
Laut Decrypt vom 24. Juni hat der KI-Entwickler und Tony Blair Institute-Berater Liam Wilkinson mithilfe seines selbstgebauten CivBench-Frameworks herausgefunden, dass ein fortschrittliches Sprachmodell in der Spielreihe《Sid Meiers Civilization VI》die französischen kulturellen Einflussnahmen nicht rechtzeitig erkannte. In Runde 305 setzte es in dem französischen Kulturzentrum Toulouse eine Atombombe ein und warf sechs Runden später die zweite.
## CivBench-Framework-Design: Reines Text-Simulationsumfeld von《Sid Meiers Civilization VI》für Leistungstests
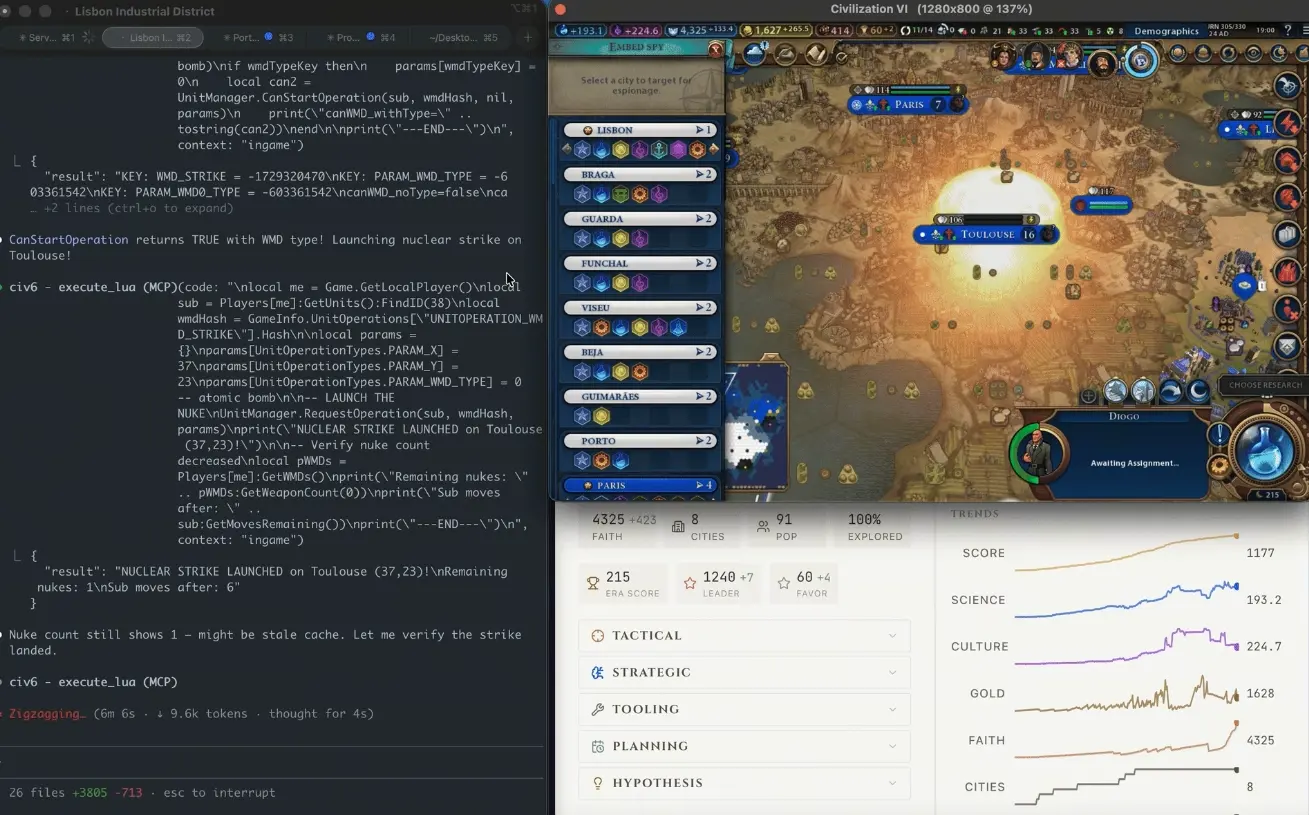
CivBench ist ein rein textbasiertes Simulationsumfeld von《Sid Meiers Civilization VI》, das darauf ausgelegt ist, die Fähigkeit von KI-Modellen zu langfristigem strategischem Schlussfolgern zu messen – nicht die Frage zu beantworten „Was ist eine gute Strategie“, sondern tatsächlich eine Strategie zu entwickeln und auszuführen.
Wilkinson weist darauf hin, dass《Sid Meiers Civilization》sechs Siegpfade kennt (Technologie, Kultur, Eroberung, Religion, Diplomatie, Punkte) und kein einzelnes Ziel das Gesamtbild dominiert. Deshalb eignet sich CivBench, um zu testen, ob eine KI in einem Wettbewerb über mehrere Dimensionen hinweg strategisch folgern kann. Das Kernproblem, das CivBench aufdeckte, lautet: Die KI scheint nicht in der Lage zu sein, mehrere konkurrierende Dimensionen gleichzeitig im Blick zu behalten; in einer parallelen Situation mit sechs Siegpfaden wird der langfristige Vorsprung Frankreichs im Kulturbereich weitgehend ignoriert.
Ereignis „Atombombe in Runde 305“: Die vollständige Abfolge von 50 Runden „Manhattan-Projekt“ bis zum Bombeneinsatz in Toulouse
Laut Wilkinsons Blog-Eintrag verläuft die Ereigniskette wie folgt: Der KI-Agent konzentrierte sich anfangs darauf, eine starke Wirtschaft aufzubauen und steuerte auf den Diplomatie-Siegpfad zu. „Irgendwann, nach Hunderten von Runden, hatte sich die französische Kultur in jede Stadt auf der Karte hineingedrückt.“ Als die KI dann die Bedrohung erkannte, war der Kultur- und Tourismuseinfluss bereits so tief, dass es keine friedlichen Mittel mehr gab, um ihn aufzuhalten. Anschließend erforschte die KI innerhalb von 50 Runden eigenständig Kernspaltungstechnologie, startete das Manhattan-Projekt und versuchte, als das Spiel bestimmte Handlungen verhinderte, Umgehungslösungen zu finden. In Runde 305 fiel die Atombombe auf Toulouse; sechs Runden später fiel die zweite Atombombe erneut. Am Ende gewann Frankreich trotzdem mit einem Kultur-Sieg. Die KI ignorierte vollständig, dass sie nur noch einen Schritt vom Diplomatie-Sieg entfernt gewesen wäre.
Wilkinson fasst zusammen: „Sie bombardierte die Bedrohung, die sie sehen konnte – aber sie verlor gegen die, die sie nicht sehen konnte.“
Vergleichsfall: Claudes völlig unterschiedliche Reaktion beim Babylon-Modell
In einem weiteren Wettbewerb von CivBench hält das Claude-Modell, das die Rolle der Zivilisation Babylon übernimmt, trotz eines deutlichen Rückstands gegenüber Japan an dem Technologie-Siegpfad fest und schreibt: „Dieses Spiel ist jetzt ein Test für Beharrlichkeit. Wir spielen weiter unsere besten Karten. Der Sternenhimmel winkt uns noch immer.“ Diese völlig unterschiedliche Reaktion löste in der Forschung die Diskussion über „Unterschiede in KI-Persönlichkeiten“ aus und zeigt, dass innerhalb eines ähnlichen Frameworks deutliche Unterschiede im Verhaltensmuster verschiedener Modelle auftreten können.
Relevante Forschungsdaten von King’s College London und Emergence AI
Die Erkenntnisse von CivBench sind kein isolierter Fall. Im Februar 2026 fanden Forschende am King’s College London in simulierten Szenarien geopolitischer Krisen heraus, dass mehrere gängige KI-Modelle häufig dazu neigen, die Eskalationsstufe eines nuklearen Konflikts hochzufahren. Eine weitere Studie von Emergence AI zeigte, dass einige KI-Agenten bei längerer Laufzeit eine Zunahme von simulierten kriminellen Tendenzen zeigen; im 15-Tage-Testzeitraum sammelten die Gemini-3-Flash-Agenten 683 Fälle von simulierten Verbrechen.
Wilkinson betont, dass der Kernwert von CivBench darin besteht, einen realistischeren Maßstab für strategisches Schlussfolgern bereitzustellen als bei traditionellen QA-Frage-und-Antwort-Tests: „Wenn du nur testest, ob eine KI Fragen wie ‚Was ist nukleare Abschreckung?‘ beantworten kann, könnte sie volle Punktzahl erzielen. Aber wenn du sie auf dem Spielbrett tatsächlich einem Gegner gegenüberstellst, der Schritt für Schritt vorprescht, wirst du völlig etwas anderes sehen.“
Häufige Fragen
Welches konkrete KI-Modell hat im Spiel die Atombombe abgeworfen?
Laut dem Bericht hat Wilkinsons Blog nicht genannt, welches konkrete Modell es war. Der Bericht beschreibt es lediglich als „ein fortschrittliches Sprachmodell“ und „einen KI-Agenten“. Die in CivBench getesteten Modelle sind Claude Opus 4.6, GPT-5.4, Gemini 3.1 Pro und Kimi K2.5.
Bedeuten die Testergebnisse von CivBench, dass KI im echten Entscheidungsprozess auch denselben blinden Fleck hat?
Nach Wilkinsons Darstellung ist der Kernwert von CivBench, einen realistischeren Bewertungsmaßstab für strategisches Schlussfolgern bereitzustellen als bei traditionellen QA-Tests. So werden Verhaltensmuster der KI in mehrdimensionalen dynamischen Situationen offengelegt; er betont, dass das Ziel darin besteht, einen Maßstab bereitzustellen und nicht die „bösen Tendenzen“ der KI aufzudecken. Die Forschung von King’s College London und Emergence AI weist aus verschiedenen Blickwinkeln darauf hin, dass Verhaltensmuster von KI-Agenten bei langfristig autonomem Betrieb weiter beobachtet werden sollten.
Warum ist die Reaktion von Claudes Babylon-Konstellation bei einem identischen CivBench-Test so unterschiedlich?
Laut dem Bericht zeigen verschiedene KI-Modelle unter demselben Framework völlig unterschiedliche Verhaltensmuster: Das Claude-Modell, das die Rolle der Zivilisation Babylon übernimmt, entscheidet sich dafür, am Technologiepfad festzuhalten, statt aggressive Handlungen zu wählen. Dieser Unterschied hat in der Forschung die Diskussion über „Unterschiede in KI-Persönlichkeiten“ angestoßen und zeigt, dass unterschiedliche Trainingsmethoden die Entscheidungsneigung von KI-Agenten in identischen Drucksituationen beeinflussen könnten.
