Titre original : Comment arrêter de perdre de l’argent face aux hacks DeFi
Auteur original : sysls, openforage
Traduction originale : AididiaoJP, Foresight News
Introduction
Après avoir étudié de nombreux incidents de piratage de protocoles DeFi, j’ai développé une crainte envers les « acteurs étatiques ». Ils sont techniquement compétents, disposent de ressources abondantes, et jouent à un jeu à très long terme ; ces super-vilains se concentrent à explorer chaque recoin de vos protocoles et infrastructures pour trouver des vulnérabilités, alors que les équipes de protocoles ordinaires sont dispersées sur six ou sept axes d’activité différents.
Je ne me prétends pas expert en sécurité, mais j’ai dirigé des équipes dans des environnements à haut risque (y compris dans l’armée et le secteur financier avec des fonds importants), et j’ai une grande expérience dans la réflexion et la planification de plans d’urgence.
Je crois sincèrement que seul le paranoïaque peut survivre. Aucune équipe ne commence en pensant « je vais adopter une attitude négligente et désinvolte envers la sécurité » ; pourtant, les attaques ont lieu. Nous devons faire mieux.
L’IA signifie que cette fois, c’est vraiment différent
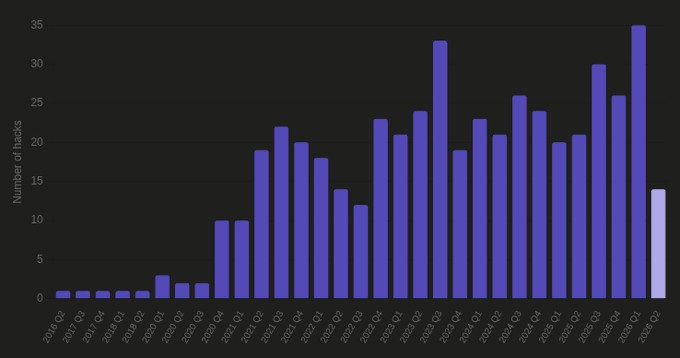
(Source des données : https://defillama.com/hacks)
Les attaques de piratage ne sont pas rares, mais leur fréquence augmente nettement. Le premier trimestre 2026 a été le trimestre avec le plus grand nombre d’attaques DeFi enregistrées, et alors que le deuxième trimestre vient à peine de commencer, il semble déjà prêt à battre le record du trimestre précédent.
Mon hypothèse centrale est : l’IA réduit considérablement le coût de recherche de vulnérabilités et étend énormément la surface d’attaque. Il faut plusieurs semaines à un humain pour analyser la configuration de cent protocoles à la recherche d’erreurs ; alors que les modèles de base les plus récents peuvent le faire en quelques heures.
Cela devrait changer radicalement notre façon de penser et de répondre aux attaques. Les protocoles anciens, habitués à la sécurité avant que l’IA ne devienne puissante, font face à un risque croissant d’être « balayés » en une seconde.
Penser en surface et en hiérarchie
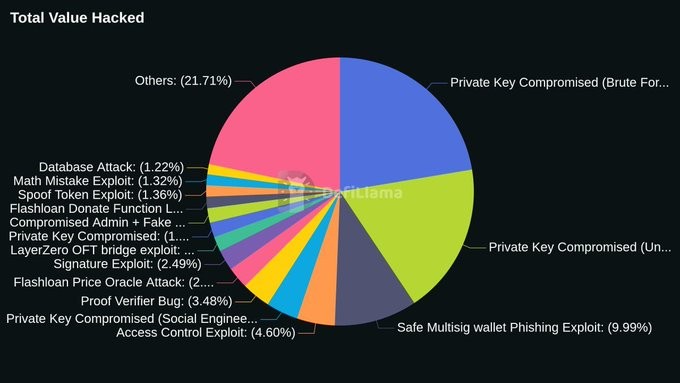
(Source des données : https://defillama.com/hacks)
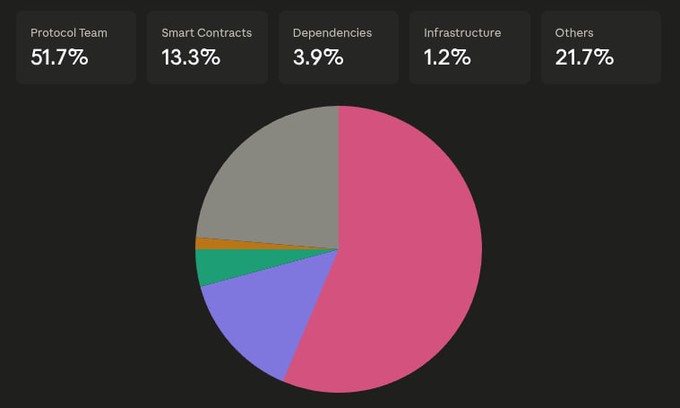
La surface d’attaque réelle peut être résumée en trois : l’équipe du protocole, les contrats intelligents et l’infrastructure, la frontière de confiance des utilisateurs (DSN, médias sociaux, etc.).
Une fois ces surfaces identifiées, superposez des couches de défense :
· Prévention : en appliquant strictement, vous pouvez réduire au maximum la probabilité d’exploitation.
· Atténuation : en cas d’échec de la prévention, limiter l’ampleur des dégâts.
· Pause : personne ne peut prendre la meilleure décision sous une pression extrême. Dès qu’une attaque est confirmée, activez immédiatement le bouton d’arrêt total. La suspension peut empêcher des pertes supplémentaires et vous donner du temps pour réfléchir…
· Récupération : si vous perdez le contrôle d’un composant toxique ou compromis, abandonnez-le et remplacez-le.
· Rétablissement : récupérez ce que vous avez perdu. Prévoyez à l’avance des partenaires capables de geler des fonds, d’annuler des transactions et d’aider à l’enquête.
Principes
Ces principes guident nos actions concrètes pour chaque couche de défense.
Utilisation intensive de l’IA de pointe
Utilisez massivement des modèles d’IA avancés pour scanner votre code et configuration, rechercher des vulnérabilités, et effectuer des tests de red team à grande échelle : essayez de trouver des failles en front-end pour voir si elles peuvent atteindre le back-end. Les attaquants le font déjà. Ce que vous pouvez détecter par des scans défensifs, ils l’ont déjà repéré par des scans offensifs.
Utilisez des plateformes IA comme pashov, nemesis, ainsi que Cantina (Apex) et Zellic (V12) pour analyser rapidement votre code avant un audit complet.
Le temps et la friction sont de bonnes défenses
Ajoutez plusieurs étapes et verrouillages temporels pour toute opération potentiellement dommageable. Vous avez besoin de suffisamment de temps pour intervenir et geler en cas d’anomalie détectée.
Les raisons pour lesquelles on s’opposait aux verrous temporels et aux processus à étapes multiples étaient qu’ils créaient de la friction pour l’équipe du protocole. Désormais, vous n’avez pas à trop vous en soucier : l’IA peut facilement passer ces étapes en arrière-plan.
Invariants
Les contrats intelligents peuvent se défendre en écrivant des « faits » immuables : si ces faits sont brisés, toute la logique du protocole s’effondre.
Vous n’avez généralement que quelques invariants. Il faut les remonter prudemment dans le code ; imposer plusieurs invariants dans chaque fonction devient difficile à gérer.
Équilibre des pouvoirs
De nombreuses attaques proviennent de portefeuilles compromis. Vous avez besoin d’une configuration permettant, même si une multisignature est attaquée, de limiter rapidement les dégâts et de ramener le protocole à un état gouvernable.
Cela nécessite un équilibre entre gouvernance (qui décide de tout) et secours (capacité à restaurer une stabilité gouvernable, sans pouvoir remplacer ou renverser la gouvernance).
Il y aura toujours des problèmes
Partant du principe : peu importe votre intelligence, vous serez piraté. Vos contrats ou dépendances peuvent échouer. Vous pouvez être victime d’attaques d’ingénierie sociale, et les nouvelles mises à jour peuvent introduire des vulnérabilités inattendues.
En adoptant cette mentalité, les limiteurs de dégâts et les disjoncteurs de protocole deviennent vos meilleurs alliés. Limitez les dégâts à 5-10 %, puis figez, et planifiez votre réponse. Personne ne peut prendre la meilleure décision sous un feu nourri.
Le meilleur moment pour planifier, c’est maintenant
Réfléchissez à votre réponse avant d’être piraté. Encodez autant que possible vos processus et entraînez votre équipe, pour ne pas être pris au dépourvu lors d’une crise. À l’ère de l’IA, cela signifie maîtriser des compétences et des algorithmes capables de produire rapidement une grande quantité d’informations, puis de les partager sous forme de résumés ou de rapports détaillés à votre cercle central.
Vous n’avez pas besoin de la perfection, mais vous devez survivre. Aucun système n’est invulnérable dès le départ ; par itérations successives, vous deviendrez résilient en tirant des leçons.
L’absence de preuve d’inviolabilité ne signifie pas que vous ne serez pas piraté. Le point de plus grande vulnérabilité est souvent celui où vous êtes le plus à l’aise.
Mesures préventives
Conception de contrats intelligents
Une fois que vous avez identifié des invariants, remontez-les en vérifications à l’exécution. Réfléchissez soigneusement à ceux qui méritent d’être réellement imposés.
C’est le mode FREI-PI (Fonction Requirements, Effects, Interactions, Protocol Invariants) : à la fin de chaque fonction touchant à la valeur, vérifiez à nouveau que les invariants de la couronne que cette fonction doit maintenir sont respectés. Beaucoup d’attaques par CEI (Checks-Effects-Interactions) (flash loans, liquidation assistée par oracles, drainages inter-fonctions) peuvent être capturées par ces vérifications en fin de fonction.
Bonnes pratiques de test
Les tests de fuzzing à état (Stateful fuzzing) génèrent des séquences d’appels aléatoires sur la surface complète du protocole, en affirmant que les invariants tiennent à chaque étape. La plupart des vulnérabilités en production sont multi-transactionnelles, et le fuzzing à état est presque la seule méthode fiable pour découvrir ces chemins avant les attaquants.
Utilisez des tests d’invariants pour assurer que ces propriétés tiennent dans toutes les séquences d’appels générées par le fuzzing. Associé à la vérification formelle, cela peut prouver que ces propriétés sont valides dans tous les états accessibles. Vos invariants de couronne doivent absolument supporter cette approche.
Oracles et dépendances
La complexité est l’ennemi de la sécurité. Chaque dépendance externe augmente la surface d’attaque. Lors de la conception, donnez aux utilisateurs le choix de faire confiance à qui et à quoi. Si vous ne pouvez pas éliminer la dépendance, diversifiez-la pour qu’aucun point unique de défaillance ne puisse détruire votre protocole.
Étendez la portée des audits pour couvrir la simulation de défaillances des oracles et dépendances, et imposez des limites de taux sur les conséquences possibles de leur échec.
Le récent bug de KelpDAO en est un exemple : ils ont hérité de la configuration LayerZero default requiredDVNCount=1, hors de leur périmètre d’audit. La faille a été exploitée dans l’infrastructure hors audit, en dehors de leur contrôle.
Surface d’attaque
La majorité des surfaces d’attaque dans la DeFi ont déjà été listées. Vérifiez chaque catégorie, demandez si elle s’applique à votre protocole, puis mettez en place des contrôles pour chaque vecteur. Développez des compétences en red team, et faites en sorte que votre IA cherche activement des vulnérabilités dans votre protocole ; c’est désormais une exigence de base.
Posséder une capacité de secours native
Dans une gouvernance basée sur le vote, le pouvoir est initialement concentré dans la multisignature de l’équipe, ce qui prend du temps à se diffuser. Même avec une large distribution de tokens, la délégation tend à concentrer l’autorité dans quelques portefeuilles (parfois même un seul). Lorsqu’ils sont compromis, c’est la fin du jeu.
Déployez un « portefeuille gardien », avec des autorisations strictes : ils ne peuvent que suspendre le protocole, et en cas de seuil >=4/7, ils peuvent, dans des situations extrêmes, remplacer le portefeuille compromis par un portefeuille de remplacement prédéfini. Ces gardiens ne peuvent jamais proposer de gouvernance.
Ainsi, vous disposez d’une couche de secours toujours capable de restaurer une stabilité gouvernable, sans pouvoir renverser la gouvernance. La probabilité que >=4/7 des gardiens soient perdus est très faible (en tenant compte de la diversité des détenteurs), et une fois la gouvernance mature et dispersée, cette couche pourra être progressivement éliminée.
Topologie des portefeuilles et clés
Une multisignature avec au moins 4/7 est le minimum. Aucun individu ne doit contrôler seul les 7 clés. Faites des rotations fréquentes des signataires, discrètement.
Les clés ne doivent jamais interagir avec des appareils utilisés quotidiennement. Si vous utilisez un appareil de signature pour naviguer sur Internet, envoyer des mails ou ouvrir Slack, considérez que cette clé est compromise.
Déployez plusieurs multisignatures, chacune pour un usage différent. Supposez qu’au moins une d’entre elles sera compromise, et planifiez en conséquence. Aucun individu ne doit avoir un contrôle suffisant pour compromettre le protocole, même dans des scénarios extrêmes (kidnapping, torture, etc.).
Considérez la mise en place de bounties
Si vous avez des ressources, il est très judicieux de fixer une récompense de bug élevée en proportion du TVL du protocole ; même pour un protocole plus petit, la récompense doit être aussi généreuse que possible (par exemple, à 7-8 chiffres minimum).
Face à des acteurs étatiques, ils peuvent ne pas négocier, mais vous pouvez toujours participer à un programme « white hat bounty », en autorisant des white hats à agir en votre nom pour protéger les fonds, en leur versant un pourcentage des bugs trouvés (en réalité payé par les déposants).
Trouver de bons auditeurs
J’ai déjà écrit que, avec l’évolution des grands modèles de langage, la valeur marginale de l’embauche d’auditeurs diminue. Je maintiens cette position, mais mon point de vue a évolué.
D’abord, un bon auditeur sera toujours en avance sur la courbe. Si vous faites quelque chose d’innovant, votre code et ses vulnérabilités peuvent ne pas être dans leur entraînement, et augmenter simplement le nombre de tokens n’a pas encore prouvé qu’il permet de découvrir efficacement de nouvelles vulnérabilités. Vous ne voulez pas être le premier à tomber sur une vulnérabilité unique.
Ensuite, un avantage sous-estimé est : engager un auditeur, c’est aussi utiliser leur réputation comme garantie. S’ils approuvent en signant, et que vous êtes attaqué, ils ont une forte incitation à aider. Établir une relation avec des professionnels de la sécurité est un atout considérable.
Pratiquer la sécurité opérationnelle
Considérez la sécurité opérationnelle comme un indicateur de succès. Faites des exercices de phishing ; engagez (des partenaires de confiance) en red team pour tester la résistance sociale de votre équipe. Préparez des hardware wallets et appareils de secours pour remplacer tout le multisig si nécessaire. Vous ne voulez pas devoir tout acheter en urgence le jour J.
Mesures d’atténuation
Votre voie de sortie est la limite de perte
Le montant maximal théorique que vous pouvez perdre en exploitant une voie de sortie est celui que cette voie peut causer en cas de vulnérabilité. En termes simples : une fonction de mint sans limite par bloc, c’est un chèque en blanc pour tout exploit de création infinie. Une fonction de redemption sans limite hebdomadaire, c’est un chèque en blanc pour tout solde d’actifs corrompu.
Réfléchissez soigneusement à ces limites. Elles doivent équilibrer votre tolérance maximale aux dégâts et l’expérience utilisateur extrême. En cas de problème, c’est ce qui vous évitera la destruction totale.
Listes blanche (et noire)
La plupart des protocoles disposent de listes de comptes pouvant être appelés, échangés ou recevant des fonds, ainsi que de listes d’interdiction pour certains utilisateurs. Même implicites, ces listes sont des frontières de confiance, qu’il faut formaliser.
Formaliser ces listes permet de mettre en place des mécanismes à deux étapes, créant une friction significative. L’attaquant doit d’abord ajouter à la liste blanche (ou retirer de la liste noire), puis agir. Avoir les deux signifie que pour introduire une nouvelle vulnérabilité, il faut compromettre simultanément deux processus : que le marché autorise (listing / listing), et que l’action ne soit pas interdite (audit de sécurité).
Récupération
Surveillance algorithmique
Sans surveillance, le kill switch est inutile. Les moniteurs hors chaîne doivent suivre en permanence les invariants, et en cas de problème, alerter de façon algorithmique. La dernière étape doit revenir à des humains responsables, avec suffisamment de contexte pour décider en quelques minutes.
Recalibrer en arrêtant
En cas de piratage, il faut d’abord arrêter l’hémorragie, plutôt que de prendre des décisions dans la précipitation. Pour le protocole, cela correspond au kill switch (qui doit aussi apparaître dans l’UI) : un bouton permettant de suspendre toutes les voies de transfert de valeur en une seule transaction. Préparez un script auxiliaire pour tout suspendre de façon atomique.
Seul la gouvernance peut lever la suspension, donc le kill switch ne doit pas suspendre la gouvernance elle-même. Si la couche de gardiens peut suspendre le contrat de gouvernance, la couche de gardiens compromis peut bloquer à jamais la restauration.
Lancez votre salle de crise
Figez, arrêtez l’hémorragie, puis rassemblez toutes vos personnes de confiance (petit cercle, préalablement convenu) dans un canal de communication. Limitez la diffusion pour éviter que l’information ne fuite aux attaquants, au public ou à des acteurs malveillants.
Jouez des rôles précis : un décideur ; un opérateur capable d’exécuter rapidement des scripts de défense et de suspension ; une personne pour analyser les vulnérabilités et en identifier la cause racine ; un communicant avec les parties clés ; un archiviste pour suivre observations, événements et décisions.
Quand chaque personne connaît son rôle et a été entraînée, vous pouvez réagir selon un plan, plutôt que paniquer à la première crise.
Considérez la réaction en chaîne
Supposez que votre attaquant soit très expérimenté. La première vulnérabilité peut être un leurre ou une étape préparatoire à une attaque plus grande. L’attaque peut consister à vous faire faire une erreur fatale, déclenchant la vraie faille.
La pause doit être pleinement contrôlée, totalement vérifiable, et elle ne doit pas elle-même être exploitable. La pause doit figer tout le protocole : vous ne voulez pas qu’une pause d’un composant ouvre une brèche dans un autre. Une fois la cause racine et la vecteur d’attaque identifiés, explorez toutes les surfaces exposées et réactions en chaîne, et corrigez tout en une seule fois.
Rotation des successeurs prévus
Seuls ceux dont vous connaissez à l’avance le successeur sont sûrs. La rotation doit être planifiée : un registre de successeurs préenregistrés permet de rendre la transition plus sûre. Cela complique aussi la tâche des attaquants, qui doivent compromettre plusieurs acteurs pour changer la hiérarchie.
Pour chaque rôle critique, enregistrez une adresse de successeur. La seule opération d’urgence autorisée est « remplacer le rôle X par son successeur ». Cela vous permet aussi d’évaluer les successeurs en temps de paix : faire du due diligence, rencontrer ceux qui proposent, etc.
Testez prudemment avant la mise à jour
Une fois que vous avez identifié la cause racine et l’étendue, vous pouvez déployer une mise à jour. C’est souvent le code le plus risqué que vous déployez : écrit sous pression, pour un attaquant qui connaît déjà votre protocole et ses vulnérabilités.
Ne déployez pas sans tests suffisants. Si vous manquez de temps pour un audit, utilisez des relations avec des white hats, ou organisez un concours de 48 heures avant déploiement pour un dernier test de résistance.
Récupération
Réagir rapidement
Les fonds volés ont une demi-vie : une fois la faille exploitée, ils entrent rapidement dans des circuits de blanchiment. Préparez à l’avance des partenaires comme Chainalysis pour suivre en temps réel les adresses des attaquants, et alerter les plateformes lors de transferts inter-chaînes.
Préparez une liste centralisée de contacts : services de conformité, gestionnaires de ponts cross-chain, custodians, et autres tiers pouvant geler des messages cross-chain ou des dépôts en transit.
Négociation
Oui, c’est douloureux, mais il faut tenter de dialoguer avec l’attaquant. Beaucoup de situations peuvent se résoudre par la négociation. Offrez une récompense white hat à durée limitée, et annoncez publiquement qu’en cas de restitution intégrale avant la date limite, aucune action légale ne sera engagée.
Face à des acteurs étatiques, ils peuvent ne pas négocier, mais vous pouvez toujours participer à un programme « bounty white hat », en autorisant des white hats à agir en votre nom pour protéger les fonds, en leur versant un pourcentage des bugs trouvés (payé en réalité par les déposants).
Trouver de bons auditeurs
J’ai déjà écrit que, avec l’évolution des grands modèles de langage, la valeur marginale de l’embauche d’auditeurs diminue. Je maintiens cette position, mais mon point de vue a évolué.
D’abord, un bon auditeur sera toujours en avance sur la courbe. Si vous faites quelque chose d’innovant, votre code et ses vulnérabilités peuvent ne pas être dans leur entraînement, et augmenter simplement le nombre de tokens n’a pas encore prouvé qu’il permet de découvrir efficacement de nouvelles vulnérabilités. Vous ne voulez pas être le premier à tomber sur une vulnérabilité unique.
Ensuite, un avantage sous-estimé est : engager un auditeur, c’est aussi utiliser leur réputation comme garantie. S’ils approuvent en signant, et que vous êtes attaqué, ils ont une forte incitation à aider. Établir une relation avec des professionnels de la sécurité est un atout considérable.
Pratiquer la sécurité opérationnelle
Considérez la sécurité opérationnelle comme un indicateur de succès. Faites des exercices de phishing ; engagez (des partenaires de confiance) en red team pour tester la résistance sociale de votre équipe. Préparez des hardware wallets et appareils de secours pour remplacer tout le multisig si nécessaire. Vous ne voulez pas devoir tout acheter en urgence le jour J.
Mesures d’atténuation
Votre voie de sortie est la limite de perte
Le montant maximal théorique que vous pouvez perdre en exploitant une voie de sortie est celui que cette voie peut causer en cas de vulnérabilité. En termes simples : une fonction de mint sans limite par bloc, c’est un chèque en blanc pour tout exploit de création infinie. Une fonction de redemption sans limite hebdomadaire, c’est un chèque en blanc pour tout solde d’actifs corrompu.
Réfléchissez soigneusement à ces limites. Elles doivent équilibrer votre tolérance maximale aux dégâts et l’expérience utilisateur extrême. En cas de problème, c’est ce qui vous évitera la destruction totale.
Listes blanche (et noire)
La plupart des protocoles disposent de listes de comptes pouvant être appelés, échangés ou recevant des fonds, ainsi que de listes d’interdiction pour certains utilisateurs. Même implicites, ces listes sont des frontières de confiance, qu’il faut formaliser.
Formaliser ces listes permet de mettre en place des mécanismes à deux étapes, créant une friction significative. L’attaquant doit d’abord ajouter à la liste blanche (ou retirer de la liste noire), puis agir. Avoir les deux signifie que pour introduire une nouvelle vulnérabilité, il faut compromettre simultanément deux processus : que le marché autorise (listing / delisting), et que l’action ne soit pas interdite (audit de sécurité).
Récupération
Surveillance algorithmique
Sans surveillance, le kill switch est inutile. Les moniteurs hors chaîne doivent suivre en permanence les invariants, et en cas de problème, alerter de façon algorithmique. La dernière étape doit revenir à des humains responsables, avec suffisamment de contexte pour décider en quelques minutes.
Recalibrer en arrêtant
En cas de piratage, il faut d’abord arrêter l’hémorragie, plutôt que de prendre des décisions dans la précipitation. Pour le protocole, cela correspond au kill switch (qui doit aussi apparaître dans l’UI) : un bouton permettant de suspendre toutes les voies de transfert de valeur en une seule transaction. Préparez un script auxiliaire pour tout suspendre de façon atomique.
Seul la gouvernance peut lever la suspension, donc le kill switch ne doit pas suspendre la gouvernance elle-même. Si la couche de gardiens peut suspendre le contrat de gouvernance, la couche de gardiens compromis peut bloquer à jamais la restauration.
Lancez votre salle de crise
Figez, arrêtez l’hémorragie, puis rassemblez toutes vos personnes de confiance (petit cercle, préalablement convenu) dans un canal de communication. Limitez la diffusion pour éviter que l’information ne fuite aux attaquants, au public ou à des acteurs malveillants.
Jouez des rôles précis : un décideur ; un opérateur capable d’exécuter rapidement des scripts de défense et de suspension ; une personne pour analyser les vulnérabilités et en identifier la cause racine ; un communicant avec les parties clés ; un archiviste pour suivre observations, événements et décisions.
Quand chaque personne connaît son rôle et a été entraînée, vous pouvez réagir selon un plan, plutôt que paniquer à la première crise.
Considérez la réaction en chaîne
Supposez que votre attaquant soit très expérimenté. La première vulnérabilité peut être un leurre ou une étape préparatoire à une attaque plus grande. L’attaque peut consister à vous faire faire une erreur fatale, déclenchant la vraie faille.
La pause doit être pleinement contrôlée, totalement vérifiable, et elle ne doit pas elle-même être exploitable. La pause doit figer tout le protocole : vous ne voulez pas qu’une pause d’un composant ouvre une brèche dans un autre. Une fois la cause racine et la vecteur d’attaque identifiés, explorez toutes les surfaces exposées et réactions en chaîne, et corrigez tout en une seule fois.
Rotation des successeurs prévus
Seuls ceux dont vous connaissez à l’avance le successeur sont sûrs. La rotation doit être planifiée : un registre de successeurs préenregistrés permet de rendre la transition plus sûre. Cela complique aussi la tâche des attaquants, qui doivent compromettre plusieurs acteurs pour changer la hiérarchie.
Pour chaque rôle critique, enregistrez une adresse de successeur. La seule opération d’urgence autorisée est « remplacer le rôle X par son successeur ». Cela vous permet aussi d’évaluer les successeurs en temps de paix : faire du due diligence, rencontrer ceux qui proposent, etc.
Testez prudemment avant la mise à jour
Une fois que vous avez identifié la cause racine et l’étendue, vous pouvez déployer une mise à jour. C’est souvent le code le plus risqué que vous déployez : écrit sous pression, pour un attaquant qui connaît déjà votre protocole et ses vulnérabilités.
Ne déployez pas sans tests suffisants. Si vous manquez de temps pour un audit, utilisez des relations avec des white hats, ou organisez un concours de 48 heures avant déploiement pour un dernier test de résistance.
Récupération
Réagir rapidement
Les fonds volés ont une demi-vie : une fois la faille exploitée, ils entrent rapidement dans des circuits de blanchiment. Préparez à l’avance des partenaires comme Chainalysis pour suivre en temps réel les adresses des attaquants, et alerter les plateformes lors de transferts inter-chaînes.
Préparez une liste centralisée de contacts : services de conformité, gestionnaires de ponts cross-chain, custodians, et autres tiers pouvant geler des messages cross-chain ou des dépôts en transit.
Négociation
Oui, c’est douloureux, mais il faut tenter de dialoguer avec l’attaquant. Beaucoup de situations peuvent se résoudre par la négociation. Offrez une récompense white hat à durée limitée, et annoncez publiquement qu’en cas de restitution intégrale avant la date limite, aucune action légale ne sera engagée.
Face à des acteurs étatiques, ils peuvent ne pas négocier, mais vous pouvez toujours participer à un programme « bounty white hat », en autorisant des white hats à agir en votre nom pour protéger les fonds, en leur versant un pourcentage des bugs trouvés (payé en réalité par les déposants).
Trouver de bons auditeurs
J’ai déjà écrit que, avec l’évolution des grands modèles de langage, la valeur marginale de l’embauche d’auditeurs diminue. Je maintiens cette position, mais mon point de vue a évolué.
D’abord, un bon auditeur sera toujours en avance sur la courbe. Si vous faites quelque chose d’innovant, votre code et ses vulnérabilités peuvent ne pas être dans leur entraînement, et augmenter simplement le nombre de tokens n’a pas encore prouvé qu’il permet de découvrir efficacement de nouvelles vulnérabilités. Vous ne voulez pas être le premier à tomber sur une vulnérabilité unique.
Ensuite, un avantage sous-estimé est : engager un auditeur, c’est aussi utiliser leur réputation comme garantie. S’ils approuvent en signant, et que vous êtes attaqué, ils ont une forte incitation à aider. Établir une relation avec des professionnels de la sécurité est un atout considérable.
Pratiquer la sécurité opérationnelle
Considérez la sécurité opérationnelle comme un indicateur de succès. Faites des exercices de phishing ; engagez (des partenaires de confiance) en red team pour tester la résistance sociale de votre équipe. Préparez des hardware wallets et appareils de secours pour remplacer tout le multisig si nécessaire. Vous ne voulez pas devoir tout acheter en urgence le jour J.
Mesures d’atténuation
Votre voie de sortie est la limite de perte
Le montant maximal théorique que vous pouvez perdre en exploitant une voie de sortie est celui que cette voie peut causer en cas de vulnérabilité. En termes simples : une fonction de mint sans limite par bloc, c’est un chèque en blanc pour tout exploit de création infinie. Une fonction de redemption sans limite hebdomadaire, c’est un chèque en blanc pour tout solde d’actifs corrompu.
Réfléchissez soigneusement à ces limites. Elles doivent équilibrer votre tolérance maximale aux dégâts et l’expérience utilisateur extrême. En cas de problème, c’est ce qui vous évitera la destruction totale.
Listes blanche (et noire)
La plupart des protocoles disposent de listes de comptes pouvant être appelés, échangés ou recevant des fonds, ainsi que de listes d’interdiction pour certains utilisateurs. Même implicites, ces listes sont des frontières de confiance, qu’il faut formaliser.
Formaliser ces listes permet de mettre en place des mécanismes à deux étapes, créant une friction significative. L’attaquant doit d’abord ajouter à la liste blanche (ou retirer de la liste noire), puis agir. Avoir les deux signifie que pour introduire une nouvelle vulnérabilité, il faut compromettre simultanément deux processus : que le marché autorise (listing / delisting), et que l’action ne soit pas interdite (audit de sécurité).
Récupération