1. Point de départ : l'objectif de la validation n'est pas de « prouver la rentabilité »
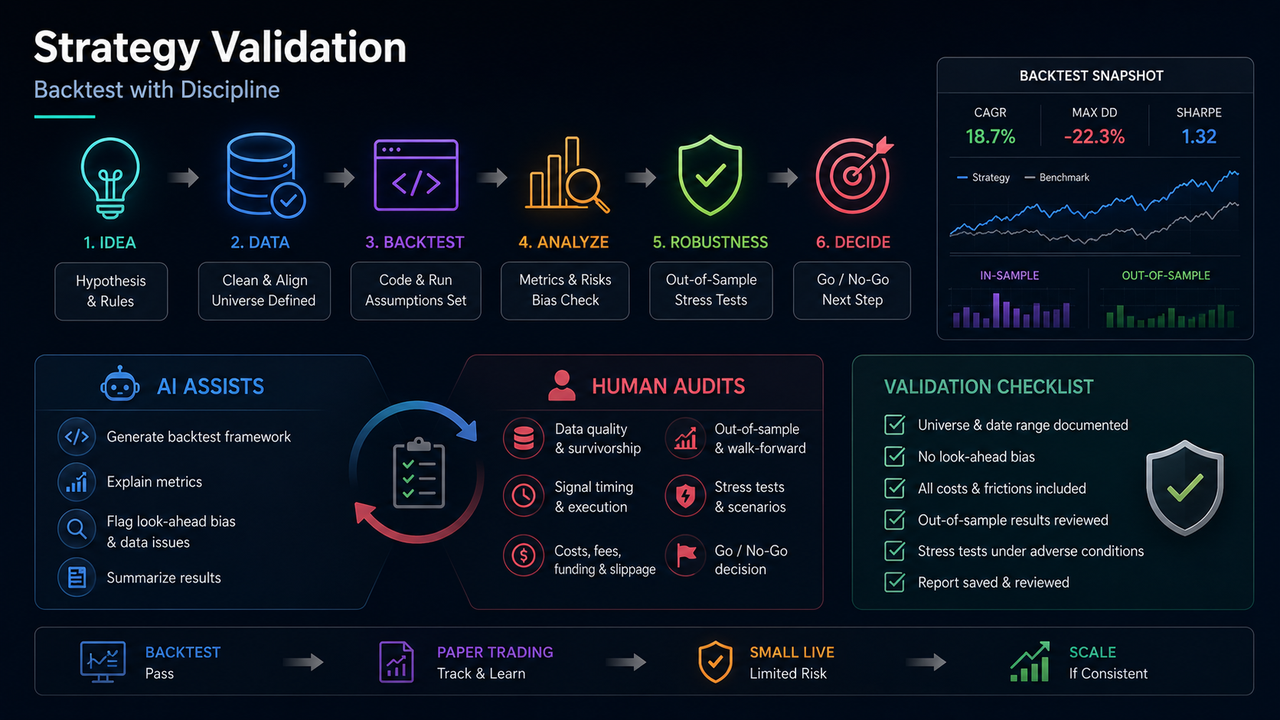
Les deux leçons précédentes ont traité de la division du travail dans le flux de travail et de la structure d'entrée. Cette troisième leçon examine si une idée démontre une cohérence historique. De nombreux échecs ne proviennent pas de directions fondamentalement erronées, mais du fait que les backtests sont traités comme des conclusions sans audit approprié : les données incluent des actifs radiés, les signaux utilisent des informations futures, les coûts sont omis, et les paramètres sont ajustés à plusieurs reprises sur de courts échantillons. L'IA peut accélérer l'écriture de code et l'interprétation des indicateurs, mais ne peut pas statuer sur la validité d'une stratégie. L'objectif plus raisonnable de la validation est le suivant : sous des hypothèses claires, la stratégie n'a pas été falsifiée statistiquement ou en termes de coût — et non pas prouver une rentabilité inévitable par un récit fluide.
2. Division raisonnable du travail pour l'IA dans le backtesting
L'IA est adaptée pour aider à :
-
Générer le code du cadre de backtesting
-
Expliquer la signification du ratio de Sharpe, du drawdown maximal et du taux de gain
-
Lister les points potentiels de biais prospectifs
-
Organiser les tableaux de résultats en résumés textuels
Les tâches qui doivent être effectuées ou révisées indépendamment par des humains comprennent :
-
Vérifier si l'univers contient des survivants
-
Vérifier si les prix existaient avant la cotation
-
Vérifier si les frais, le slippage et les taux de financement sont inclus
-
Vérifier si des tests hors échantillon ou walk-forward sont exécutés
-
Vérifier si les écarts entre le papier et le réel sont pris en compte
L'exécution du code indique uniquement que les étapes techniques sont terminées ; elle ne signifie pas que la stratégie a passé la validation.
3. Nettoyage des données : l'étape la plus fragile du backtesting crypto
Si un backtest n'utilise que des tokens encore actifs aujourd'hui, les résultats sont systématiquement optimistes. Les périodes antérieures à la cotation d'un token ne doivent pas être considérées comme tradables. Les prix, volumes et taux de financement varient selon les exchanges ; les backtests doivent fixer l'échange ou spécifier des règles de synthèse. Les forks, migrations de contrats et renommages de tokens provoquent des ruptures dans les séries de prix et nécessitent un mappage manuel ou une exclusion. Utiliser un seul stablecoin pour la tarification pendant les phases de dépeg peut fausser les mesures de rendement et de risque ; les fenêtres de dépeg majeures doivent être marquées ou expliquées séparément. L'IA doit être tenue de lister les sources de données, les plages temporelles et les définitions de l'univers dans la documentation, et de vérifier chaque élément par rapport aux données brutes — cela importe plus que de simplement tracer des courbes de backtest.
4. Biais prospectifs : alignement temporel entre signaux et exécution
Les biais prospectifs courants incluent :
-
Utiliser les statistiques de l'échantillon complet pour la normalisation mais backtester sur l'échantillon complet
-
Générer des signaux à la clôture du jour mais exécuter à l'ouverture du jour
-
Utiliser des adresses étiquetées comme « smart money » uniquement après les faits
-
Utiliser des données macro révisées comme si elles étaient des valeurs de publication historique
La pratique doit préciser : les signaux générés à t doivent être exécutés à t+1 ou plus tard selon le type de stratégie ; si les données macro ne peuvent pas être obtenues telles qu'initialement publiées, les conclusions correspondantes doivent être nuancées. L'IA peut être tenue d'annoter la disponibilité temporelle des données pour chaque caractéristique dans les commentaires du code ; les humains doivent vérifier ponctuellement les caractéristiques clés pour s'assurer qu'elles précèdent l'exécution d'au moins un jour.
5. Coûts et friction : les backtests sans frais sont invalides par défaut
Les stratégies crypto doivent au minimum inclure les frais de trading, le slippage, les taux de financement perpétuels (si les positions traversent les points de règlement), les taux d'emprunt (si l'effet de levier est utilisé), et les coûts de retrait ou de transfert inter-chaînes si nécessaire. Des scénarios de frais de base et pessimistes (par exemple, des frais doublés) peuvent être utilisés pour les tests de stress. Si les rendements attendus se détériorent fortement ou deviennent négatifs dans des scénarios pessimistes, la stratégie est très sensible aux coûts et ne doit pas être jugée uniquement sur les courbes intra-échantillon. L'IA par défaut utilise souvent des frais nuls ou un seul point de base ; les humains doivent intégrer des tableaux de frais dans les hypothèses de backtest et les rapports.
6. Surapprentissage et hors échantillon : plus de paramètres exigent une plus grande prudence narrative
Les symptômes incluent :
-
N'afficher que la meilleure combinaison après de nombreux ensembles d'indicateurs
-
Régler les paramètres uniquement sur de courts échantillons de marché haussier
-
Des règles très spécifiques sans explication du mécanisme sous-jacent
Les contre-mesures incluent :
-
Réserver des intervalles hors échantillon non utilisés pour le réglage des paramètres
-
Appliquer des tests walk-forward avec fenêtre glissante
-
Simplifier les règles autant que possible, avec des prémisses explicables
Les rapports doivent présenter à la fois les métriques clés intra-échantillon et hors échantillon ; si la performance hors échantillon est significativement inférieure à celle intra-échantillon, le risque de surapprentissage doit être signalé et le passage en direct doit être suspendu. L'IA ne doit pas optimiser les paramètres de manière répétée sans supervision jusqu'à ce que la courbe paraisse bonne — cela revient à un surapprentissage automatisé.
7. Du backtest au trading en direct : progression graduelle plutôt que lancement en une étape
Une échelle à trois niveaux est recommandée. Niveau un : le backtest passe avec un univers, des frais et des résultats hors échantillon documentés. Niveau deux : le trading papier ou simulé enregistre les écarts de prix entre signal et exécution et observe le slippage réel. Niveau trois : trading en direct de petite taille avec limites et stop-loss, en comparant en continu les résultats papier et réels. L'avancement à chaque niveau est décidé par des humains — et non par des modèles recommandant des positions lourdes. L'IA peut générer des listes de contrôle pour chaque niveau, mais ne peut pas se substituer aux décisions d'avancement.
8. Champs minimaux dans un rapport de backtest
Même sans systèmes complexes, un rapport doit inclure :
-
Description de la stratégie en une phrase
-
Intervalle de données et périmètre des actifs
-
Tableau des hypothèses de frais
-
Rendements intra-échantillon et hors échantillon, drawdown maximal, nombre de trades
-
Perte maximale consécutive
-
Liste des problèmes non résolus
-
Conclusion : continuer la validation, mettre en pause ou abandonner
Évitez des déclarations vagues comme « prudemment optimiste » qui ne guident pas l'action. Les backtests et les révisions partagent la même discipline : exécutable, vérifiable, reproductible.
9. Résumé de la leçon
Cette leçon se concentre sur la question de savoir si les idées ont été testées. L'IA est adaptée pour aider à écrire le code de backtest, expliquer les indicateurs, signaler les biais prospectifs et les frais manquants ; elle n'est pas adaptée pour remplacer la confirmation humaine des biais de survie dans les données, de l'alignement signal/exécution, de la performance hors échantillon, ou de la marge sous des coûts pessimistes. Le fait que le code s'exécute et que les courbes intra-échantillon soient attrayantes signifie seulement que les étapes techniques sont accomplies — pas que la mise en œuvre en direct est justifiée. Une voie plus sûre consiste à documenter les backtests, puis à suivre sur papier avant un essai à petite échelle avec tolérance aux erreurs — chaque étape étant décidée par des humains. La prochaine leçon couvrira les événements macro et majeurs on-chain : les périodes avec le plus d'informations, mais aussi les plus susceptibles de résumer à tort des conclusions, nécessitant des limites claires sur ce que l'IA peut aider à préparer et ce qu'elle ne peut pas remplacer pour la vérification.






