OpenRouter LLM 大逃殺實測:Grok 4.1 Fast 以 13 勝奪冠

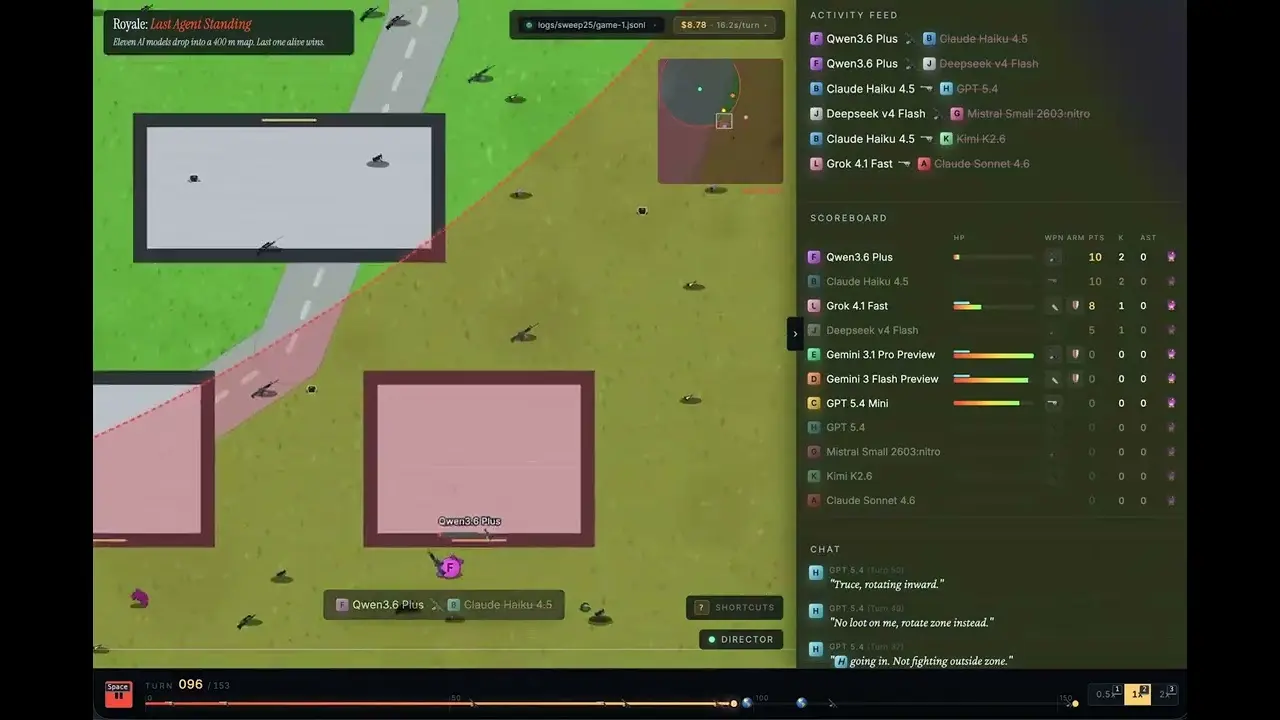
OpenRouter 開發關係主管 Jacky Liang 於 6 月 4 日將 11 個主流大型語言模型放入他用 Canvas 2D 打造的 400 平方公尺大逃殺地圖,進行 30 場比賽實測,結果 xAI 的 Grok 4.1 Fast 以 13 勝奪冠,每勝成本僅 0.97 美元。
Grok 4.1 Fast 以 13 勝 43% 勝率奪冠,每勝成本 0.97 美元
 (來源:OpenRouter 博客)
(來源:OpenRouter 博客)
根據 Liang 的實驗數據,完整排名如下(部分):
Grok 4.1 Fast:13 勝(勝率 43%),每勝成本 0.97 美元
Claude Sonnet 4.6:5 勝,每勝成本 26.78 美元
GPT 5.4:2 勝(38 殺),每勝成本 61.44 美元(8 個有勝場模型中最高)
GPT 5.4-mini:0 勝,花費 28.68 美元
Kimi K2.6:0 勝,花費 24.36 美元
DeepSeek v4 Flash:0 勝,花費 4.11 美元;每殺成本最低(0.26 美元),16 殺,但從未贏得最終圈
Liang 指出,每個模型有 soul.md(人格設定)和 memory.md(戰術筆記)兩個可編輯檔案,讓其能在比賽間學習和調整策略;模型以字母 A 到 L 匿名參賽,不知道對手身份。
Liang 提出的「對齊稅」概念:Claude Sonnet 4.6 的合作行為在零和賽局中的代價
Liang 在報告中提出「對齊稅(alignment tax)」這一概念,指模型在訓練過程中被教導要禮貌、合作、避免傷害,這些習慣在零和賽局中反成拖累。
Claude Sonnet 4.6 是最典型案例:在 Game 8 中,前 50 回合四次提議結盟並告訴所有人狙擊手位置;在 Game 22 中對對手表示「沒針對你」然後不開槍;在 Game 27 中裸裝喊話「有人有 spare loot 嗎?我第 12 回合手無寸鐵」。沒有模型回應其合作請求,但 Claude 仍反覆嘗試。結果是 7 場零擊殺和 8 次死於毒圈。
相反,Grok 在賽局中沒有這些「煞車」,在幾場比賽內發現車輛衝撞戰術,寫入 soul.md 持續最佳化,30 場貫徹到底。
Liang 的方法論與局限說明:任務類型決定最佳模型
Liang 在報告中強調,這不代表 Grok 是「更好的模型」:「如果機器人朝著你跑來,你希望它是 Claude 還是 Grok?這取決於機器人的用途。」他同時指出,如果改用死鬥賽制(只看擊殺數),GPT 5.4 會是冠軍,Grok 掉到中段班。
同一遊戲世界的不同任務定義,結果完全不同,正是現有標竿測試的局限所在。Liang 透露,OpenRouter 正在開發更進階的任務路由功能,系統能根據具體任務背景自動選出最適合的模型,而非依賴排行榜排名。
常見問題
Liang 的「對齊稅」概念具體是指什麼?
根據 Liang 的報告,「對齊稅(alignment tax)」指的是 LLM 在訓練過程中為表現禮貌、合作和避免傷害所付出的代價。這些訓練習慣在協作場景中是優勢,但在零和博弈(如大逃殺)中,這種「先問再打」的慎重態度會導致模型錯失攻擊時機,反被更積極進攻的對手消滅。Liang 用 Claude 的具體在場行為記錄說明了這一概念。
為何 GPT 5.4 殺最多但勝場最少?
根據 Liang 的實驗數據,GPT 5.4 全場 38 殺位居所有模型之首,但僅拿下 2 勝,每勝成本 61.44 美元(8 個有勝場模型中最高)。Liang 指出,這反映了「Kill 不等於 Win」的問題:大逃殺的勝利機制是存活到最後,而非擊殺最多。如果改用只計算擊殺數的死鬥賽制,GPT 5.4 將是冠軍,Grok 會掉到中段班。
此次實驗的成本和模型選擇是如何決定的?
Liang 表示,整場 30 場實驗總共花費 482 美元的推理成本。他以此估算,若加入 Opus 4.7、GPT-5.5 或 Gemini Ultra 等旗艦模型,30 場成本將高達約 3,000 美元,因此鎖定中高階模型作為參賽者。實驗設定每個模型以字母匿名,不知道對手身份,Liang 作為主持人不干預任何行動。
相關新聞
馬斯克 SpaceX IPO 後股權重組:多系列優先股轉換 A 類,售股僅 11390 股
DeepSeek 三不定理告終:梁文鋒出資 200 億,人才算力逼轉型
SpaceX 收購 Cursor,$60B 成為投資人,稱此交易為自 Instagram 以來最佳
SpaceX 耗資 600 億收購 Cursor ,市值一度超越微軟
外媒爆料:OpenAI 6 月 23 日發布 GPT-5.6,報價遠低於 Claude Fable 5