En breve
- OpenAI lanzó GPT-5.4 en medio de la creciente reacción contra QuitGPT por su contrato con la IA del Pentágono.
- GPT-5.4 añade una ventana de contexto de 1 millón de tokens, razonamiento más fuerte y capacidades agenticas.
- Los usuarios empresariales se benefician más, ya que GPT-5.4 ofrece agentes de IA más rápidos con menos tokens.
OpenAI comenzó a desplegar GPT-5.4—su modelo más avanzado hasta la fecha—el jueves, mientras la compañía intenta contener una crisis de relaciones públicas que ha llevado a unos 2.5 millones de usuarios a tomar acciones contra la empresa, ya sea cancelando su suscripción o compartiendo el boicot en redes sociales.
El movimiento QuitGPT explotó después de que OpenAI revelara un acuerdo con el Departamento de Defensa de EE. UU., horas después de que Anthropic se retirara públicamente del mismo contrato—ganándose la desaprobación pública del presidente Trump y otros funcionarios gubernamentales.
El punto de discordia de Anthropic: El DoD se negó a incluir un lenguaje que prohibiera explícitamente el despliegue de armas autónomas y la vigilancia masiva de ciudadanos estadounidenses.
OpenAI aceptó el acuerdo de todos modos. El CEO Sam Altman, quien ha estado respondiendo preguntas sobre la aparente brecha entre las líneas rojas de seguridad declaradas por su empresa y el lenguaje real del contrato, necesita que esos usuarios regresen.
Y entra GPT-5.4… solo dos días después de la introducción de GPT-5.3.
El nuevo modelo consolida capacidades de razonamiento, codificación y agentes en un solo lanzamiento. También tiene una capacidad de contexto de un millón de tokens, lo que permite a los usuarios manejar mayor cantidad de información en una sola sesión.
En papel, los números parecen prometedores. En GDPval—una prueba de referencia que evalúa trabajos de conocimiento en 44 ocupaciones—GPT-5.4 iguala o supera a profesionales en el 83.0% de las comparaciones, frente al 70.9% de GPT-5.2. El uso de computadoras es el mayor avance: en OSWorld-Verified, que mide la capacidad de operar un escritorio mediante capturas de pantalla y acciones de teclado/mouse, GPT-5.4 alcanza un 75.0% de éxito frente al 47.3% de GPT-5.2—y supera la línea base humana del 72.4%.
En BrowseComp, una prueba de investigación en la web profunda, sube 17 puntos porcentuales respecto a GPT-5.2. La ventana de contexto de 1 millón de tokens y una función de redirección en medio de la respuesta—que permite a los usuarios redirigir el modelo mientras aún está pensando—completan las características principales.
Esta función ahorra tiempo y cálculo al evitar la necesidad de descartar todos los tokens generados previamente cuando se detecta un error.
¿Quién se beneficiará de GPT 5.4?
Es importante notar que algunos benchmarks comparan principalmente GPT-5.4—y la mayoría de las veces, el razonamiento se configuró en esfuerzo extra alto, que los usuarios gratuitos y Plus no pueden disfrutar—con GPT-5.2, omitiendo completamente GPT-5.3.
Para los usuarios que ya usan GPT-5.3, varias mejoras pueden parecer más incrementales de lo que muestran las gráficas.
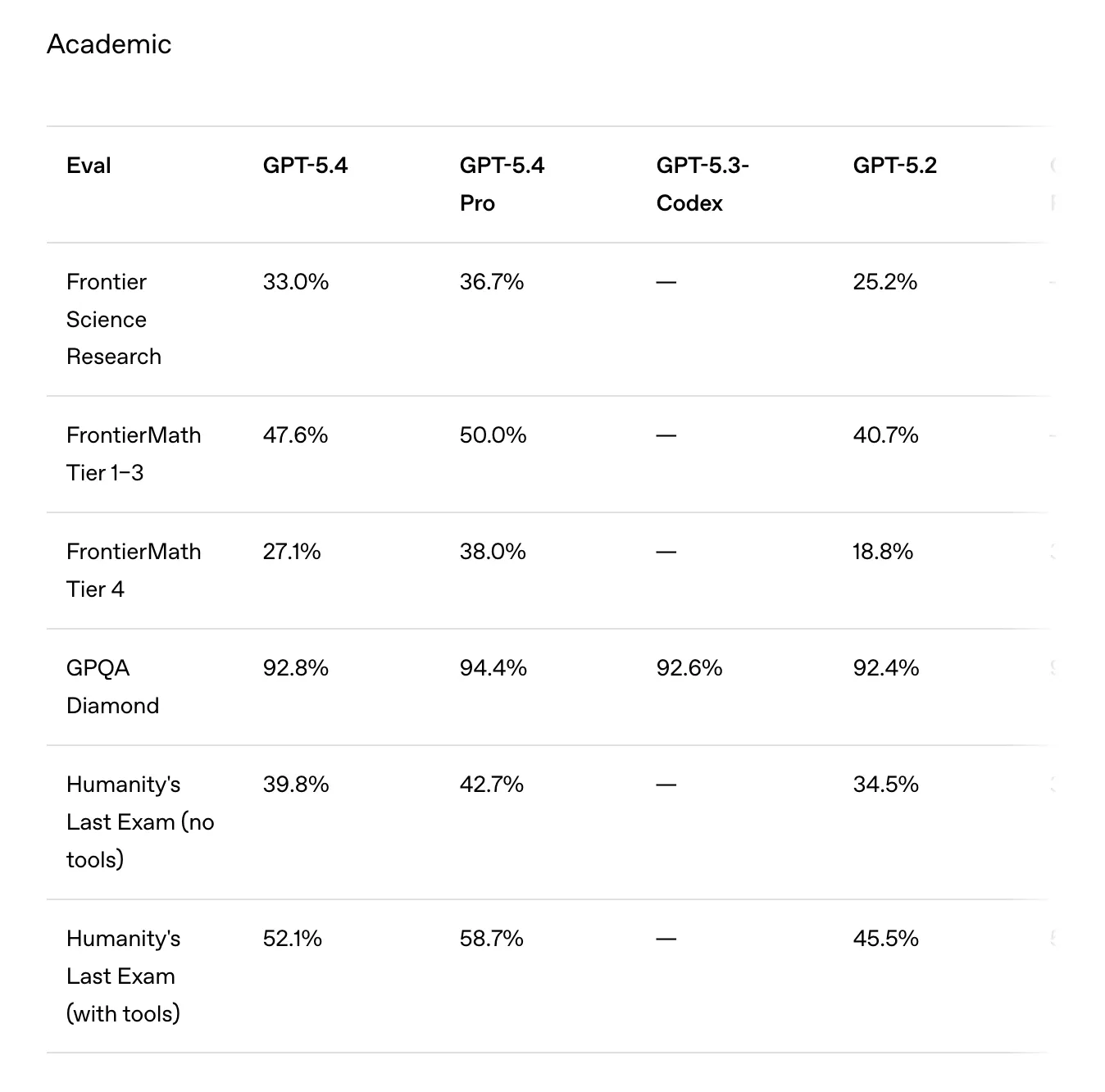
Los programadores tienen más motivos para moderar expectativas: en SWE-Bench Pro, la mejora de GPT-5.3-Codex (56.8%) a GPT-5.4 (57.7%) es apenas un error de redondeo. El modelo también afirma que requiere significativamente menos tokens para completar tareas en comparación con GPT-5.2.
“GPT‑5.4 es nuestro modelo de razonamiento más eficiente en tokens hasta ahora, usando significativamente menos tokens para resolver problemas en comparación con GPT‑5.2”, dijo OpenAI.
Dicho esto, cualquier mejora en este campo es positiva para los desarrolladores que usan modelos de OpenAI vía API y se les cobra por token utilizado. Un modelo con una cadena de pensamiento eficiente puede ofrecer los mismos resultados a una fracción del costo, en comparación con un modelo que tiende a sobrepensar para asegurarse de llegar a la conclusión correcta.
Hay otra complicación para quienes esperan usar el nuevo modelo ahora mismo: OpenAI dice que GPT-5.4 se lanzará hoy, pero aún no estaba disponible al momento de escribir esto, por lo que probablemente se esté desplegando lentamente. Para la mayoría de los usuarios, el mejor modelo es GPT 5.3, y solo puede usarse para respuestas instantáneas, lo que significa que proporciona respuestas que no requieren demasiado esfuerzo.
Los usuarios que dependen del pensamiento—la terminología de OpenAI para razonamiento extendido en tareas complejas—siguen en GPT-5.2. En otras palabras, los usuarios más propensos a exprimir los límites del modelo son los últimos en obtenerlo.
Los beneficiarios más claros son los usuarios empresariales que realizan trabajos con mucho documento. En una prueba interna de modelado de hojas de cálculo, GPT-5.4 obtuvo un 87.3% frente al 68.4% de GPT-5.2. La firma de investigación legal Harvey dijo que obtuvo un 91% en su evaluación BigLaw Bench. Mainstay, que opera agentes en 30,000 portales de impuestos de propiedad, reportó un 95% de éxito en el primer intento y sesiones que funcionan aproximadamente el triple de rápido usando alrededor del 70% menos de tokens.
Ese tipo de argumento de eficiencia podría ser importante para los equipos de compras empresariales, pero resulta más difícil de convencer para el usuario individual que está reconsiderando si eliminar su cuenta.
Aviso legal: La información de esta página puede proceder de terceros y no representa los puntos de vista ni las opiniones de Gate. El contenido que aparece en esta página es solo para fines informativos y no constituye ningún tipo de asesoramiento financiero, de inversión o legal. Gate no garantiza la exactitud ni la integridad de la información y no se hace responsable de ninguna pérdida derivada del uso de esta información. Las inversiones en activos virtuales conllevan riesgos elevados y están sujetas a una volatilidad significativa de los precios. Podrías perder todo el capital invertido. Asegúrate de entender completamente los riesgos asociados y toma decisiones prudentes de acuerdo con tu situación financiera y tu tolerancia al riesgo. Para obtener más información, consulta el
Aviso legal.

