Thách thức đối với hệ sinh thái dữ liệu blockchain hiện đại
Một startup lập chỉ mục dữ liệu blockchain hiện đại sẽ phải đối mặt với nhiều thách thức, bao gồm:
- Lượng dữ liệu khổng lồ. Khi dữ liệu trên blockchain ngày càng tăng, chỉ mục dữ liệu cần mở rộng để xử lý tải lớn hơn và đảm bảo truy cập hiệu quả. Điều này dẫn đến chi phí lưu trữ cao hơn, tốc độ tính toán chỉ số chậm và áp lực lớn lên máy chủ cơ sở dữ liệu.
- Quy trình xử lý dữ liệu phức tạp. Công nghệ blockchain vốn phức tạp, việc xây dựng chỉ mục dữ liệu toàn diện, đáng tin cậy đòi hỏi hiểu sâu về cấu trúc dữ liệu và thuật toán nền tảng, đồng thời chịu ảnh hưởng từ sự đa dạng của các blockchain. Ví dụ, NFT trên Ethereum thường được tạo bằng hợp đồng thông minh theo chuẩn ERC721 và ERC1155, trong khi trên Polkadot lại triển khai trực tiếp trong runtime blockchain. Dù cách tạo khác nhau, cuối cùng tất cả đều được coi là NFT và cần lưu trữ đúng dạng này.
- Khả năng tích hợp. Để tối ưu giá trị cho người dùng, giải pháp lập chỉ mục dữ liệu blockchain cần tích hợp với các hệ thống khác như nền tảng phân tích hoặc API. Việc này đòi hỏi thiết kế kiến trúc phức tạp và nhiều nỗ lực triển khai.
Khi blockchain ngày càng phổ biến, lượng dữ liệu lưu trữ trên blockchain cũng tăng mạnh do số lượng người dùng lớn hơn và mỗi giao dịch đều bổ sung dữ liệu mới. Ngoài ra, ứng dụng blockchain đã phát triển từ chuyển tiền đơn giản như Bitcoin sang các ứng dụng phức tạp hơn, tích hợp logic kinh doanh trong hợp đồng thông minh. Các hợp đồng này tạo ra lượng lớn dữ liệu, khiến blockchain ngày càng lớn và phức tạp.
Bài viết này phân tích quá trình phát triển kiến trúc công nghệ của Footprint Analytics qua từng giai đoạn, làm ví dụ điển hình cho cách công nghệ Iceberg-Trino giải quyết thách thức dữ liệu on-chain.
Footprint Analytics đã lập chỉ mục khoảng 22 blockchain công khai, 17 sàn NFT, 1.900 dự án GameFi và hơn 100.000 bộ sưu tập NFT thành một tầng dữ liệu trừu tượng ngữ nghĩa. Đây là giải pháp kho dữ liệu blockchain toàn diện nhất thế giới.
Dữ liệu blockchain, với hơn 20 tỷ dòng giao dịch tài chính thường xuyên được truy vấn bởi các nhà phân tích dữ liệu, khác biệt hoàn toàn so với log ingression trong kho dữ liệu truyền thống.
Trong vài tháng qua, chúng tôi đã thực hiện 3 lần nâng cấp lớn để đáp ứng nhu cầu kinh doanh ngày càng tăng:
Kiến trúc 1.0 Bigquery
Khi bắt đầu, Footprint Analytics sử dụng Google Bigquery làm hệ thống lưu trữ và truy vấn. Bigquery là sản phẩm xuất sắc: tốc độ cực nhanh, dễ sử dụng, cung cấp sức mạnh tính toán động và cú pháp UDF linh hoạt giúp hoàn thành công việc nhanh chóng.
Tuy nhiên, Bigquery cũng tồn tại nhiều hạn chế.
- Dữ liệu không nén, khiến chi phí lưu trữ rất cao, đặc biệt khi lưu trữ dữ liệu thô của hơn 22 blockchain.
- Khả năng xử lý đồng thời thấp: Bigquery chỉ hỗ trợ 100 truy vấn đồng thời, không đáp ứng được yêu cầu phục vụ lượng lớn nhà phân tích và người dùng.
- Bị ràng buộc với Google Bigquery, vốn là sản phẩm đóng mã nguồn.
Vì vậy, chúng tôi quyết định tìm kiếm các kiến trúc thay thế khác.
Kiến trúc 2.0 OLAP
Chúng tôi đặc biệt quan tâm tới các sản phẩm OLAP đang rất phổ biến. Điểm mạnh nhất của OLAP là thời gian phản hồi truy vấn cực nhanh (chỉ dưới một giây với lượng dữ liệu lớn) và khả năng hỗ trợ hàng nghìn truy vấn đồng thời.
Chúng tôi lựa chọn Doris, một trong những cơ sở dữ liệu OLAP tốt nhất, để thử nghiệm. Động cơ này hoạt động ổn định, tuy nhiên sau một thời gian, chúng tôi gặp các vấn đề sau:
- Chưa hỗ trợ kiểu dữ liệu Array hoặc JSON (tháng 11 năm 2022). Array là kiểu dữ liệu phổ biến trên một số blockchain, ví dụ trường topic trong evm logs. Không thể tính toán trực tiếp trên Array khiến hạn chế khả năng tính toán nhiều chỉ số kinh doanh.
- Hỗ trợ hạn chế cho DBT và các câu lệnh merge, vốn là yêu cầu phổ biến trong các kịch bản ETL/ELT khi cần cập nhật dữ liệu mới lập chỉ mục.
Vì vậy, chúng tôi không thể dùng Doris cho toàn bộ pipeline dữ liệu sản xuất, mà chỉ dùng Doris như cơ sở dữ liệu OLAP để giải quyết một phần vấn đề, đóng vai trò động cơ truy vấn nhanh và đồng thời cao.
Đáng tiếc, Doris không thể thay thế hoàn toàn Bigquery, nên chúng tôi phải đồng bộ dữ liệu định kỳ từ Bigquery sang Doris, chỉ sử dụng Doris cho truy vấn. Quá trình này gặp nhiều vấn đề, đặc biệt là các thao tác ghi cập nhật bị ùn ứ khi OLAP engine bận phục vụ truy vấn cho người dùng đầu cuối, làm chậm tốc độ ghi và khiến đồng bộ kéo dài, thậm chí không thể hoàn tất.
Chúng tôi nhận ra OLAP chỉ giải quyết được một phần vấn đề, không thể là giải pháp toàn diện cho pipeline xử lý dữ liệu của Footprint Analytics. Vấn đề của chúng tôi lớn hơn và phức tạp hơn, OLAP chỉ là động cơ truy vấn thì chưa đủ.
Kiến trúc 3.0 Iceberg + Trino
Chào mừng bạn đến với kiến trúc 3.0 của Footprint Analytics, một cuộc đại tu toàn diện. Chúng tôi thiết kế lại toàn bộ kiến trúc, tách biệt lưu trữ, tính toán và truy vấn dữ liệu thành ba phần riêng biệt, rút ra bài học từ hai kiến trúc trước và kinh nghiệm các dự án big data thành công như Uber, Netflix, Databricks.
Giới thiệu về data lake
Chúng tôi tập trung vào data lake, loại lưu trữ mới cho dữ liệu có cấu trúc và không cấu trúc. Data lake rất phù hợp với lưu trữ dữ liệu on-chain vì định dạng dữ liệu rất đa dạng, từ dữ liệu thô không cấu trúc đến dữ liệu trừu tượng có cấu trúc mà Footprint Analytics nổi tiếng. Chúng tôi kỳ vọng data lake sẽ giải quyết vấn đề lưu trữ và hỗ trợ các động cơ tính toán phổ biến như Spark, Flink, giúp dễ dàng tích hợp khi Footprint Analytics phát triển.
Iceberg tích hợp tốt với Spark, Flink, Trino và các động cơ khác, cho phép chúng tôi chọn động cơ phù hợp cho từng chỉ số. Ví dụ:
- Logic tính toán phức tạp: chọn Spark.
- Tính toán thời gian thực: dùng Flink.
- Tác vụ ETL đơn giản bằng SQL: dùng Trino.
Động cơ truy vấn
Sau khi Iceberg giải quyết vấn đề lưu trữ và tính toán, chúng tôi cân nhắc lựa chọn động cơ truy vấn. Các lựa chọn gồm:
- Trino: Động cơ truy vấn SQL
- Presto: Động cơ truy vấn SQL
- Kyuubi: Serverless Spark SQL
Điều quan trọng nhất là động cơ truy vấn phải tương thích với kiến trúc hiện tại.
- Hỗ trợ Bigquery làm nguồn dữ liệu
- Hỗ trợ DBT, dùng để tạo nhiều chỉ số
- Hỗ trợ công cụ BI Metabase
Dựa trên các tiêu chí này, chúng tôi chọn Trino, vốn hỗ trợ Iceberg rất tốt và đội ngũ phát triển phản hồi cực nhanh: chỉ cần báo lỗi là hôm sau có bản sửa, tuần sau cập nhật lên phiên bản mới nhất. Đây là lựa chọn tối ưu cho đội ngũ Footprint với yêu cầu triển khai linh hoạt.
Kiểm thử hiệu năng
Sau khi chốt giải pháp, chúng tôi kiểm thử hiệu năng tổ hợp Trino + Iceberg để đánh giá khả năng đáp ứng nhu cầu, và bất ngờ với tốc độ truy vấn cực nhanh.
So với Presto + Hive vốn lép vế trong các so sánh OLAP nhiều năm qua, tổ hợp Trino + Iceberg thực sự gây ấn tượng mạnh.
Kết quả kiểm thử như sau:
Trường hợp 1: join bộ dữ liệu lớn
Bảng 800 GB (table1) join với bảng 50 GB (table2), thực hiện tính toán kinh doanh phức tạp
Trường hợp 2: dùng bảng lớn truy vấn distinct
Test sql: select distinct(address) from table group by day

Trino+Iceberg nhanh gấp khoảng 3 lần Doris trong cùng cấu hình.
Bên cạnh đó, Iceberg hỗ trợ các định dạng dữ liệu như Parquet, ORC giúp nén và lưu trữ dữ liệu. Lưu trữ bảng của Iceberg chỉ chiếm khoảng 1/5 dung lượng so với các kho dữ liệu khác. Kích thước lưu trữ của cùng bảng ở ba hệ thống như sau:

Lưu ý: Các kiểm thử trên là ví dụ thực tế trong sản xuất và chỉ mang tính tham khảo.
・Hiệu quả nâng cấp
Báo cáo kiểm thử hiệu năng mang lại sự tự tin cho đội ngũ, chỉ mất khoảng 2 tháng để hoàn thành di chuyển, dưới đây là sơ đồ kiến trúc sau nâng cấp.
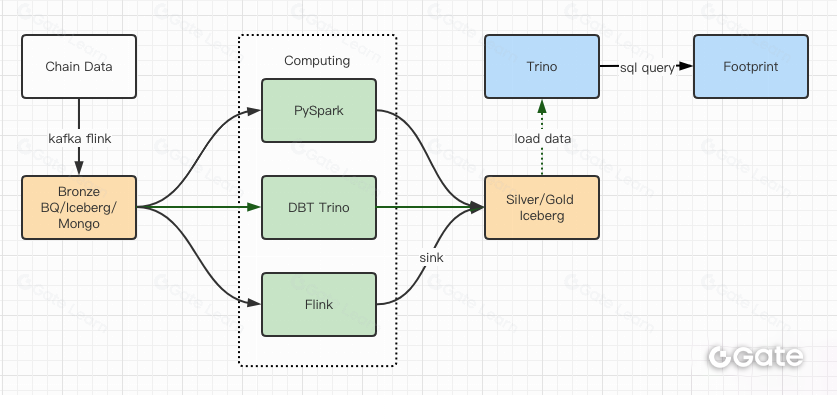
- Nhiều động cơ tính toán đáp ứng mọi nhu cầu.
- Trino hỗ trợ DBT, truy vấn trực tiếp Iceberg, không còn phải đồng bộ dữ liệu.
- Hiệu năng vượt trội của Trino + Iceberg cho phép mở toàn bộ dữ liệu Bronze (dữ liệu thô) cho người dùng.
Tóm tắt
Từ tháng 8 năm 2021, đội ngũ Footprint Analytics đã hoàn thành 3 lần nâng cấp kiến trúc chỉ trong chưa đầy 18 tháng, nhờ khát vọng mang công nghệ cơ sở dữ liệu tốt nhất đến cộng đồng tiền điện tử và sự quyết tâm trong triển khai, nâng cấp hạ tầng.
Kiến trúc 3.0 của Footprint Analytics mang lại trải nghiệm mới, giúp người dùng ở nhiều lĩnh vực khai thác thông tin đa dạng trong nhiều kịch bản:
- Với công cụ BI Metabase, Footprint giúp nhà phân tích truy cập dữ liệu on-chain đã giải mã, tự do lựa chọn công cụ (no-code hoặc code chuyên sâu), truy vấn toàn bộ lịch sử, đối chiếu dữ liệu và khai thác insight tức thì.
- Tích hợp dữ liệu on-chain và off-chain để phân tích toàn diện web2 + web3;
- Xây dựng/truy vấn chỉ số dựa trên lớp trừu tượng kinh doanh của Footprint giúp nhà phân tích, nhà phát triển tiết kiệm 80% thời gian xử lý dữ liệu lặp lại, tập trung vào chỉ số giá trị, nghiên cứu và giải pháp sản phẩm theo mục tiêu kinh doanh.
- Trải nghiệm liền mạch từ Footprint Web đến REST API, tất cả dựa trên SQL
- Cảnh báo thời gian thực và thông báo hành động theo tín hiệu quan trọng, hỗ trợ quyết định đầu tư








