Коротко
- Верховний суд Колумбії відхилив касаційну скаргу після того, як детектори ШІ визначили її як машинно згенеровану.
- Адвокати пропустили ухвалу через ті самі інструменти і виявили, що вона також виглядає як написана ШІ.
- Експерти та дослідження показали, що програми для виявлення ШІ дають ненадійні та непослідовні результати.
Верховний суд Колумбії відмовив у касаційній скарзі, стверджуючи, що вона була згенерована ШІ. Але той самий інструмент, який суд використовував для визначення походження скарги, повідомив, що й його власне рішення також отримало допомогу від генеративного ШІ.
Чи це подвійні стандарти суду, чи несправні інструменти?
“З огляду на обґрунтоване підозру, що подана адвокатом коротка не була складена самим юристом, суд передав текст у Winston AI,” — пояснив суд. “Аналіз показав, що документ містить лише 7% людського контенту, що свідчить про значний вплив автоматичного написання і веде до висновку, що він був створений за допомогою штучного інтелекту.”
Після аналізу за допомогою інших інструментів, що давали подібні результати, суд постановив, що “оскільки подання не може вважатися належним процесуальним документом, його відхилення є необхідним.”
Але коли судове рішення піддалося такій самій перевірці з боку юридичних експертів, результати були схожими.
“Я подав текст Auto AP760/2026 Верховного суду на той самий Winston AI, що згаданий у постанові,” — написав адвокат Емануель Алесіо Вельаскес у X у вівторок. “Результат: документ містить 93% тексту, згенерованого ШІ.”
> Я подав текст auto AP760/2026 Верховного суду на той самий Winston AI, що згаданий у постанові. Результат: документ містить 93% “тексту, згенерованого ШІ”. https://t.co/xTm2jI4d70 pic.twitter.com/lpSHuRjEZ4
>
> — Емануель Алесіо Вельаскес (@EmmanuVeZe) 3 березня 2026
“Якщо сама ухвала, яка засуджує використання штучного інтелекту, отримує такий відсоток, то методологічна нестійкість використання цих детекторів як аргументативної підтримки стає очевидною,” — зазначив він у наступному твіті.
За кілька годин після публікації судового рішення у Твіттері, адвокати почали проводити власні тести. Пост Вельаскеса став вірусним у юридичних колах, набравши десятки тисяч переглядів.
Ми також протестували вердикт суду, і спочатку ситуація виглядала не дуже добре. Коли GPTZero проаналізував лише перші слова тексту суду, він показав 100% ШІ.
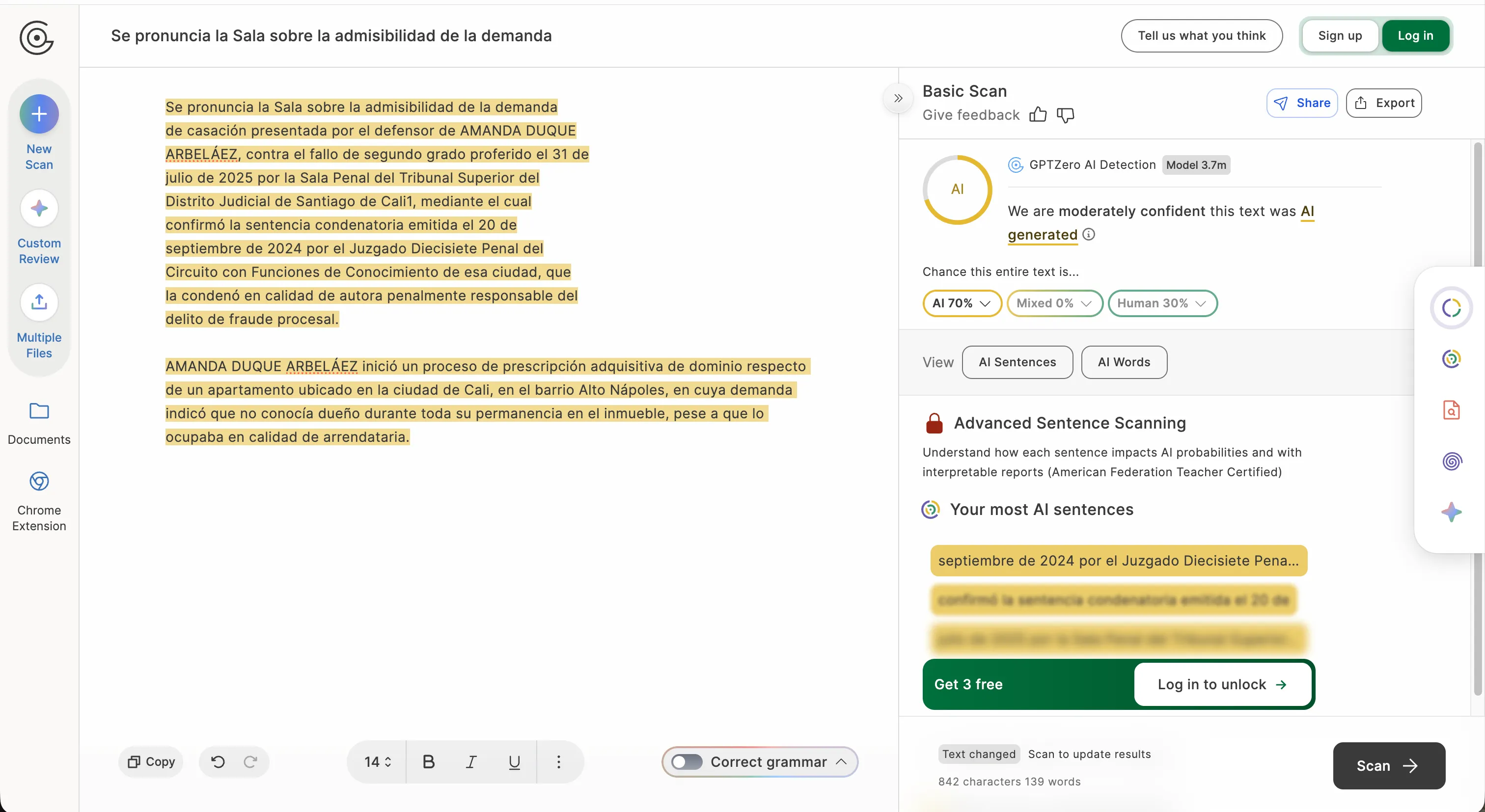
Коли той самий інструмент обробив довшу версію, включаючи розділ з фактичним фоном, він повністю змінив свою оцінку: 100% людський.
Інструмент просто не достатньо надійний, щоб йому можна було довіряти у суді або в ситуаціях, що вимагають високої впевненості.
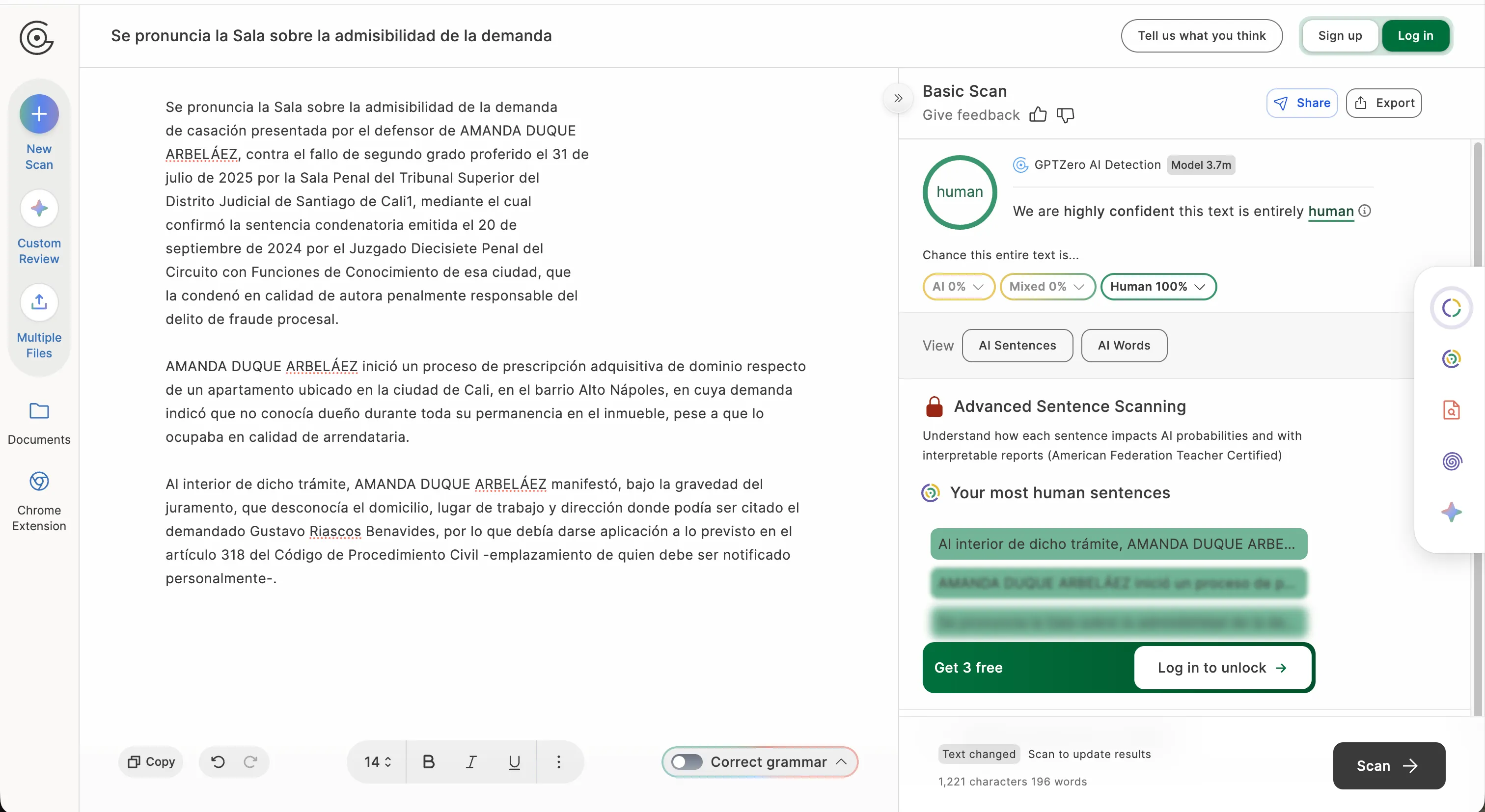
Колумбійські адвокати швидко провели свої експерименти. Адвокат з кримінального захисту та лектор Андрес Ф. Аранго Г. подав судовий документ 2019 року, який був зроблений за кілька років до появи великих мовних моделей, здатних навіть виявляти такі тексти, і він показав 95% генерації ШІ.
“Ці інструменти потім пропонують вам ‘людинізувати’ статтю через платні сервіси,” — написав він у X, зазначаючи очевидний комерційний мотив у бізнес-моделі детекції.
Ніколас Бульвес провів свою бакалаврську роботу 2020 року на тему довіри в кримінальному праві. Результат? 100% ШІ.
Інший колумбійський адвокат, Даріо Кабрера Монтеалегре, підкреслив лицемірство у використанні технологій для боротьби з ними.
“Суд використовує ШІ, щоб визначити, чи був ШІ,” — сказав він. “Щось протирічне з моєї практичної точки зору.”
> Суд використовує ШІ, щоб визначити, чи був ШІ…!? Щось протирічне з моєї практичної точки зору…Якщо його відхиляють, то це має бути тому, що ми, люди, це виявили.
>
> — Даріо Кабрера Монтеалегре (@dalcamont_daro) 2 березня 2026
За межами юридичних кол, інші технічно обізнані особи вказали на небезпеку надмірної залежності від інструментів для виявлення ШІ.
“На сьогоднішній день не існує публічно доступного інструменту, який міг би точно визначити відсоток використання ШІ при складанні тексту,” — стверджував Карлос Алехандро Торрес Пінедо. “Що гірше: ніхто не може публічно перевірити вихідний код цих платформ. Як їх можна використовувати для дискредитації права людини на доступ до правосуддя?”
Технічні причини цих невдач добре задокументовані. Детектори ШІ вимірюють статистичні закономірності: довжину речень, передбачуваність словникового запасу та характеристику, яку дослідники називають “вибуховістю” — природну змінність ритму, яку люди вводять у свою писемність.
Проблема в тому, що формальна юридична проза, академічне письмо і тексти, створені людьми, що пишуть іншою мовою, мають багато спільних статистичних ознак.
Дослідження щодо виявлення ШІ
У 2023 році опубліковане у Patterns дослідження показало, що понад 61% есе з тесту TOEFL, написаних носіями інших мов, неправильно позначалися як згенеровані ШІ.
Систематичний огляд Вебер-Вулфа того ж року дійшов висновку, що жоден доступний інструмент не є точним або надійним. Turnitin у червні 2023 року визнав, що його власний детектор дає більше хибних спрацьовувань, коли рівень ШІ у документі падає нижче 20%.
Навіть OpenAI довелося зняти свій інструмент для виявлення ШІ через постійні неточності та неспроможність виконати свою основну функцію.
Університети вже роками борються з цією проблемою. Вандербіль у 2023 році відключив детектор ШІ у Turnitin, оцінивши, що він може генерувати близько 3000 хибних спрацьовувань щороку.
Університет Арізони видалив функції виявлення ШІ з програмного забезпечення для виявлення плагіату після того, як студент отримав штраф у 20% за хибне спрацьовування. У 2024 році UC Davis зафіксував 17 студентів лінгвістики, яких позначили, з них 15 — носії інших мов.
Шаблон послідовний. Інструменти карають тих, хто пише найформальніше, найрецидивніше або найретельніше — саме ті профілі, які підходять юристам, академікам і людям, що пишуть іншою мовою.
Культурний резонанс став майже абсурдним. У колах письменників і журналістів почали уникати використання ем дефісів у своїх роботах, не через стильові рекомендації, а тому, що мовні моделі ШІ часто їх використовують, і детектори (та люди) це помічають.
Письменники почали самостійно редагувати природну пунктуацію через страх бути підозрілими алгоритмами. За межами письмового світу, художники зазнали гніву модераторів і колег за створення мистецьких робіт, що виглядають як роботи ШІ.
> Ми живемо у світі, де справжніх художників карають, бо вони — жертви цих крадіїв, які називаються художниками ШІ? #Savehumanartist #noAIart #NoAI #SavefutureArt pic.twitter.com/yTQAeyc8SR
>
> — художник Benmoran (@benmoran_artist) 27 грудня 2022
Два рішення колумбійського суду — AC739-2026, у якому цивільна палата у лютому оштрафувала адвоката за посилання на 10 неіснуючих прецедентів, згенерованих ШІ, і AP760-2026 — є одними з перших у регіоні, що безпосередньо протистоять зловживанню генеративним ШІ у судових документах.
Юридична система Колумбії ухвалила у грудні 2024 року офіційні рекомендації щодо використання штучного інтелекту суддями та працівниками суду.
Правила дозволяють вільно використовувати ШІ для адміністративних та підтримуючих завдань, таких як складання електронних листів, організація порядку денного, переклад документів або підсумовування текстів, але більш чутливі застосування, наприклад, юридичні дослідження або підготовка процесуальних документів, допускаються лише за ретельного людського контролю.
Указано, що не можна покладатися на ШІ для оцінки доказів, тлумачення закону або прийняття судових рішень, наголошуючи, що судді залишаються повністю відповідальними за всі ухвали і повинні повідомляти, коли у підготовці судових матеріалів використовувалися інструменти ШІ.
Ці рекомендації, зібрані у договорі “PCSJA24-12243”, можуть бути використані для оскарження таких рішень.
Верховний суд ще не зробив додаткових заяв у відповідь на критику щодо вибору інструментів для виявлення ШІ. У постанові також не було ем дефісів.

