Quant trader gemchange_ltd publicó una larga publicación en X en la que detalla su hoja de ruta completa de aprendizaje, titulada “si tuviera que empezar de nuevo, en qué orden aprendería”, desde probabilidad hasta cálculo estocástico, cinco niveles matemáticos, en 18 meses puede pasar de no saber nada a entender realmente la trading cuantitativa. Este artículo proviene de su popular publicación en X, titulada “How I’d Become a Quant If I Had to Start Over Tomorrow”, traducida y reorganizada por Flip.
(Resumen previo: un trader que no depende de comisiones ni de mostrar operaciones, que se basa únicamente en estrategias ganadoras en ciclos de análisis)
(Información adicional: la nota supervivencia de una top trader en criptomonedas, con decenas de miles de palabras: no dejes que “el enriquecimiento rápido” te arruine)
Índice de este artículo
Toggle
- Parte I: Probabilidad, el lenguaje de la incertidumbre
- Parte II: Estadística — aprender a escuchar los datos
- Parte III: Álgebra lineal — la máquina que impulsa todo
- Parte IV: Cálculo y optimización — el lenguaje del cambio
- Parte V: Cálculo estocástico — el verdadero umbral para ser Quant
- Polymarket
- Cómo LMSR fija precios para creencias
- Mapa de carrera en trading cuantitativo: cuatro perfiles
- Caja de herramientas y bibliografía
- Tres cosas que el autor desearía haber sabido antes
Declaración de traducción: Este artículo no constituye consejo de inversión, el mercado tiene riesgos, investigue por su cuenta.
Primero, algunos números: en 2025, el salario total de un Quant recién graduado en las principales instituciones oscila entre 300,000 y 500,000 dólares. La contratación en AI/ML en finanzas crece un 88% anual. ¿Existe un mapa para este camino?
Este artículo es lo que el autor hubiera querido que alguien le entregara al comenzar. La hoja de ruta está ordenada en “el orden en que deberías aprender”, cada concepto se construye sobre el anterior, como en un videojuego: no puedes saltarte niveles. Pero si te lo tomas en serio, no viendo videos aburridos de introducción a finanzas en YouTube (que solo son pérdida de tiempo), sino resolviendo problemas y practicando, en unos 18 meses podrás pasar de no entender nada a entender algunas cosas de verdad.
Deja a un lado todo el conocimiento que crees tener sobre trading. La mayoría piensa que el trading cuantitativo es elegir acciones, tener una opinión sobre Tesla, predecir informes financieros. Pero no es así. Quant trading es matemáticas. Lo que haces es analizar relaciones estadísticas, identificar ineficiencias en precios, y aprovechar las ventajas estructurales que surgen del hecho de que “el mercado está dirigido por personas que cometen errores sistemáticos”.
Parte I: Probabilidad, el lenguaje de la incertidumbre
Todo en finanzas cuantitativas puede reducirse a una pregunta: ¿Cuál es la tasa de éxito? ¿Estoy en ventaja?
Eso es probabilidad. Si no entiendes profundamente la probabilidad, lo que viene después en este artículo no tendrá sentido para ti.
Probabilidad condicional: la forma de pensar del Quant
La gente común piensa en absolutos: esto es verdad o no. El Quant piensa en condicionales: ¿qué probabilidad hay de que esto sea cierto, dado lo que sé ahora?
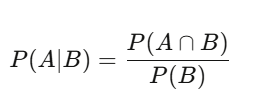
P(A|B) = P(A∩B) / P(B) — Dado que B ocurre, la probabilidad de A es la probabilidad de que ambos ocurran, dividida por la probabilidad de B. Parece simple, pero tiene un impacto profundo. Una acción tiene un 60% de días en alza — esa es la probabilidad base. Pero en días con volumen superior a la media, la probabilidad de subida es del 75%. Esa probabilidad condicional es la información relevante; el 60% original está lleno de ruido.
Teorema de Bayes: actualiza tus juicios en tiempo real
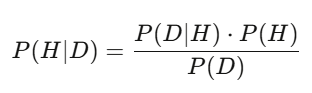
La probabilidad posterior = (la probabilidad de ver estos datos si la hipótesis es cierta) × la probabilidad previa ÷ (la probabilidad total de ver estos datos bajo cualquier hipótesis). En la práctica, se calcula mediante muestreo de Monte Carlo. La lógica es la misma: Bayes es la forma de ajustar en tiempo real tus juicios ante nueva información. Si un modelo dice que una acción vale 50 dólares, y sale un informe con ingresos un 3% superiores a lo esperado, la probabilidad posterior aumenta. Quien actualiza más rápido y con mayor precisión, gana.
Valor esperado y varianza: tus dos mejores amigos
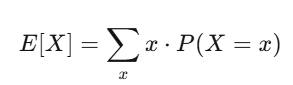
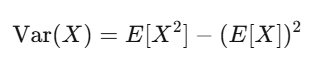
El valor esperado refleja la fuerza de tu creencia; la varianza, el riesgo. Si tu estrategia tiene un valor esperado positivo y puedes soportar las oscilaciones que genera la varianza, probablemente ganarás dinero.
Tarea nivel 1 (2 horas diarias, 3-4 semanas)
- Leer: Blitzstein & Hwang, Introduction to Probability (PDF gratuito de Harvard), resolver todos los problemas de capítulos 1-6
- Programar: simular 10,000 lanzamientos de moneda, usar visualización para verificar la ley de los grandes números
- Programar: implementar un actualizador bayesiano, que tome una priori y una función de verosimilitud, y devuelva la posterior
import numpy as np
import matplotlib.pyplot as plt
# Ley de los grandes números: la media muestral converge a la verdadera probabilidad
np.random.seed(42)
lanzamientos = np.random.choice([0, 1], size=10000, p=[0.5, 0.5])
media_muestral = np.cumsum(lanzamientos) / np.arange(1, 10001)
plt.figure(figsize=(10, 4))
plt.plot(media_muestral, linewidth=0.7)
plt.axhline(y=0.5, color='r', linestyle='--', label='Verdadera probabilidad')
plt.xlabel('Número de lanzamientos')
plt.ylabel('Media muestral')
plt.title('Demostración práctica de la ley de los grandes números')
plt.legend()
plt.savefig('lln.png', dpi=150)
print(f"Después de 10,000 lanzamientos: {media_muestral[-1]:.4f} (verdadero: 0.5)")
Parte II: Estadística — aprender a escuchar los datos
Una vez que entiendes el lenguaje de la probabilidad, debes aprender a extraer información de los datos. La primera lección de la estadística es: la mayoría de los descubrimientos que parecen significativos, en realidad son ruido.

Pruebas de hipótesis: tu detector de ruido
Construiste un modelo con un retorno anualizado del 15%. ¿Es real? Plantea la hipótesis nula H₀: “el retorno esperado de esta estrategia es cero”, calcula la estadística de prueba y obtiene el p-valor. Pero atención: si pruebas 1000 estrategias aleatorias, por pura suerte, unos 50 tendrán p < 0.05. Es el problema de las comparaciones múltiples. La solución es la corrección de Bonferroni (dividir el nivel de significancia por el número de pruebas) o el control de la tasa de descubrimientos falsos con Benjamini-Hochberg. Muchos principiantes sobreestiman lo que han encontrado. Los primeros 10 resultados son solo ruido. Acepta esto y ahorra mucho dinero.
Regresión: descomponer los retornos
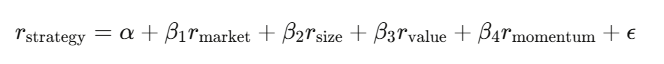
La regresión lineal y = Xβ + ε es la herramienta principal en finanzas. Regressas los retornos de tu estrategia contra factores de riesgo conocidos; la intersección α es tu retorno excesivo, lo que no puede ser explicado por los factores conocidos.
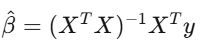
Si tras controlar los factores α es cero, tu “ventaja” es solo exposición de mercado disfrazada. Usa errores estándar de Newey-West, porque los datos financieros tienen autocorrelación y heterocedasticidad. Usar errores estándar normales sería como conducir con un parabrisas roto a alta velocidad.
Estimación por máxima verosimilitud (MLE)
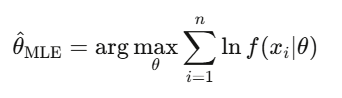
Es la forma en que la finanza ajusta modelos: para calibrar modelos GARCH, estimar parámetros de saltos, o ajustar precios de opciones a los precios de mercado. Cuando alguien dice “calibrar” un modelo, casi siempre se refiere a MLE.
Tarea nivel 2 (4-5 semanas)
- Leer: Wasserman, All of Statistics, capítulos 1-13
- Descargar datos reales de retornos (con yfinance), probar normalidad (seguramente fallará), ajustar distribuciones t con MLE y comparar resultados
- Usar statsmodels para hacer regresión de los factores Fama-French en una cartera de acciones
- Implementar prueba de permutación: barajar las fechas 10,000 veces, comparar rendimiento permutado con el real
Parte III: Álgebra lineal — la máquina que impulsa todo
La álgebra lineal puede parecer aburrida, pero es la máquina que impulsa todo: construcción de carteras, análisis de componentes principales, redes neuronales, estimación de covarianzas, modelos de factores. Sin dominio de matrices, no hay Quant.

Pensamiento matricial
La matriz de covarianza Σ captura cómo se mueven los activos en relación unos con otros. Para 500 acciones, Σ es una matriz 500×500 con 125,250 valores únicos. La varianza de la cartera se puede expresar como w’Σw; esta forma cuadrática está en el núcleo de la teoría de Markowitz, gestión de riesgos y todo lo demás.
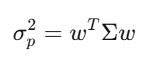
Valores propios: lo que realmente importa
En el universo de 500 acciones, los primeros 5 vectores propios explican el 70% de la varianza total. El resto es ruido. La primera vez que usaste descomposición en valores propios, cambió todo: es reducción de dimensión y la base para la inversión en factores.
Tarea nivel 3 (4-6 semanas)
- Ver: el curso completo de álgebra lineal de Gilbert Strang en MIT 18.06, sin saltarse ninguna parte
- Leer: Strang, Introduction to Linear Algebra, resolver todos los ejercicios
- Hacer PCA en los retornos del S&P 500, graficar el espectro de valores propios, identificar los tres principales componentes
- Implementar desde cero la optimización de media-varianza de Markowitz
import numpy as np
import cvxpy as cp
np.random.seed(42)
n_assets = 10
mu = np.random.uniform(0.04, 0.15, n_assets)
A = np.random.randn(n_assets, n_assets) * 0.1
cov = A @ A.T + np.eye(n_assets) * 0.01
w = cp.Variable(n_assets)
objective = cp.Minimize(cp.quad_form(w, cov))
constraints = [
mu @ w >= 0.08, # retorno mínimo
cp.sum(w) == 1, # inversión total
w >= -0.1, # máximo 10% en corto
w <= 0.3 # máximo 30% en largo
]
prob = cp.Problem(objective, constraints)
prob.solve()
ret = mu @ w.value
vol = np.sqrt(w.value @ cov @ w.value)
sharpe = (ret - 0.03) / vol
print(f"Retorno de la cartera: {ret:.4f}")
print(f"Volatilidad de la cartera: {vol:.4f}")
print(f"Índice de Sharpe: {sharpe:.4f}")
Parte IV: Cálculo y optimización — el lenguaje del cambio
El cálculo diferencial es el lenguaje que describe el cambio. En finanzas, todo cambia: precios, volatilidad, correlaciones, la distribución de probabilidad en cada instante. El cálculo describe y aprovecha estos cambios. La derivada aparece en la retropropagación de redes neuronales y en el cálculo de las griegas de las opciones.
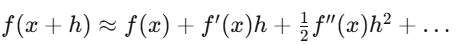
La serie de Taylor es la aproximación de primer orden para Delta hedging, Gamma añade la corrección de segundo orden. El cálculo de Itô difiere del clásico porque los términos de segundo orden en procesos estocásticos no desaparecen.
Tarea nivel 4 (4-5 semanas)
- Leer: Boyd & Vandenberghe, Convex Optimization (PDF gratuito de Stanford), capítulos 1-5
- Implementar desde cero descenso de gradiente para minimizar la función de Rosenbrock
- Usar cvxpy para resolver un problema de optimización de cartera con costos de transacción
Parte V: Cálculo estocástico — el verdadero umbral para ser Quant
Antes de aprender cálculo estocástico, solo eres un científico de datos que le gusta finanzas. Después, serás Quant. Aquí aprendes a modelar la incertidumbre en tiempo continuo, derivar la ecuación de Black-Scholes desde los principios, y entender por qué el mercado de derivados que vale billones funciona así.

Movimiento browniano: formalizando la aleatoriedad
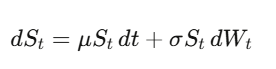
El movimiento browniano (proceso de Wiener) W_t es una caminata aleatoria continua en el tiempo. La clave — en la que todo se basa — es que dW_t tiene “tamaño” de √dt, es decir, (dW_t)² = dt. Parece un detalle técnico, pero es la verdad más importante en finanzas cuantitativas.
La fórmula de Itô
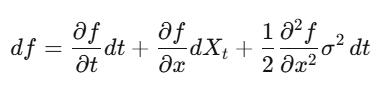
En cálculo clásico, haces expansión de Taylor y los términos de segundo orden (dx)² se ignoran. Pero en procesos estocásticos, (dW_t)² = dt es un término de primer orden que no puedes omitir. La fórmula de Itô dice: df = (∂f/∂t + μ∂f/∂x + ½σ²∂²f/∂x²)dt + σ∂f/∂x dW_t. Aplicándola a los precios de opciones, obtienes la ecuación de Black-Scholes.
Derivando la ecuación de Black-Scholes desde cero
Paso 1: Sea V(S,t) el precio de la opción, y aplicamos Itô a V.
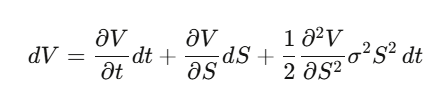
Paso 2: Construimos una cartera de cobertura delta Π = V − (∂V/∂S)·S, y calculamos dΠ — los términos en dW_t se cancelan perfectamente, y esta cartera es localmente sin riesgo.
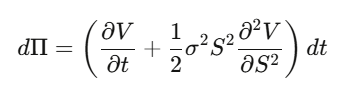
Paso 3: La cartera sin riesgo debe crecer a la tasa libre de riesgo.
Paso 4: Sustituimos y simplificamos, obteniendo la PDE de Black-Scholes.
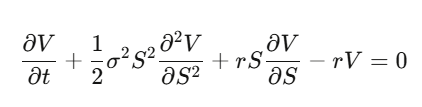
Lo que pasa: la tasa de deriva μ desaparece. El precio de la opción no depende del retorno esperado del activo subyacente, ni de la aversión al riesgo. Se puede valorar asumiendo que todos son neutrales al riesgo. La primera vez que entiendes esto, te quedas con la cabeza hecha un lío.
Para una opción europea con precio de ejercicio K y vencimiento T, la solución del PDE es:
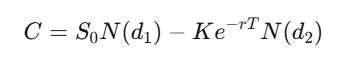
donde d₁=
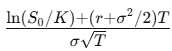
d₂=
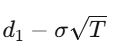
Las griegas
- Delta Δ: por cada dólar que sube el precio del activo, cuánto se mueve la opción, es tu ratio de cobertura
- Gamma Γ: velocidad de cambio del Delta, tu exposición convexa
- Theta Θ: pérdida de valor temporal, generalmente negativo en posiciones largas
- Vega V: sensibilidad a la volatilidad, aquí se gana la mayor parte del dinero en derivados
- Rho ρ: sensibilidad a la tasa de interés
import numpy as np
from scipy.stats import norm
def black_scholes(S, K, T, r, sigma, option_type='call'):
d1 = (np.log(S/K) + (r + sigma**2/2)*T) / (sigma*np.sqrt(T))
d2 = d1 - sigma*np.sqrt(T)
if option_type == 'call':
return S*norm.cdf(d1) - K*np.exp(-r*T)*norm.cdf(d2)
else:
return K*np.exp(-r*T)*norm.cdf(-d2) - S*norm.cdf(-d1)
Función para calcular el precio con Black-Scholes y Monte Carlo:
def monte_carlo_option(S0, K, T, r, sigma, n_sims=500000):
Z = np.random.standard_normal(n_sims)
ST = S0 * np.exp((r - sigma**2/2)*T + sigma*np.sqrt(T)*Z)
payoffs = np.maximum(ST - K, 0)
precio = np.exp(-r*T) * np.mean(payoffs)
error = np.exp(-r*T) * np.std(payoffs) / np.sqrt(n_sims)
return precio, error
S, K, T, r, sigma = 100, 105, 1.0, 0.05, 0.2
bs = black_scholes(S, K, T, r, sigma)
mc, err = monte_carlo_option(S, K, T, r, sigma)
print(f"Black-Scholes: ${bs:.4f}")
print(f"Monte Carlo: ${mc:.4f} ± {err:.4f}")
Tarea nivel 5 (6-8 semanas, la más difícil)
- Leer: Shreve, Stochastic Calculus for Finance II, estándar de oro
- Alternativa: Arguin, A First Course in Stochastic Calculus, más reciente y accesible
- Derivar: para f(S)=ln(S), usando Itô, obtener el término −σ²/2
- Derivar: la ecuación completa de Black-Scholes desde la argumentación de cobertura delta
- Programar: implementar desde cero Black-Scholes y compararlo con Monte Carlo, verificando convergencia
Polymarket
El mercado más interesante del mundo actualmente, y su matemática conecta todos los temas del artículo:
Probabilidad, teoría de la información, optimización convexa, programación entera.
Cómo LMSR fija precios para creencias
Regla de puntuación de mercado logarítmica (LMSR)
Inventada por Robin Hanson, para impulsar mercados de predicción automatizados.
Para n resultados, la función de coste es:
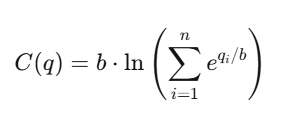
donde:
- q_i: cantidad de “acciones pendientes” emitidas para el resultado i
- b: parámetro de liquidez
El precio del resultado i es:
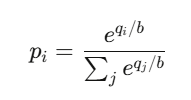
que es la función softmax —
igual que en las redes neuronales clasificadoras.
Sus propiedades:
- La suma de todos los precios siempre es 1
- Cada precio está en (0,1)
- Siempre hay precios, ofreciendo liquidez infinita
El máximo riesgo para el creador del mercado (market maker) está limitado a:
b × ln(n)
Mapa de carrera en trading cuantitativo: cuatro perfiles
Quant Researcher (QR): Busca patrones en datos a nivel petabytes, construye modelos predictivos, diseña estrategias. Requiere doctorado en matemáticas, estadística o ML, o destacar mucho en la universidad. En instituciones como Jane Street, QR tiene acceso a decenas de GPUs.
Quant Developer/Engineer (QD): Construye plataformas de trading, motores de ejecución, pipelines de datos en tiempo real, para que los modelos de los investigadores puedan operar. Necesita C++, Rust o Python en producción, sistemas de baja latencia.
Quant Trader (QT): Toma decisiones, gestiona capital, controla riesgos, hace juicios en tiempo real. La variación salarial es grande, los mejores años alcanzan cifras de ocho dígitos.
Risk Quant: Verifica modelos, calcula VaR, realiza pruebas de estrés, cumple regulaciones. Es un camino más estable, pero con techo más bajo. Los roles emergentes en IA/ML para generar señales (deep learning) crecen rápido: en 2025, la contratación en este campo aumenta un 88% anual.
Salarios en las principales firmas de EE. UU. (Jane Street, Citadel, HRT):
- Recién graduados: $300,000–$500,000 + paquete total
- Nivel medio (3-7 años): $550,000–$950,000
- Senior (8+ años): $1,000,000–$3,000,000+
- Estrellas (PMs): $3,000,000–$30,000,000+
En firmas medianas (Two Sigma, DE Shaw), un recién graduado gana unos $250,000–$350,000 en total. En Jane Street, el salario medio en 2025 alcanza aproximadamente 1.4 millones de dólares anuales, en promedio.
Proceso de entrevista: revisión de CV → prueba en línea (Zetamac para cálculo mental, objetivo más de 50 puntos, preguntas lógicas) → entrevista telefónica (problemas de probabilidad, juegos de azar) → Superday (3-5 rondas, simulaciones, código, pizarra). Jane Street diseña preguntas difíciles, que no se pueden resolver sin pistas o colaboración. La mayoría de los pasantes recientes vienen de ingeniería informática (más del 66%), y solo un tercio de matemáticas; conocimientos financieros no son imprescindibles.
Para prepararse, se recomienda principalmente el Green Book de Xinfeng Zhou (más de 200 preguntas reales de entrevistas en finanzas cuantitativas), junto con QuantGuide.io (versión cuant de LeetCode) y Brainstellar para practicar.
Caja de herramientas y bibliografía
Stack tecnológico en Python: pandas/polars (Polars es 10-50 veces más rápido en grandes datos), numpy/scipy, xgboost/lightgbm, pytorch, cvxpy, QuantLib, statsmodels, NautilusTrader o vectorbt para backtesting.
Fuentes de datos gratuitas: yfinance, Finnhub (60 solicitudes por minuto), Alpha Vantage. Para nivel intermedio, Polygon.io ($199/mes, con latencia <20ms). Para empresas, Bloomberg Terminal (~$32,000/año).
Bibliografía (ordenada):
- Matemáticas básicas: Blitzstein & Hwang, Probability → Strang, Linear Algebra → Wasserman, All of Statistics → Boyd & Vandenberghe, Convex Optimization → Shreve, Stochastic Calculus I & II
- Finanzas cuantitativas: Hull, Options, Futures and Other Derivatives → Natenberg, Option Volatility & Pricing → López de Prado, Advances in Financial Machine Learning → Ernest Chan, Market Mysteries de Zuckerman
- Entrevistas: Zhou, Green Book → Crack, Heard on the Street → Joshi, Quant Interview Questions
- Competencias: Jane Street Kaggle (premio de 100,000 USD), WorldQuant BRAIN (más de 100,000 usuarios, compra señales alpha), Citadel Datathon (acceso rápido a empleo)
Tres cosas que el autor desearía haber sabido antes
El error de estimación es el enemigo real. Apostar con Kelly completo, Markowitz sin restricciones, modelos ML con demasiadas características — todos fracasan por lo mismo: sobreajustar el ruido en la estimación de parámetros. La matemática funciona perfectamente con parámetros reales. Pero nunca tienes parámetros reales. La diferencia entre teoría y práctica siempre es el error de estimación. Los mejores Quant son quienes respetan esto de verdad.
Las herramientas ya son democráticas, pero el juicio no. Cualquier persona puede acceder a QuantLib, Polygon.io y PyTorch. La tecnología es necesaria, pero no suficiente. La ventaja está en datos únicos, modelos únicos o capacidades de ejecución únicas, no en mejores instalaciones con pip.
Las matemáticas son la muralla protectora. La IA puede programar, proponer estrategias, pero solo los que entienden por qué el Itô tiene ese término extra, o pueden demostrar que en la medida neutral al riesgo el precio descontado es un martillo (martingale), o saben si la relajación convexa en problemas de arbitraje de cartera es fuerte o débil — esa fluidez matemática distingue a los Quant que crean ventajas de los que solo las toman prestadas. La ventaja prestada tiene fecha de caducidad.

