Understanding Huang Renxun's Physical AI: Why Are Crypto Opportunities Hidden in the "Corners and Crannies"?

What exactly did Jensen Huang say at the Davos Forum?
On the surface, he’s promoting robots, but in reality, he’s conducting a bold “self-revolution.” He ended the old era of “stacking graphics cards” with a single speech, yet unexpectedly, he pre-set a golden ticket for the Crypto track?
Yesterday, at the Davos Forum, Huang pointed out that the AI application layer is exploding, and the demand for computing power will shift from “training” to “inference” and “Physical AI.”
This is very interesting.
NVIDIA, as the biggest winner in the AI 1.0 era “compute race,” now proactively calls for a shift toward “inference” and “Physical AI,” which actually sends a very straightforward signal: the era of relying on stacking cards to train large models for miracles is over. Future AI competition will revolve around the “application-driven” approach, focusing on real-world application scenarios.
In other words, Physical AI is the second half of Generative AI.
Because LLMs have already read all the data accumulated over decades on the internet, but they still don’t understand how to open a bottle cap like a human. Physical AI aims to solve the “unity of knowledge and action” problem beyond AI intelligence.
Because physical AI cannot rely on the “long feedback loop” of remote cloud servers. The logic is simple: making ChatGPT generate text one second slower might just feel laggy, but if a bipedal robot experiences a one-second delay due to network latency, it could fall down the stairs.
However, while Physical AI appears to be an extension of generative AI, it faces three entirely different new challenges:
1) Spatial Intelligence: Enabling AI to understand a three-dimensional world.
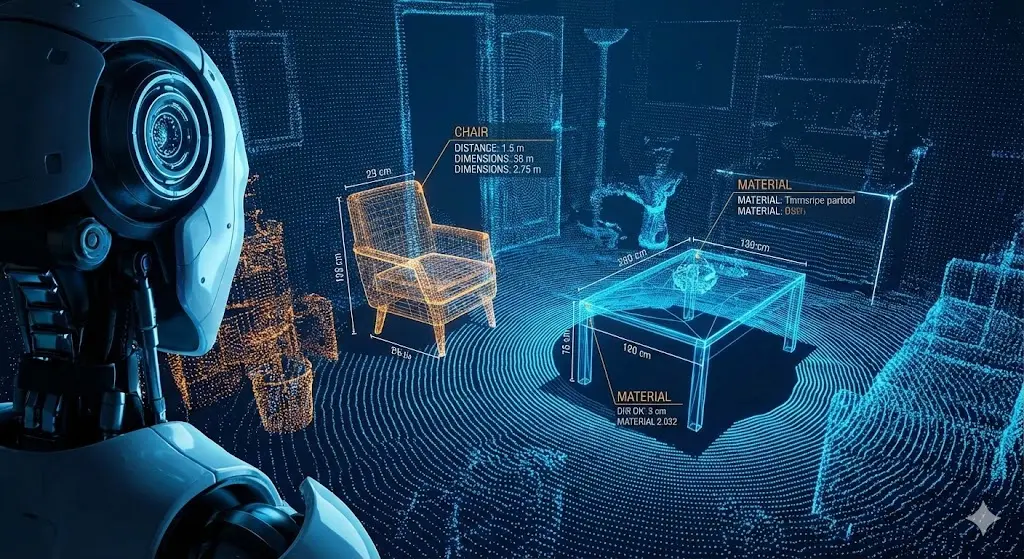
Professor Fei-Fei Li once proposed that spatial intelligence is the next Polaris of AI evolution. Robots need to “see and understand” their environment before moving. This is not just recognizing “this is a chair,” but understanding “the chair’s position and structure in 3D space, and how much force I need to move it.”
This requires massive, real-time 3D environment data covering every corner indoors and outdoors;
2) Virtual Training Grounds: Allowing AI to learn through trial and error in simulated worlds.

Huang mentioned Omniverse, which is essentially a “virtual training ground.” Robots need to train “10,000 falls” in virtual environments before entering the real physical world to learn to walk. This process is called Sim-to-Real, from simulation to reality. If robots were to learn through trial and error directly in the real world, hardware wear and tear costs would be astronomical.
This process demands exponential throughput of physics engine simulation and rendering computing power;
3) Electronic Skin: “Tactile data” as a gold mine waiting to be mined.

To have “a sense of touch,” Physical AI needs electronic skin to perceive temperature, pressure, and texture. These “tactile data” are entirely new assets that have never been scaled before. This may require large-scale sensor collection. At CES, Ensuring showcased a “mass-produced skin” integrated with 1,956 sensors on a single hand, enabling robots to perform the amazing task of cracking eggs.
These “tactile data” are entirely new assets that have never been scaled before.
After reading all this, you must feel that the emergence of the Physical AI narrative offers great opportunities for hardware devices like wearables and humanoid robots—remember, these were often criticized a few years ago as “big toys.”
Actually, I want to say that in the new landscape of Physical AI, the Crypto track also has excellent ecological complement opportunities. Here are a few examples:
-
Major AI giants can deploy street view cars to scan every main street, but they can’t capture every nook and cranny inside neighborhoods, basements, and underground spaces. Using Token incentives from DePIN networks, mobilizing global users with portable devices to fill in these data gaps could be a way to complete the coverage;
-
As mentioned earlier, robots can’t rely on cloud computing power, but in the short term, large-scale use of edge computing and distributed rendering capabilities—especially for generating data from simulation to reality—can be achieved by aggregating idle consumer-grade hardware through distributed compute networks for dispatch and scheduling;
-
“Tactile data,” besides large-scale sensor applications, are inherently highly private. How to coordinate the public to share these privacy-sensitive data with AI giants? A feasible approach is to enable contributors to obtain data rights confirmation and dividends.
In summary:
Physical AI is the second half of the Web2 AI track that Huang announced. What about Web3 AI + Crypto tracks such as DePIN, DeAI, DeData, and others? What do you think?