Anthropic accuses 3 Chinese AI training companies! Netizens criticize double standards: You also plagiarize copyrighted material

Anthropic accuses three Chinese AI companies DeepSeek, Moonshot AI, and Min of replicating their model capabilities through distillation methods. This move has been met with online mockery, with critics claiming it also violates copyright laws, while sparking heated debate in the U.S. over chip exports and national security.
Anthropic accuses three Chinese AI companies of distillation training to extract advanced model capabilities
AI chatbot Claude developer Anthropic publicly accuses three Chinese AI labs—DeepSeek, Moonshot AI, and Min—of establishing over 24,000 fake accounts to access and exchange data with the Claude model more than 16 million times, using distillation techniques to transfer Claude’s core capabilities to their own models.
“Distillation” is a common AI training technique that evaluates the quality of answers generated by older, larger, or more mature models, enabling smaller, less costly models to learn and transfer the computational results of large models.
Originally, distillation was a legitimate training method used by the AI industry to create lightweight models for clients, but competitors can also use it to directly copy research成果 from other labs.
Anthropic states that these three Chinese AI labs used proxy servers to evade detection and extensively extracted the most distinctive features of Claude, including reasoning, tool use, and coding abilities.
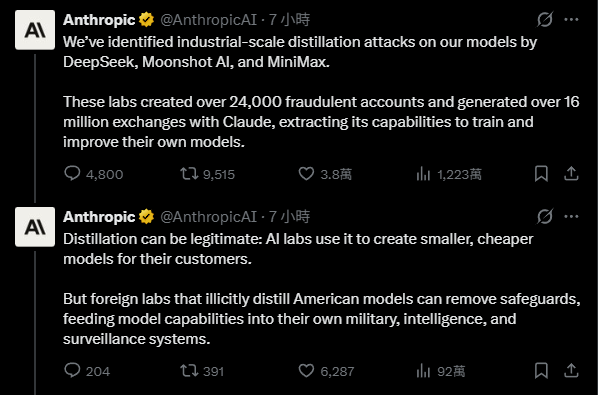
Image source: X Anthropic accuses three Chinese AI companies of distillation training to extract advanced model capabilities
Online critics accuse double standards, as Anthropic faces copyright lawsuits
However, after Anthropic issued its statement, it triggered widespread mockery and skepticism online. Some users believe Anthropic has double standards regarding model training methods.
Tory Green, co-founder of AI infrastructure company IO.Net, criticized that AI companies train on publicly available data but call others’ learning methods “distillation attacks” when they do the same. He pointed out that Anthropic, which often advocates open research, is now complaining about open access.

In 2025, the U.S. forum Reddit will formally sue Anthropic, accusing the company of unauthorized data scraping of over 100,000 forum posts and comments for fine-tuning Claude. Reddit alleges that Anthropic violated user agreements and continued accessing Reddit servers more than 100,000 times even after publicly claiming to have stopped scraping.
Additionally, Anthropic faces a class-action lawsuit for using 70 million books without permission to train Claude. In September last year, it agreed to pay up to $1.5 billion in settlement, the largest copyright settlement in U.S. history, though the payout is still subject to court approval.
- **Related report: The biggest AI compensation case in history! Claude trained on pirated books, $48 billion settlement, Taiwanese authors also compensated
OpenAI also issues similar warnings against DeepSeek
Besides Anthropic, AI giant OpenAI is also facing similar issues.
According to an internal memo seen by Reuters last week, OpenAI has warned U.S. lawmakers that DeepSeek is targeting ChatGPT developer and leading U.S. AI companies, attempting to copy models and use them for their own algorithms.
OpenAI observed accounts associated with DeepSeek employees developing various methods to bypass OpenAI’s access restrictions. They use obfuscated third-party routers and other hidden sources to programmatically access U.S. AI models and obtain outputs for distillation training.
Chinese AI distillation technology controversy amid easing U.S. chip export controls
While U.S. AI giants accuse China’s distillation training techniques, the U.S. is also in a sensitive period of debate over China’s chip export restrictions. The Trump administration officially allowed U.S. companies like Nvidia in January to export advanced AI chips such as the H200 to China.
Critics argue that at this critical moment of global AI dominance competition, loosening export controls will significantly boost China’s AI computing capabilities.
Dmitri Alperovitch, chairman of Silverado Policy Accelerator, states that China’s rapid progress in AI models is partly due to stealing U.S. frontier models through distillation techniques. This evidence provides a more compelling reason for the U.S. to refuse to sell any AI chips to these companies, or risk further strengthening their advantage.
Anthropic warns that AI systems built by U.S. companies have security measures to prevent state or non-state actors from developing biological weapons or conducting malicious cyber activities with AI. However, models built via distillation often lack such protections.
Anthropic fears that if foreign AI labs can integrate these unrestricted capabilities into military and intelligence systems, authoritarian governments could use AI for offensive cyber operations, disinformation campaigns, and mass surveillance, exponentially increasing security risks.
Further reading:
Chinese hackers launch large-scale AI cyberattack! Anthropic: AI hackers now faster and larger than human hackers