Dữ liệu on-chain là gì?
Dữ liệu on-chain là dữ liệu được ghi nhận trên blockchain. Vì blockchain là một cơ sở dữ liệu phân tán, dữ liệu on-chain được công khai và bất kỳ ai cũng có thể truy cập.
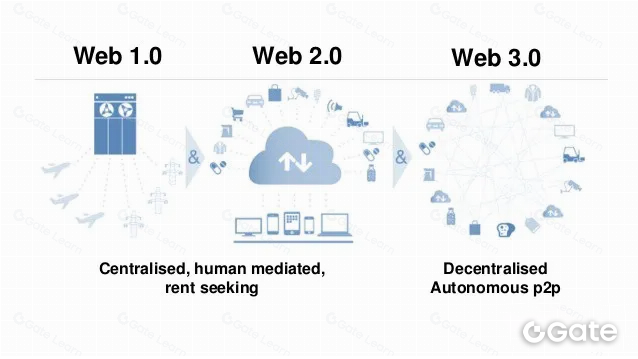
Web3 và web2 là các phiên bản khác nhau của World Wide Web, trong đó web3 là phiên bản mới nhất và tiên tiến nhất. Một số điểm khác biệt chính giữa hai phiên bản này như sau:
Web3 là phi tập trung, còn web2 là tập trung. Nghĩa là, ở web3, dữ liệu và dịch vụ do một mạng lưới các node phân tán cung cấp, thay vì chỉ một thực thể duy nhất. Điều này giúp web3 có khả năng chống chịu tốt hơn, ít bị kiểm duyệt hoặc gián đoạn hơn, nhưng đồng thời cũng phức tạp hơn và khó kiểm soát hơn.
Web3 được xây dựng trên nền tảng công nghệ blockchain, còn web2 dựa trên kiến trúc máy khách-máy chủ truyền thống. Ở web3, dữ liệu được lưu trữ và truyền tải bằng các thuật toán mã hóa, thay vì lưu trữ và truyền tải qua máy chủ trung tâm. Điều này giúp web3 an toàn và minh bạch hơn, nhưng cũng chậm hơn và tốn kém hơn.
Web3 tập trung vào việc tạo ra các loại ứng dụng và dịch vụ mới, còn web2 tập trung vào cải tiến các ứng dụng và dịch vụ hiện có. Vì vậy, web3 mang tính thử nghiệm và hướng tới tương lai, trong khi web2 đã ổn định và trưởng thành.
Những khác biệt này ảnh hưởng đến cách dữ liệu được phân tích trong từng môi trường. Ở web3, phân tích dữ liệu tập trung vào việc hiểu hành vi của mạng phi tập trung và công nghệ blockchain nền tảng, thường sử dụng các kỹ thuật tiên tiến như học máy và phân tích mạng để nhận diện khuôn mẫu và xu hướng trong dữ liệu. Ở web2, phân tích dữ liệu tập trung vào hành vi người dùng và các ứng dụng họ sử dụng, thường dùng các kỹ thuật truyền thống như phân tích thống kê và trực quan hóa dữ liệu để phát hiện xu hướng và thông tin chi tiết.
Để phân tích dữ liệu on-chain, bạn cần thu thập và tổ chức dữ liệu liên quan, sau đó sử dụng các công cụ và kỹ thuật như trực quan hóa dữ liệu và phân tích thống kê để nhận diện khuôn mẫu và xu hướng. Việc này giúp bạn hiểu rõ hơn về hành vi mạng blockchain và người dùng, cũng như dự đoán xu hướng thị trường. Trong một số trường hợp, bạn cũng có thể sử dụng các kỹ thuật học máy để tự động hóa phân tích và phát hiện các khuôn mẫu phức tạp hơn trong dữ liệu.
Các loại dữ liệu on-chain
Có hai loại dữ liệu on-chain:
Dữ liệu thô
Dữ liệu trừu tượng hóa
Việc phân biệt các loại dữ liệu này là do thực tế, mọi chỉ số tính toán đều là các dạng trừu tượng hóa dựa trên dữ liệu thô. Dữ liệu thô on-chain là dữ liệu chưa qua xử lý được ghi nhận trên blockchain, bao gồm thông tin về từng giao dịch như người gửi, người nhận và số lượng tiền điện tử chuyển giao. Ngược lại, dữ liệu kinh tế được suy ra từ dữ liệu thô và bao gồm thông tin về cung cầu của một loại tiền điện tử, cũng như vốn hóa thị trường và khối lượng giao dịch.
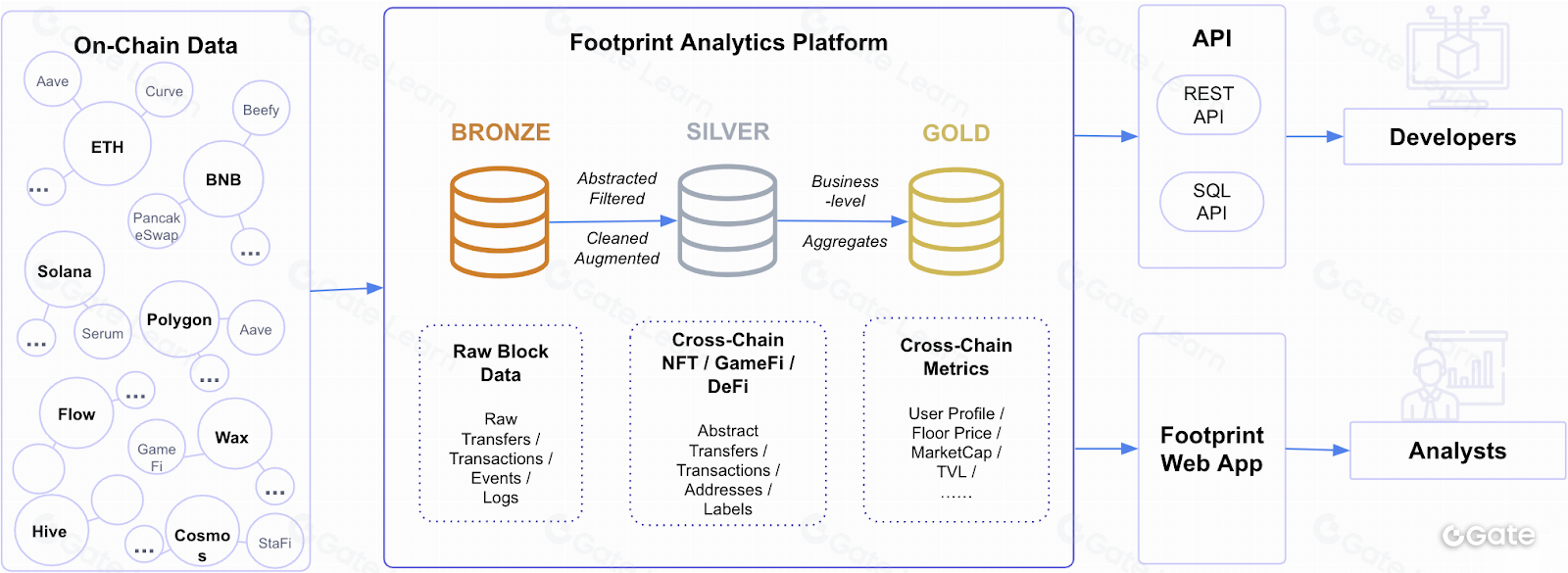
Dữ liệu kinh tế không chỉ là trừu tượng hóa từ dữ liệu thô mà còn được tính toán bằng nhiều kỹ thuật và chỉ số khác nhau. Ví dụ, vốn hóa thị trường được tính bằng tổng nguồn cung của một loại tiền điện tử nhân với giá hiện tại, còn khối lượng giao dịch được tính bằng tổng số giao dịch trong một khoảng thời gian nhất định. Các chỉ số khác như tốc độ lưu chuyển tiền tệ và tỷ lệ giá trị mạng lưới trên giá trị giao dịch có thể được tính bằng các công thức phức tạp hơn, xét đến nhiều yếu tố như số lượng giao dịch và tổng hoạt động mạng lưới.
Tổng thể, dữ liệu kinh tế cung cấp góc nhìn tổng quan hơn về thị trường tiền điện tử và hữu ích để nhận diện xu hướng thị trường cũng như đưa ra quyết định đầu tư. Tuy nhiên, cần lưu ý dữ liệu kinh tế không phải lúc nào cũng phản ánh chính xác hoặc đầy đủ thị trường nền tảng, nên phải sử dụng thận trọng.
Các giải pháp phân tích khác nhau
Tập trung và phi tập trung
Có nhiều giải pháp lập chỉ mục dữ liệu on-chain khác nhau, gồm cả tập trung và phi tập trung. Giải pháp tập trung thường do một thực thể duy nhất thu thập và tổ chức dữ liệu, còn giải pháp phi tập trung sử dụng mạng lưới các node phân tán để lập chỉ mục. Một số ví dụ là block explorer, cho phép người dùng tìm kiếm và duyệt blockchain, và các dịch vụ lập chỉ mục cung cấp API cùng công cụ cho nhà phát triển truy cập, phân tích dữ liệu on-chain.
Có thể xây dựng giải pháp phân tích phi tập trung dựa trên công nghệ blockchain, nhưng điều này phụ thuộc vào yêu cầu và ràng buộc cụ thể của hệ thống. Lợi ích của phương pháp phi tập trung là đảm bảo tính toàn vẹn và bảo mật cho dữ liệu phân tích. Tuy nhiên, hệ thống phi tập trung cũng phức tạp hơn trong thiết kế và triển khai, đồng thời đòi hỏi nhiều tài nguyên tính toán và lưu trữ hơn. Về hiệu suất, hệ thống phi tập trung có thể chậm hơn giải pháp tập trung trong một số trường hợp, tùy thuộc vào thuật toán, cấu trúc dữ liệu và thiết kế tổng thể. Cuối cùng, việc lựa chọn giải pháp phi tập trung hay không sẽ dựa trên nhu cầu và mục tiêu của giải pháp phân tích.
Có thể làm gì với dữ liệu blockchain?
Có nhiều phương pháp khác nhau có thể áp dụng khi phân tích dữ liệu on-chain. Một số ví dụ phổ biến gồm:
Phân tích mô tả
Phân tích mô tả là việc tóm tắt, mô tả dữ liệu, có thể bao gồm tính toán thống kê cơ bản và tạo biểu đồ trực quan. Phân tích này giúp có cái nhìn tổng thể về dữ liệu, nhận diện xu hướng và khuôn mẫu.
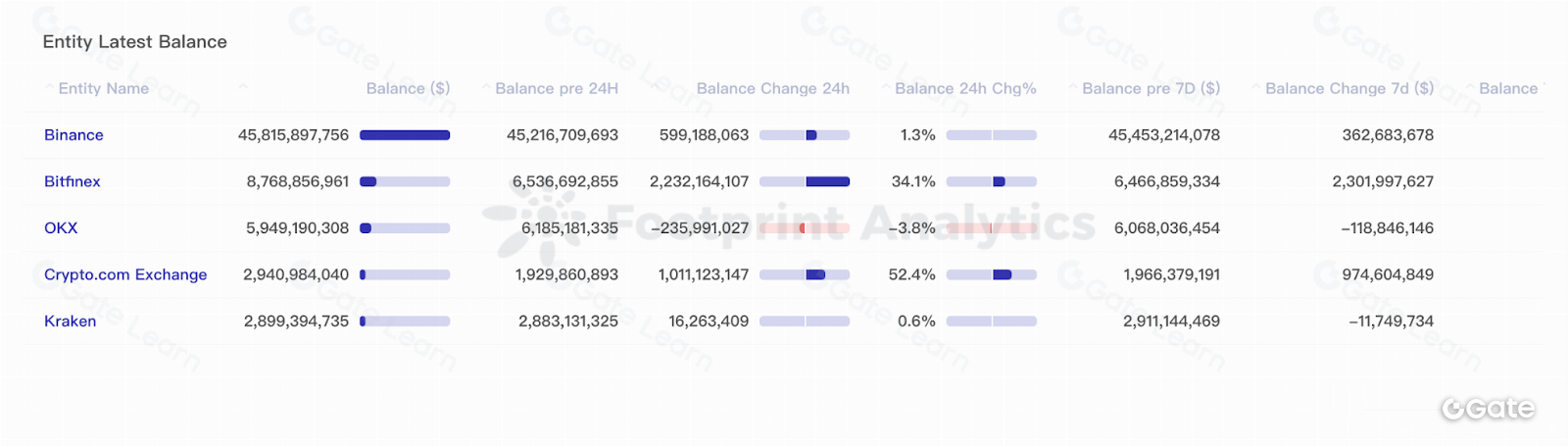
Phân tích khám phá
Phân tích khám phá là việc tìm hiểu sâu hơn dữ liệu, có thể gồm các kỹ thuật như phân cụm, giảm chiều dữ liệu. Loại phân tích này hữu ích để phát hiện các khuôn mẫu và mối quan hệ ẩn, đồng thời tạo ra giả thuyết và ý tưởng cho nghiên cứu tiếp theo.
Phân tích suy luận
Phân tích suy luận sử dụng các kỹ thuật thống kê để đưa ra suy luận về tổng thể dựa trên một mẫu dữ liệu. Thường áp dụng các phương pháp như tính trung bình, trung vị, mode, độ lệch chuẩn, kiểm định giả thuyết và phân tích hồi quy. Phân tích này hữu ích để dự đoán, tổng quát hóa dữ liệu và phát hiện xu hướng, khuôn mẫu không dễ nhận biết ngay lập tức.

Phân tích dự đoán
Phân tích dự đoán sử dụng các thuật toán học máy để dự đoán sự kiện hoặc kết quả tương lai dựa trên dữ liệu. Phân tích này dùng để nhận diện xu hướng, khuôn mẫu trong dữ liệu, đưa ra dự báo hoặc khuyến nghị. Thường áp dụng các kỹ thuật như phân cụm, phân loại, hồi quy để phát hiện khuôn mẫu, mối quan hệ trong dữ liệu.
Phương pháp cụ thể để phân tích dữ liệu on-chain sẽ tùy thuộc vào mục tiêu, yêu cầu phân tích và bản chất dữ liệu.
Trực quan hóa dữ liệu là một công cụ phân tích phổ biến, dùng để biểu diễn dữ liệu phức tạp dưới dạng trực quan như biểu đồ, đồ thị, bản đồ, giúp xác định xu hướng, khuôn mẫu. Ví dụ, biểu đồ đường thể hiện xu hướng giá tiền điện tử theo thời gian, biểu đồ cột so sánh vốn hóa thị trường các loại tiền điện tử. Công cụ trực quan hóa cũng có thể tạo biểu đồ tương tác, cho phép người dùng khám phá và tương tác với dữ liệu theo thời gian thực, giúp phát hiện các mối quan hệ, khuôn mẫu không dễ nhận biết khi xem dữ liệu thô.
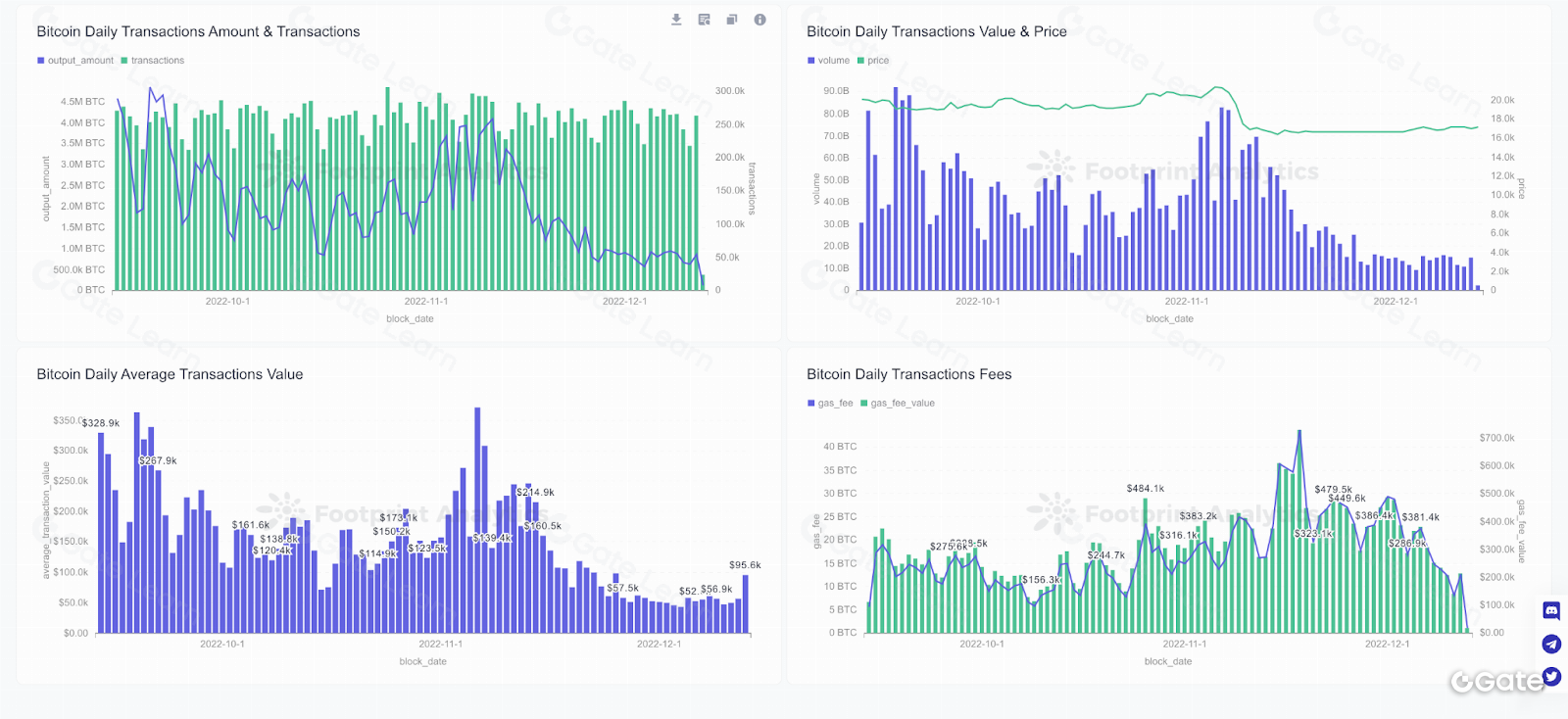
Có thể có người thắc mắc: tại sao cần dùng công cụ trực quan hóa khi block explorer đã cung cấp thông tin đầy đủ? Công cụ trực quan hóa dữ liệu và block explorer đều là công cụ phân tích dữ liệu on-chain nhưng phục vụ các mục đích và cung cấp loại thông tin khác nhau.
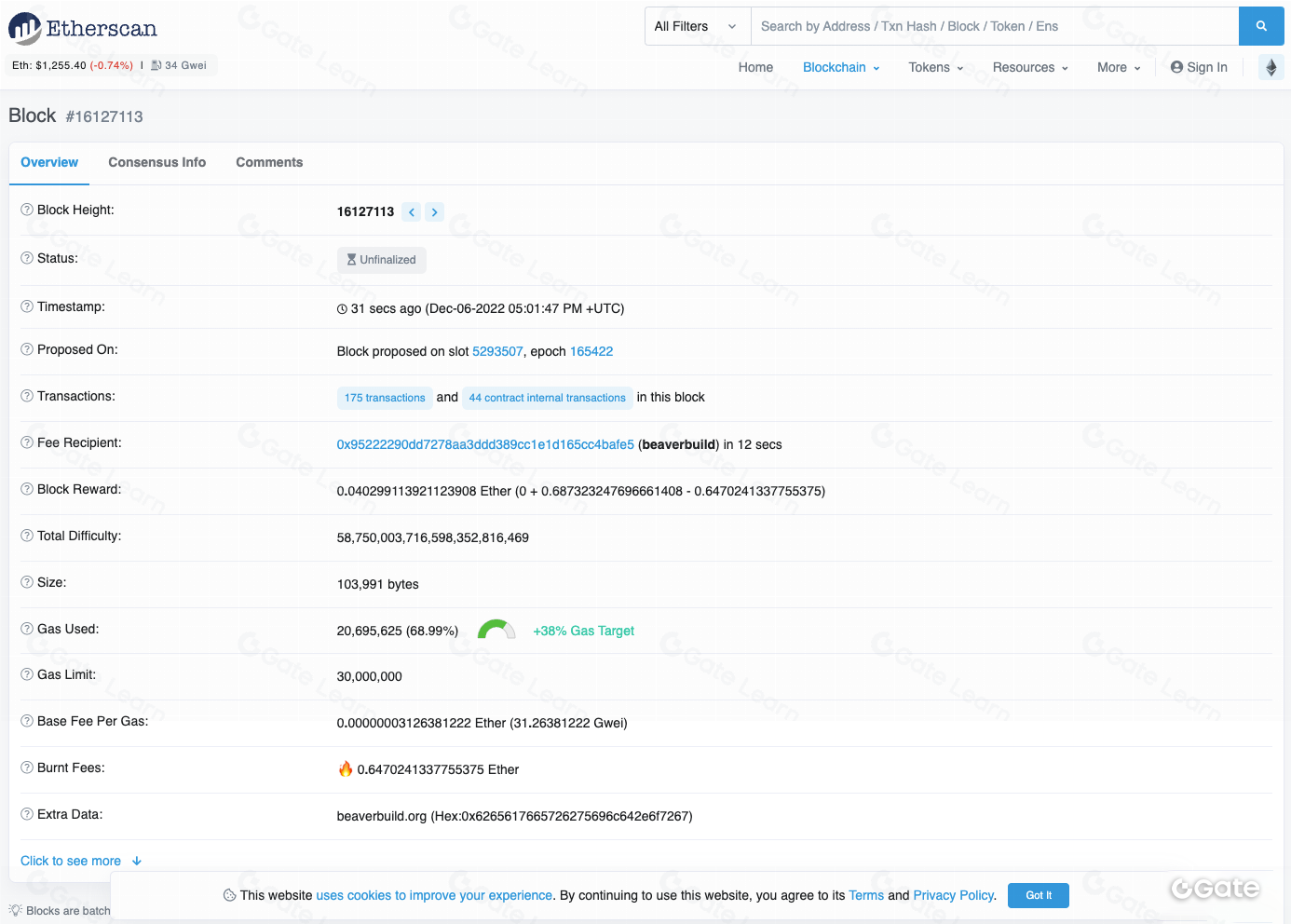
Công cụ trực quan hóa dữ liệu tập trung vào việc thể hiện dữ liệu dưới dạng trực quan, giúp dễ hiểu và nhận diện xu hướng, khuôn mẫu. Ngược lại, block explorer là công cụ trực tuyến cho phép người dùng duyệt blockchain, xem thông tin về block, giao dịch, địa chỉ cụ thể. Block explorer cung cấp giao diện thân thiện để truy cập, tương tác với dữ liệu trên blockchain nhưng thường không có tính năng phân tích, trực quan hóa nâng cao. Nhìn chung, nên kết hợp công cụ trực quan hóa dữ liệu với block explorer để có cái nhìn toàn diện hơn về dữ liệu trên blockchain.
Web3; khoa học dữ liệu; cơ hội nghề nghiệp
Có bốn yếu tố cần cân nhắc khi bàn về tương lai của Web3 và khoa học dữ liệu:
Web3 sẽ tạo ra nhiều cơ hội việc làm hơn cho các nhà khoa học dữ liệu và chuyên gia dữ liệu. Lý do là các tổ chức chuẩn bị áp dụng Web3 sẽ cần nhiều nhân sự có kinh nghiệm chuyên sâu về phân tích, diễn giải dữ liệu, phát triển sản phẩm và dịch vụ dựa trên dữ liệu, đồng thời tích hợp AI, ML vào quy trình.
Người dùng và nhà khoa học dữ liệu sẽ được hưởng lợi tài chính từ Web3. Doanh nghiệp có thể mua dữ liệu trực tiếp từ người dùng (chủ sở hữu dữ liệu có thể bán cho bất kỳ ai), kết hợp, pha trộn bộ dữ liệu mới với dữ liệu hiện có để cải thiện mô hình học máy, sau đó bán các thông tin mới ra thị trường mở.
Nhà khoa học dữ liệu có thể ứng dụng AI để hiểu sâu hơn nhu cầu từng khách hàng trên Web3. Các công ty dữ liệu có thể xây dựng mô hình ngôn ngữ mang lại "hiểu biết ngữ nghĩa" vì Web3 tập trung vào từng người dùng và dữ liệu gắn với tương tác của họ, từ đó tạo ra giải pháp cá nhân hóa. Công ty dữ liệu cũng có thể rút trích thông tin từ dữ liệu thô và chuyển thành đề xuất sản phẩm tốt hơn, nâng cao trải nghiệm khách hàng dựa trên kỳ vọng của họ.
Nhà khoa học dữ liệu sẽ có tác động lớn hơn đến kinh tế toàn cầu trong kỷ nguyên Web3. Họ sẽ trở thành những "nơron" mới, hỗ trợ tạo nội dung hoặc mô hình AI phối hợp cùng các mô hình AI khác để giải quyết vấn đề phức tạp hoặc rủi ro tiềm ẩn cho doanh nghiệp, tổ chức.








