1. Point de départ : pourquoi discuter des « limites » avant des « modèles »
La forte volatilité du marché des cryptomonnaies, la multiplicité des sources de données et la rapidité d’exécution rendent le traitement de l’information constamment coûteux. Avec l’arrivée de l’intelligence artificielle dans ce domaine, deux attentes contradictoires lui sont souvent assignées : y voir un « trader intelligent » capable de remplacer la recherche et le timing, ou la réduire à un simple outil de discussion sans intérêt pour le trading en direct. Ces deux positions extrêmes nuisent à la mise en place de processus de travail durables.
Une approche plus concrète consiste à considérer l’IA comme un nœud auxiliaire dans le processus de trading, et non comme le décideur principal. Les nœuds peuvent accélérer l’organisation de l’information, transformer des intuitions en hypothèses testables, générer des frameworks de code pour le backtesting, croiser les listes de contrôle des risques, structurer les comptes rendus de revue et réitérer les plans avant de passer des ordres. En revanche, la vérification de l’authenticité des sources, la validation des statistiques, l’assomption de la responsabilité des positions et l’exécution des transactions doivent rester du côté humain. Cette leçon n’a pas pour but de présenter des produits spécifiques ou de donner des astuces, mais de cartographier le flux de travail afin d’éviter une délégation excessive dans les mauvaises étapes.
2. Ventilation du flux de travail : six positions et leurs attributs fonctionnels
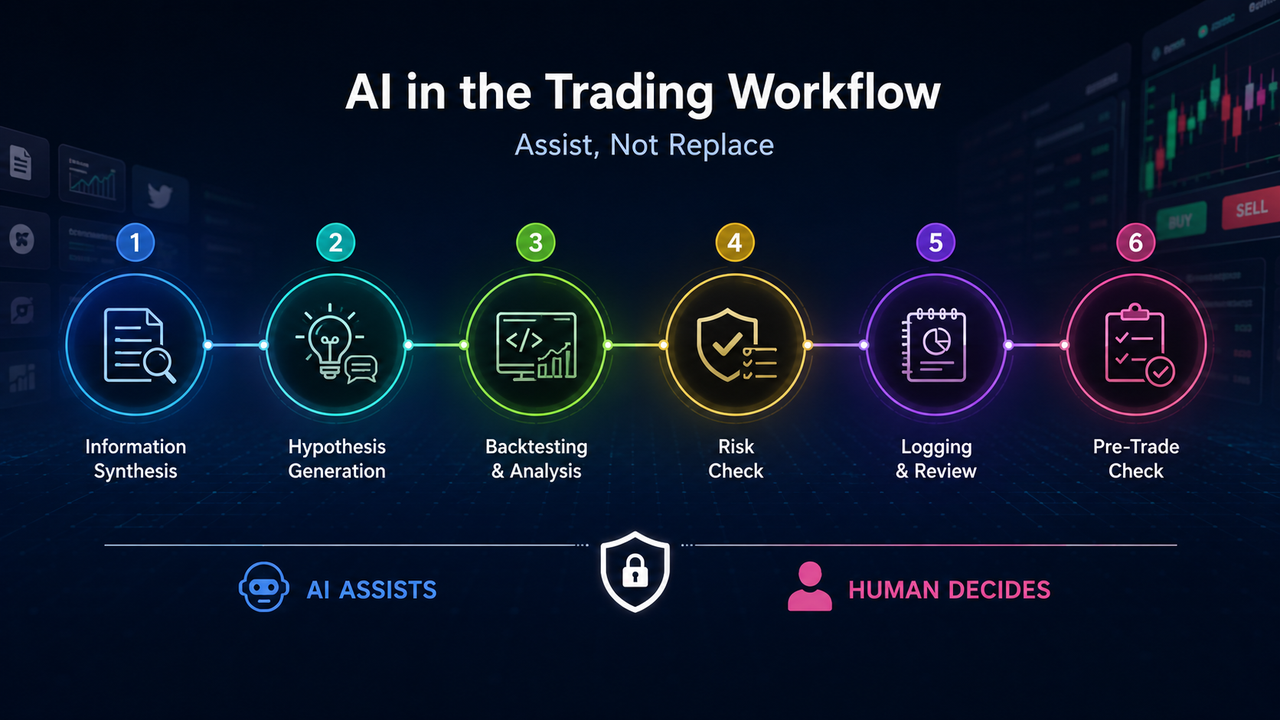
Si l’on décompose un cycle complet, de la recherche à l’exécution en passant par la revue, l’IA trouve sa place idéale dans les six positions suivantes. Chacune correspond à des entrées, des sorties et des types de risques distincts.
-
Position 1 : Organisation de l’information. Les informations de marché sont dispersées entre annonces d’échanges, documents de projet, données on-chain, calendriers macroéconomiques et médias sociaux. L’IA peut les agréger par chronologie, les résumer et juxtaposer des déclarations de sources multiples. Le résultat reste toujours un « brouillon en attente de vérification », jamais une confirmation factuelle. Les résumés doivent renvoyer aux sources originales et inclure dates et contexte ; les déclarations sans source ne doivent pas servir de base de décision pour le trading.
-
Position 2 : Génération d’hypothèses. Le trading commence souvent par un jugement discutable – par exemple, une volatilité croissante dans un environnement macroéconomique donné, ou une force relative dans une classe d’actifs particulière. L’IA peut structurer des idées vagues en schémas comme « Si A se vérifie, attendre B ; si C survient, l’hypothèse est invalidée », et lister les champs de données nécessaires. La valeur d’une hypothèse réside dans sa falsifiabilité ; les récits qui ne peuvent être testés avec des données dans un délai donné doivent rester au stade de la recherche et ne pas influencer les décisions de position.
-
Position 3 : Support au backtesting et statistique. L’IA est bien adaptée pour générer du code de backtesting, expliquer des indicateurs comme le ratio de Sharpe ou le drawdown maximum, et signaler les pièges statistiques courants. Mais la propreté des données, l’inclusion des actifs retirés de la cote, la prise en compte des frais et des taux de financement, et l’absence de biais de regard en avant – tout cela exige un audit indépendant. L’exécution du code ne garantit que la correction syntaxique, pas la validité stratégique.
-
Position 4 : Vérification des contrôles des risques. Limites de risque par transaction, plafonds de levier, proximité de fenêtres de données importantes – ces éléments peuvent être compilés dans une liste de contrôle pré-transaction que l’IA peut analyser en regard des positions et plans en cours. Le contrôle des risques repose fondamentalement sur des contraintes dures ; l’IA peut rappeler et énumérer, mais ne devrait pas approuver automatiquement sans validation à long terme. Savoir si les paramètres correspondent à la volatilité actuelle ou si des droits de veto doivent être exercés dans des conditions défavorables relève du jugement humain.
-
Position 5 : Journalisation et revue. Les notes éparses peuvent être organisées dans un format unifié, catégorisées par type d’erreur et comparées au « plan vs réel ». Les revues doivent s’appuyer sur les enregistrements réels des transactions, non sur la mémoire ; les améliorations doivent être peu nombreuses et actionnables, en distinguant l’échec de stratégie de l’échec d’exécution. L’objectif de la revue est l’itération du flux de travail, pas la rationalisation a posteriori.
-
Position 6 : Vérification pré-exécution. Avant de passer un ordre sur le terminal, il faut réitérer la direction, la quantité, les stop-loss, le mode de marge, et vérifier s’il s’agit uniquement de réductions de positions ; contrôler les conflits avec les calendriers d’événements ou les positions existantes. Les erreurs d’exécution sont les plus coûteuses ; l’IA peut réduire les omissions, mais ne peut se substituer au clic ni à la responsabilité de l’exécutant.
3. Assistance vs. Remplacement : implications institutionnelles de la division du travail
Les six positions forment ensemble un principe : l’IA peut étendre les capacités d’information et de calcul, mais ne doit pas prendre le contrôle du compte. Le tableau ci-dessous reflète non des limitations techniques, mais une structure de responsabilité.
-
Dans l’organisation de l’information, l’IA s’occupe du résumé et du formatage ; les humains vérifient l’authenticité et la fraîcheur des données.
-
Dans la génération d’hypothèses, l’IA fournit des énoncés structurés ; les humains décident de trader et fixent les limites de position.
-
Dans le backtesting, l’IA apporte des cadres et des explications ; les humains gèrent les données, les frais et la validation hors échantillon.
-
Dans le contrôle des risques, l’IA parcourt les listes de contrôle ; les humains exercent leur droit de veto et évaluent la pertinence des paramètres.
-
Dans la revue, l’IA met en forme les enregistrements ; les humains garantissent leur authenticité et prennent des mesures d’amélioration.
-
Dans l’exécution, l’IA réitère les plans ; les humains confirment sur le terminal.
Passer outre la vérification et adopter directement des conclusions issues des modèles revient à substituer un langage fluide à des chaînes de preuves ; se fier à de « bons backtests » sans données ni hypothèses de frais associées traite le récit comme un résultat ; accorder à des API ou scripts d’automatisation un accès illimité sans confirmation multiplie le risque opérationnel. Ces schémas d’usage abusif seront abordés dans les leçons suivantes.
4. Pourquoi les problèmes de limites sont amplifiés dans les scénarios crypto
Comparé à la recherche boursière traditionnelle, les données crypto présentent un bruit bien plus élevé – tags on-chain mêlés aux informations des médias sociaux, fausses nouvelles et images recyclées sont monnaie courante. Le marché évolue rapidement ; la liquidité et les règles peuvent changer en quelques instants. Les chaînes d’outils couvrent échanges, plateformes on-chain et dérivés ; les mesures peuvent varier d’une plateforme à l’autre. Les seuils d’automatisation sont plus bas – dès que les permissions de script deviennent excessives, les erreurs peuvent se répéter en cascade.
Dans les scénarios crypto, la question « Le modèle est-il assez solide ? » n’est donc pas la plus importante ; « À quelles étapes l’utilisons-nous, et quelles garde-fous manuels conservons-nous ? » est bien plus pertinent. Cette leçon pose les bases pour les discussions à venir sur la qualité des données, la discipline de backtesting, l’interprétation des événements et la sécurité de l’automatisation.
5. Résumé de la leçon
-
Le rôle légitime de l’IA dans le trading est d’assister le flux de travail, non de remplacer les décisions ;
-
Les six positions couvrent l’organisation de l’information, la génération d’hypothèses, le support au backtesting, les vérifications des contrôles des risques, la journalisation/revue et la vérification pré-exécution – avec une répartition claire des responsabilités ;
-
Le bruit élevé et le rythme rapide des marchés crypto rendent la gestion des limites plus cruciale que le choix du modèle.
Comprendre cette répartition est indispensable pour intégrer l’IA dans les flux de travail sans amplifier les erreurs. La prochaine leçon abordera comment graduer les données d’entrée, contraindre les formats de sortie via des invites, et éviter d’utiliser des résumés non vérifiés comme bases de trading.
Clause de non-responsabilité
* Les investissements en cryptomonnaies comportent des risques importants. Veuillez faire preuve de prudence. Le cours n'est pas destiné à fournir des conseils en investissement.
* Ce cours a été créé par l'auteur qui a rejoint Gate Learn. Toute opinion partagée par l'auteur ne représente pas Gate Learn.






