runtime de la cadena. Finalmente, todos deben considerarse NFT y almacenarse como tales.
- Capacidades de integración. Para aportar el máximo valor al usuario, una solución de indexación blockchain puede requerir integrar su índice de datos con otros sistemas, como plataformas analíticas o APIs. Esto es complejo y exige un esfuerzo importante en el diseño arquitectónico.
Con la expansión del uso de la tecnología blockchain, la cantidad de datos almacenados en la cadena ha crecido. Esto se debe a que más personas utilizan la tecnología y cada transacción añade nuevos datos. Además, el uso de blockchain ha evolucionado desde aplicaciones sencillas de transferencia de dinero (como Bitcoin) hacia aplicaciones más complejas que implementan lógica de negocio en contratos inteligentes. Estos contratos pueden generar grandes volúmenes de datos, lo que ha incrementado la complejidad y el tamaño de la cadena. Con el tiempo, esto ha desembocado en blockchains más grandes y complejas.
En este artículo, analizamos la evolución de la arquitectura tecnológica de Footprint Analytics por etapas como caso de estudio para explorar cómo la pila tecnológica Iceberg-Trino aborda los desafíos del dato on-chain.
Footprint Analytics ha indexado datos de aproximadamente 22 blockchains públicas, 17 marketplaces NFT, 1900 proyectos GameFi y más de 100 000 colecciones NFT en una capa de abstracción semántica. Es la solución de data warehouse blockchain más completa del mundo.
Los datos blockchain, que incluyen más de 20 000 millones de registros de transacciones financieras y que son consultados frecuentemente por analistas de datos, presentan diferencias notables respecto a los registros de ingreso en los data warehouses tradicionales.
En los últimos meses hemos realizado tres actualizaciones clave para responder a las crecientes necesidades del negocio:
Arquitectura 1.0 Bigquery
En los inicios de Footprint Analytics, utilizamos Google Bigquery como motor de almacenamiento y consulta. Bigquery es un producto excelente: extremadamente rápido, fácil de usar, ofrece potencia aritmética dinámica y una sintaxis UDF flexible que nos permite completar tareas con agilidad.
No obstante, Bigquery presenta varias limitaciones.
- Los datos no se comprimen, lo que implica altos costes de almacenamiento, especialmente al gestionar datos en bruto de más de 22 blockchains en Footprint Analytics.
- Concurrencia insuficiente: solo permite 100 consultas simultáneas, insuficiente para escenarios de alta concurrencia en Footprint Analytics, donde se atiende a numerosos analistas y usuarios.
- Dependencia de Google Bigquery, un producto de código cerrado.
Por ello, decidimos explorar otras arquitecturas alternativas.
Arquitectura 2.0 OLAP
Nos interesamos por varios productos OLAP que han ganado popularidad. Su principal ventaja es el tiempo de respuesta a las consultas, que suele ser de fracciones de segundo para grandes volúmenes de datos, y la capacidad de soportar miles de consultas concurrentes.
Probamos una de las mejores bases de datos OLAP, Doris, que ofrece buen rendimiento. Sin embargo, pronto surgieron otros problemas:
- Tipos de datos como Array o JSON no estaban soportados (noviembre de 2022). Los arrays son habituales en algunas blockchains, por ejemplo el campo topic en los logs EVM. No poder calcular sobre arrays limita el cálculo de muchas métricas de negocio.
- Soporte limitado para DBT y sentencias merge. Estas son necesidades habituales para ingenieros de datos en escenarios ETL/ELT, donde es necesario actualizar datos recién indexados.
Por tanto, no pudimos usar Doris para toda la canalización de datos en producción, así que lo empleamos como base de datos OLAP para resolver parte del problema en la producción, actuando como motor de consultas y proporcionando alta concurrencia y velocidad.
No obstante, no fue posible sustituir Bigquery por Doris, por lo que tuvimos que sincronizar periódicamente los datos de Bigquery a Doris solo como motor de consultas. Este proceso presentaba varios problemas, entre ellos que las escrituras de actualización se acumulaban rápidamente cuando el motor OLAP estaba ocupado atendiendo consultas de clientes front-end. Esto ralentizaba el proceso de escritura y, en ocasiones, la sincronización no llegaba a completarse.
Concluimos que OLAP podía resolver varios problemas, pero no era la solución definitiva para Footprint Analytics, especialmente en la canalización de procesamiento de datos. Nuestro reto es mayor y más complejo, y OLAP como motor de consultas no era suficiente.
Arquitectura 3.0 Iceberg + Trino
Bienvenidos a la arquitectura 3.0 de Footprint Analytics: una renovación total de la arquitectura base. Rediseñamos todo desde cero, separando almacenamiento, cómputo y consulta de datos en tres componentes diferenciados. Aprendimos de las arquitecturas anteriores y de la experiencia de grandes proyectos de big data como Uber, Netflix y Databricks.
Introducción al data lake
Nos centramos en el data lake, un nuevo modelo de almacenamiento para datos estructurados y no estructurados. Es ideal para datos on-chain, cuyos formatos van desde datos en bruto no estructurados hasta datos abstractos estructurados, por los que Footprint Analytics destaca. Nuestra expectativa era que el data lake resolviera el almacenamiento y soportara motores de cómputo como Spark y Flink, facilitando la integración con distintos motores a medida que Footprint Analytics evoluciona.
Iceberg se integra perfectamente con Spark, Flink, Trino y otros motores, permitiéndonos escoger el cómputo más adecuado para cada métrica. Por ejemplo:
- Para cálculos complejos, usamos Spark.
- Flink para procesamiento en tiempo real.
- Para tareas ETL sencillas con SQL, utilizamos Trino.
Motor de consultas
Con Iceberg resolviendo almacenamiento y cómputo, el siguiente paso fue elegir el motor de consultas. Las opciones eran limitadas, y consideramos:
- Trino: motor de consultas SQL
- Presto: motor de consultas SQL
- Kyuubi: Spark SQL sin servidor
El aspecto clave antes de profundizar era que el motor de consultas futuro debía ser compatible con nuestra arquitectura actual.
- Soportar Bigquery como fuente de datos
- Soportar DBT, esencial para la generación de muchas métricas
- Soportar la herramienta BI Metabase
Por todo ello, elegimos Trino, que ofrece un soporte excelente para Iceberg y cuyo equipo respondió con tal rapidez que, tras reportar un bug, lo solucionaron al día siguiente y lo lanzaron en la versión más reciente la semana siguiente. Sin duda, la mejor elección para el equipo de Footprint, que requiere alta capacidad de respuesta en la implementación.
Pruebas de rendimiento
Una vez definida la estrategia, realizamos pruebas de rendimiento con la combinación Trino + Iceberg para comprobar si respondía a nuestras necesidades y, para nuestra sorpresa, las consultas fueron increíblemente rápidas.
Sabiendo que Presto + Hive ha sido durante años el peor comparador en todo el entorno OLAP, la combinación Trino + Iceberg superó todas nuestras expectativas.
Estos son los resultados de nuestras pruebas.
caso 1: join de grandes conjuntos de datos
Una tabla1 de 800 GB se une a otra tabla2 de 50 GB y ejecuta cálculos de negocio complejos
caso 2: consulta distinct sobre una gran tabla
SQL de prueba: select distinct(address) from table group by day

La combinación Trino+Iceberg es aproximadamente tres veces más rápida que Doris en la misma configuración.
Además, Iceberg permite utilizar formatos de datos como Parquet, ORC, etc., que comprimen y almacenan los datos. El almacenamiento de tablas en Iceberg ocupa solo alrededor de una quinta parte del espacio de otros data warehouses. El tamaño de almacenamiento de la misma tabla en las tres bases de datos es el siguiente:

Nota: Las pruebas presentadas son ejemplos reales de producción y se ofrecen solo como referencia.
・Efecto de la actualización
Los informes de pruebas de rendimiento nos dieron la confianza suficiente y el equipo tardó aproximadamente dos meses en completar la migración. Este es el diagrama de nuestra arquitectura tras la actualización.
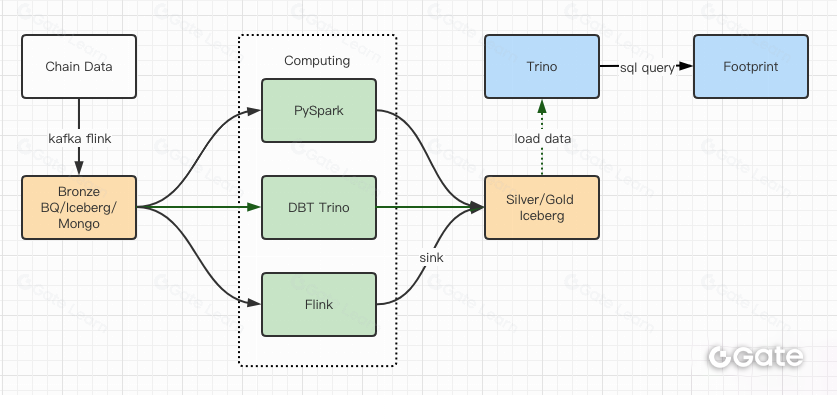
- Varios motores de cómputo se adaptan a nuestras distintas necesidades.
- Trino soporta DBT y permite consultar Iceberg directamente, eliminando la necesidad de sincronizar datos.
- El rendimiento de Trino + Iceberg nos permite abrir todos los datos Bronze (datos en bruto) a nuestros usuarios.
Resumen
Desde su lanzamiento en agosto de 2021, el equipo de Footprint Analytics ha realizado tres actualizaciones arquitectónicas en menos de un año y medio, gracias a su determinación por ofrecer la mejor tecnología de bases de datos a sus usuarios cripto y a la sólida ejecución en la implementación y mejora de su infraestructura y arquitectura.
La actualización arquitectónica 3.0 de Footprint Analytics ha brindado una nueva experiencia a sus usuarios, permitiendo a perfiles diversos obtener insights en usos y aplicaciones más variados:
- Integrado con la herramienta BI Metabase, Footprint permite a los analistas acceder a datos on-chain decodificados, explorar con total libertad de herramientas (no-code o hardcode), consultar todo el historial, cruzar datasets y obtener insights de forma inmediata.
- Integración de datos on-chain y off-chain para análisis en web2 + web3;
- Al construir o consultar métricas sobre la abstracción de negocio de Footprint, analistas y desarrolladores ahorran tiempo en el 80 % del procesamiento de datos repetitivo y pueden centrarse en métricas relevantes, investigación y soluciones de producto para su negocio.
- Experiencia fluida desde Footprint Web hasta llamadas REST API, todo basado en SQL
- Alertas en tiempo real y notificaciones accionables sobre señales clave para apoyar decisiones de inversión






