การวิเคราะห์เชิงลึกของ Nesa: ทำไม AI ที่คุณใช้งานในชีวิตประจำวันจึงต้องการการปกป้องความเป็นส่วนตัว?
รายงานฉบับนี้เขียนโดย Tiger Research ซึ่งคนส่วนใหญ่มักใช้งาน AI ทุกวัน แต่ไม่เคยคิดเลยว่าข้อมูลนั้นไหลไปที่ใด คำถามที่ Nesa ยกขึ้นมาคือ: เมื่อคุณเริ่มตระหนักถึงเรื่องนี้ จะเกิดอะไรขึ้น?
ประเด็นสำคัญ
- AI ได้กลายเป็นส่วนหนึ่งของชีวิตประจำวัน แต่ผู้ใช้มักมองข้ามว่าข้อมูลถูกส่งผ่านเซิร์ฟเวอร์กลางอย่างไร
- แม้แต่ผู้ช่วยผู้อำนวยการของ CISA สหรัฐ ก็ยังเผลอปล่อยเอกสารลับให้ ChatGPT โดยไม่รู้ตัว
- Nesa ได้สร้างกระบวนการนี้ใหม่โดยใช้การแปลงข้อมูลก่อนส่ง (EE) และการแบ่งข้อมูลข้ามโหนด (HSS-EE) เพื่อให้ไม่มีฝ่ายใดสามารถดูข้อมูลดั้งเดิมได้
- การรับรองทางวิชาการ (COLM 2025) และการใช้งานจริงในองค์กร (P&G) ทำให้ Nesa ได้เปรียบในตลาด
- คำถามสำคัญคือ ตลาดกว้างจะเลือกใช้ AI ที่เน้นความเป็นส่วนตัวแบบกระจายศูนย์มากขึ้น แทน API แบบศูนย์กลางที่คุ้นเคยหรือไม่
1. ข้อมูลของคุณปลอดภัยแค่ไหน?

ที่มา: CISA
มกราคม 2026 ผู้ช่วยผู้อำนวยการของ CISA ซึ่งเป็นหน่วยงานด้านความปลอดภัยทางไซเบอร์ของสหรัฐ ได้อัปโหลดเอกสารลับของรัฐบาลไปยัง ChatGPT เพื่อสรุปและจัดระเบียบข้อมูลสัญญา
การรั่วไหลนี้ไม่ได้ถูกตรวจจับโดย ChatGPT และ OpenAI ก็ไม่ได้รายงานให้รัฐบาลทราบ แต่ถูกตรวจพบโดยระบบความปลอดภัยภายในของหน่วยงานเอง และนำไปสู่การสอบสวนเนื่องจากฝ่าฝืนข้อตกลงด้านความปลอดภัย
แม้แต่เจ้าหน้าที่ด้านความปลอดภัยไซเบอร์สูงสุดของสหรัฐ ก็ยังใช้งาน AI ในชีวิตประจำวัน โดยเผลออัปโหลดข้อมูลลับโดยไม่รู้ตัว
เราทราบดีว่า บริการ AI ส่วนใหญ่จะเก็บข้อมูลผู้ใช้ในเซิร์ฟเวอร์กลางในรูปแบบเข้ารหัส แต่การเข้ารหัสดังกล่าวเป็นแบบถอดรหัสได้ตามดีไซน์ ในกรณีที่ได้รับอนุญาตตามกฎหมายหรือในสถานการณ์ฉุกเฉิน ข้อมูลสามารถถูกถอดรหัสและเปิดเผยได้ โดยที่ผู้ใช้ไม่รู้เรื่องราวเบื้องหลัง
2. AI ความเป็นส่วนตัวสำหรับใช้งานในชีวิตประจำวัน: Nesa
AI ได้กลายเป็นส่วนหนึ่งของชีวิตประจำวัน—สรุปบทความ เขียนโค้ด ร่างอีเมล สิ่งที่น่ากังวลคือ อย่างที่เห็นในตัวอย่างก่อนหน้า แม้แต่เอกสารลับและข้อมูลส่วนตัว ก็ถูกส่งให้ AI โดยที่ผู้ใช้แทบไม่รู้ตัวว่ามีความเสี่ยงอะไรเกิดขึ้น
ประเด็นสำคัญคือ ข้อมูลเหล่านี้ต้องผ่านเซิร์ฟเวอร์กลางของผู้ให้บริการ ถึงแม้จะเข้ารหัสก็ตาม กุญแจถอดรหัสก็อยู่ในมือของผู้ให้บริการ แล้วผู้ใช้จะไว้วางใจการจัดการแบบนี้ได้อย่างไร?
ข้อมูลที่ผู้ใช้ป้อนเข้าไปอาจถูกเปิดเผยต่อบุคคลที่สามในหลายทาง เช่น การฝึกโมเดล การตรวจสอบความปลอดภัย คำร้องทางกฎหมาย ในเวอร์ชันองค์กร ผู้ดูแลระบบสามารถเข้าถึงประวัติสนทนาได้ เช่นเดียวกับเวอร์ชันส่วนตัวที่ข้อมูลอาจถูกส่งต่อภายใต้การอนุญาตตามกฎหมาย

เมื่อ AI ฝังแน่นในชีวิตประจำวันแล้ว ก็ถึงเวลาที่จะต้องพิจารณาเรื่องความเป็นส่วนตัวอย่างจริงจัง
Nesa เป็นโครงการที่เกิดขึ้นเพื่อเปลี่ยนแปลงโครงสร้างนี้อย่างสิ้นเชิง มันสร้างโครงสร้างพื้นฐานแบบกระจายศูนย์ โดยไม่ต้องพึ่งพาเซิร์ฟเวอร์กลางในการทำ inference AI ข้อมูลที่ผู้ใช้ป้อนเข้าไปจะถูกประมวลผลในสถานะเข้ารหัส ซึ่งไม่มีโหนดใดสามารถดูข้อมูลดั้งเดิมได้
3. Nesa จะแก้ปัญหาอย่างไร
สมมุติว่ามีโรงพยาบาลแห่งหนึ่งใช้ Nesa หมออยากให้ AI วิเคราะห์ภาพ MRI ของผู้ป่วยเพื่อค้นหาเนื้องอก ในบริการ AI แบบเดิม ภาพจะถูกส่งตรงไปยังเซิร์ฟเวอร์ของ OpenAI หรือ Google
แต่เมื่อใช้ Nesa ก่อนที่ภาพจะออกจากคอมพิวเตอร์ของหมอ ก็ได้ทำการแปลงทางคณิตศาสตร์ไปแล้ว
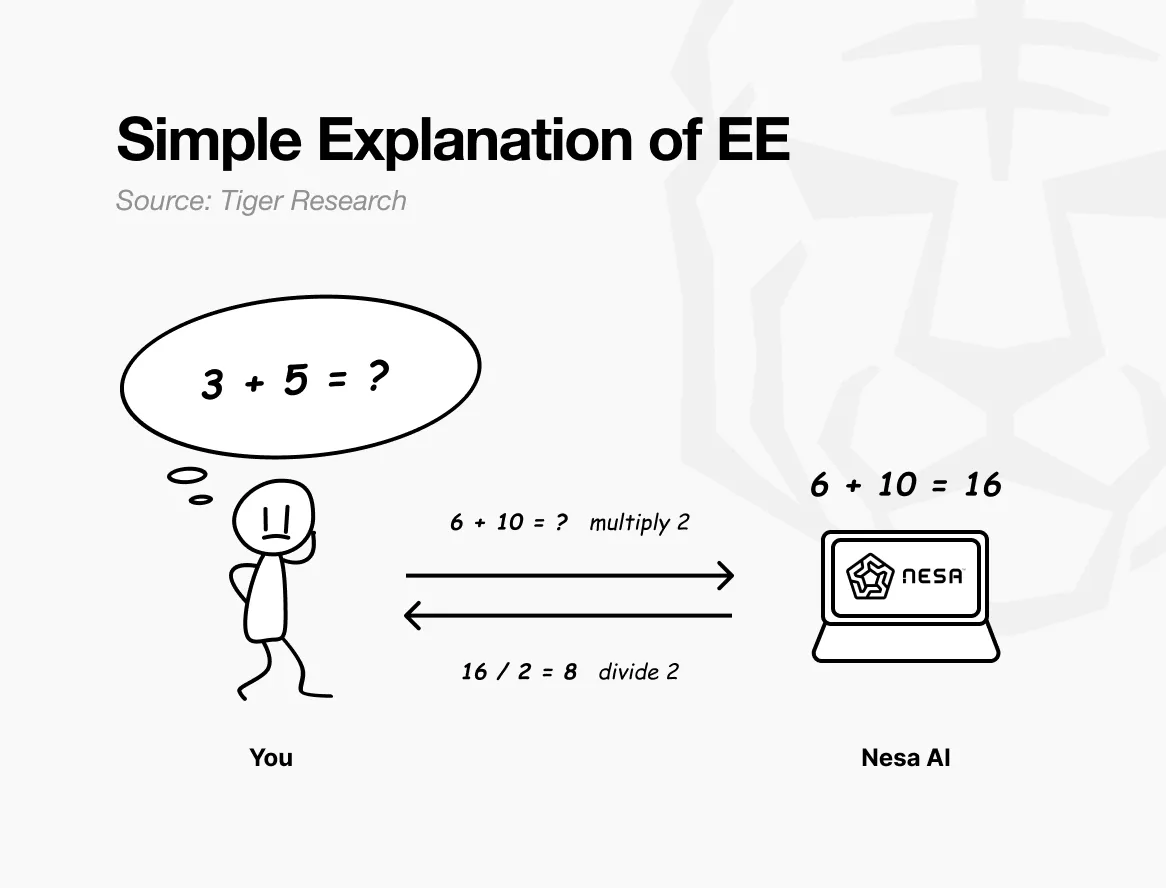
ยกตัวอย่างง่ายๆ เช่น ถ้าปัญหาดั้งเดิมคือ “3 + 5 = ?” ถ้าส่งตรงไป ฝั่งรับจะรู้ว่าคุณกำลังคำนวณอะไร แต่ถ้าก่อนส่ง คุณคูณแต่ละตัวเลขด้วย 2 ผลลัพธ์ที่ฝั่งรับจะเห็นคือ “6 + 10 = ?” แล้วส่งกลับมาให้คุณ คุณก็แค่หารด้วย 2 ก็จะได้คำตอบ 8 ซึ่งตรงกับการคำนวณปัญหาดั้งเดิมอย่างสมบูรณ์ การคำนวณเสร็จสมบูรณ์ แต่ฝั่งรับก็ไม่รู้ว่าตัวเลขเดิมคือ 3 กับ 5
นี่คือสิ่งที่ EE (Equivariant Encryption) ของ Nesa ทำได้ ข้อมูลจะถูกแปลงทางคณิตศาสตร์ก่อนส่ง ข้อมูลที่ AI ทำการคำนวณก็เป็นข้อมูลที่แปลงแล้ว
ผู้ใช้สามารถทำการย้อนกลับการแปลงได้ ผลลัพธ์ที่ได้จะเท่ากับการคำนวณด้วยข้อมูลดั้งเดิมในเชิงคณิตศาสตร์ คุณสมบัตินี้เรียกว่า “ความเป็นไปตามสมมาตร” (equivariance): ไม่ว่าจะเปลี่ยนแปลงข้อมูลก่อนคำนวณหรือคำนวณก่อนแปลง ผลลัพธ์สุดท้ายก็เหมือนกัน
ในทางปฏิบัติ การแปลงนี้ซับซ้อนกว่าการคูณง่ายๆ มาก เพราะเป็นการปรับแต่งเฉพาะตามโครงสร้างภายในของโมเดล AI โดยการแปลงและการประมวลผลของโมเดลจะสอดคล้องกันอย่างลงตัว ความแม่นยำจึงไม่ลดลงแม้แต่น้อย
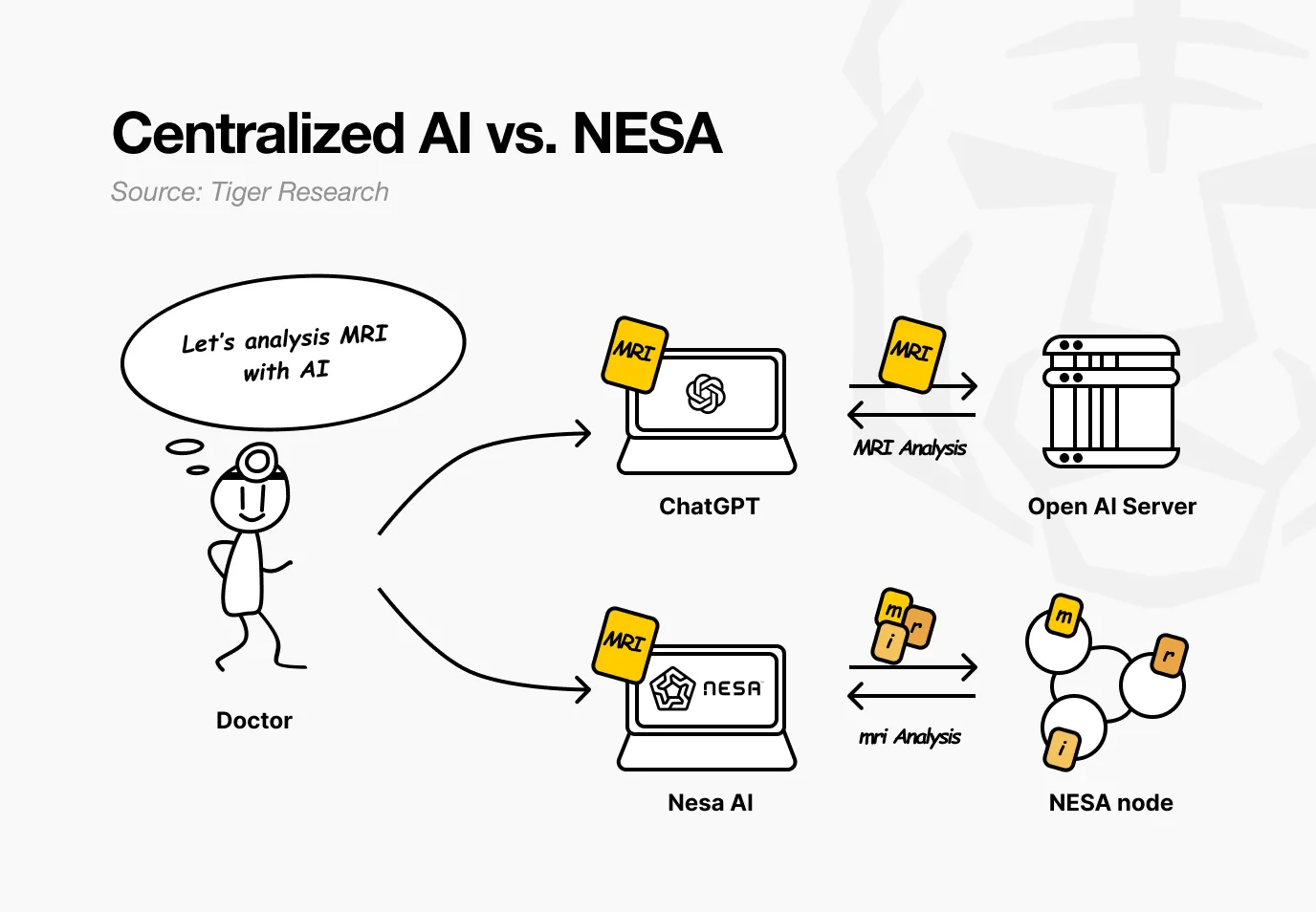
ย้อนกลับไปในตัวอย่างโรงพยาบาล สำหรับหมอแล้ว กระบวนการทั้งหมดไม่มีการเปลี่ยนแปลง—อัปโหลดภาพ รับผลลัพธ์ ทุกอย่างเหมือนเดิม สิ่งที่เปลี่ยนไปคือ โหนดกลางใดๆ ก็ไม่สามารถเห็น MRI ดั้งเดิมของผู้ป่วยได้
Nesa ยังทำได้ดีขึ้นไปอีก ด้วย EE เพียงอย่างเดียวก็สามารถป้องกันไม่ให้โหนดใดๆ ดูข้อมูลดั้งเดิมได้ แต่ข้อมูลที่แปลงแล้วก็ยังคงอยู่ในเซิร์ฟเวอร์เดียวกัน
HSS-EE (Homomorphic Secret Sharing บนข้อมูลเข้ารหัส) เป็นเทคนิคที่แบ่งข้อมูลที่แปลงแล้วออกเป็นส่วนๆ ต่อไป
ต่อเนื่องจากตัวอย่างเดิม EE ก็เหมือนกับการส่งข้อสอบที่ใช้กฎคูณก่อนส่ง ส่วน HSS-EE ก็เหมือนกับการฉีกข้อสอบเป็นสองชิ้น ส่งชิ้นแรกให้โหนด A อีกชิ้นให้โหนด B
แต่ละโหนดจะตอบคำถามเฉพาะของตัวเองเท่านั้น ไม่เห็นคำถามเต็มรูปแบบ เมื่อรวมคำตอบทั้งสองส่วนเข้าด้วยกัน ก็จะได้คำตอบสมบูรณ์—และเฉพาะผู้ส่งข้อมูลเท่านั้นที่สามารถทำการรวมได้
สรุปง่ายๆ: EE แปลงข้อมูล ทำให้เนื้อหาเดิมไม่สามารถมองเห็นได้; HSS-EE แบ่งข้อมูลที่แปลงแล้วออกเป็นชิ้นๆ ทำให้ข้อมูลไม่เคยปรากฏครบถ้วนในที่ใดที่หนึ่ง การปกป้องความเป็นส่วนตัวจึงแข็งแกร่งขึ้นเป็นสองเท่า
4. การปกป้องความเป็นส่วนตัวจะทำให้ประสิทธิภาพช้าลงไหม?
ความปลอดภัยที่แข็งแกร่งขึ้นมักมาพร้อมกับความช้าลงเสมอ นี่เป็นกฎเกณฑ์ในวงการเข้ารหัสลับที่ยาวนานที่สุด การเข้ารหัสแบบ Homomorphic Encryption (FHE) ที่สมบูรณ์นั้นช้ากว่าการคำนวณปกติถึง 10,000 ถึง 1,000,000 เท่า ซึ่งไม่สามารถนำไปใช้ในบริการ AI แบบเรียลไทม์ได้
Nesa เลือกใช้ EE ซึ่งแตกต่างออกไป ในเชิงคณิตศาสตร์: การคูณด้วย 2 ก่อนส่ง และการหารด้วย 2 หลังรับ ผลลัพธ์จึงแทบไม่ต่างจากต้นฉบับ
ต่างจาก FHE ที่เปลี่ยนปัญหาเป็นระบบคณิตศาสตร์ใหม่ทั้งหมด EE ทำเพียงการเพิ่มชั้นการแปลงแบบเบาๆ บนพื้นฐานการคำนวณเดิม
ข้อมูลเปรียบเทียบด้านประสิทธิภาพ:
- EE: เพิ่มดีเลย์น้อยกว่า 9% บน LLaMA-8B ความแม่นยำเทียบเท่าโมเดลเดิม สูงกว่า 99.99%
- HSS-EE: บน LLaMA-2 7B แต่ละครั้ง inference ใช้เวลา 700 ถึง 850 มิลลิวินาที
นอกจากนี้ MetaInf ตัวจัดการการเรียนรู้แบบเมตา ยังช่วยปรับปรุงประสิทธิภาพทั่วทั้งเครือข่าย โดยประเมินขนาดโมเดล สเปค GPU และลักษณะข้อมูล แล้วเลือกวิธี inference ที่เร็วที่สุด
MetaInf ทำให้ได้อัตราความถูกต้องในการเลือกถึง 89.8% และเร็วกว่าเครื่องมือเลือกแบบดั้งเดิม 1.55 เท่า ผลงานนี้ได้รับการเผยแพร่ใน COLM 2025 ซึ่งเป็นงานประชุมวิชาการระดับหลัก
ข้อมูลข้างต้นมาจากการทดสอบในสภาพแวดล้อมควบคุม แต่สิ่งที่สำคัญกว่าคือ โครงสร้าง inference ของ Nesa ได้ถูกนำไปใช้งานจริงในองค์กรแล้ว ยืนยันประสิทธิภาพในระดับผลิต
5. ใครใช้งานบ้าง? ใช้อย่างไร?

มีสามวิธีในการเข้าถึง Nesa
วิธีแรกคือ Playground ผู้ใช้สามารถเข้าไปทดลองโมเดลต่างๆ บนเว็บไซต์ โดยไม่ต้องมีพื้นฐานด้านพัฒนา คุณสามารถลองป้อนข้อมูล ดูผลลัพธ์ของแต่ละโมเดลแบบเต็มๆ ได้
นี่เป็นวิธีที่เร็วที่สุดในการเข้าใจการทำงานของ inference แบบกระจายศูนย์จริงๆ
วิธีที่สองคือ Pro แบบสมัครสมาชิก ค่าบริการ 8 ดอลลาร์ต่อเดือน รวมการเข้าถึงไม่จำกัด การใช้งาน inference ความเร็วสูง 1,000 ครั้งต่อเดือน การควบคุมราคาของโมเดลที่ปรับแต่งได้ และหน้ารายละเอียดโมเดล
แพ็กเกจนี้เหมาะสำหรับนักพัฒนาหรือนักสร้างสรรค์ที่ต้องการใช้งานและสร้างรายได้จากโมเดลของตนเอง
วิธีที่สามคือ Enterprise สำหรับองค์กร ซึ่งเป็นแบบกำหนดเอง ไม่ใช่ราคาที่เปิดเผย รวมถึง SSO/SAML การเลือกพื้นที่เก็บข้อมูล การบันทึกกิจกรรม การควบคุมการเข้าถึงระดับละเอียด และการชำระเงินตามสัญญาปีต่อปี
ราคาขั้นต่ำอยู่ที่ 20 ดอลลาร์ต่อผู้ใช้ต่อเดือน แต่รายละเอียดขึ้นอยู่กับขนาดและความต้องการขององค์กร โครงสร้างนี้ออกแบบมาเพื่อให้สามารถผนวก Nesa เข้ากับกระบวนการ AI ภายในองค์กร ผ่านข้อตกลงเฉพาะทาง
สรุปคือ Playground สำหรับทดลองใช้งาน, Pro สำหรับนักพัฒนาหรือนักสร้างรายได้, และ Enterprise สำหรับองค์กร
6. ทำไมต้องใช้โทเค็น?
ในเครือข่ายแบบกระจายศูนย์ ไม่มีผู้ดูแลกลาง การรันเซิร์ฟเวอร์และการตรวจสอบผลลัพธ์จะกระจายอยู่ทั่วโลก ซึ่งนำไปสู่คำถามว่า: ทำไมใครสักคนถึงยอมให้ GPU ของตัวเองทำงานต่อเนื่องเพื่อประมวล inference ให้ผู้อื่น?
คำตอบคือแรงจูงใจทางเศรษฐกิจ ในเครือข่าย Nesa สิ่งนี้คือ $NES โทเค็น
ที่มา: Nesa
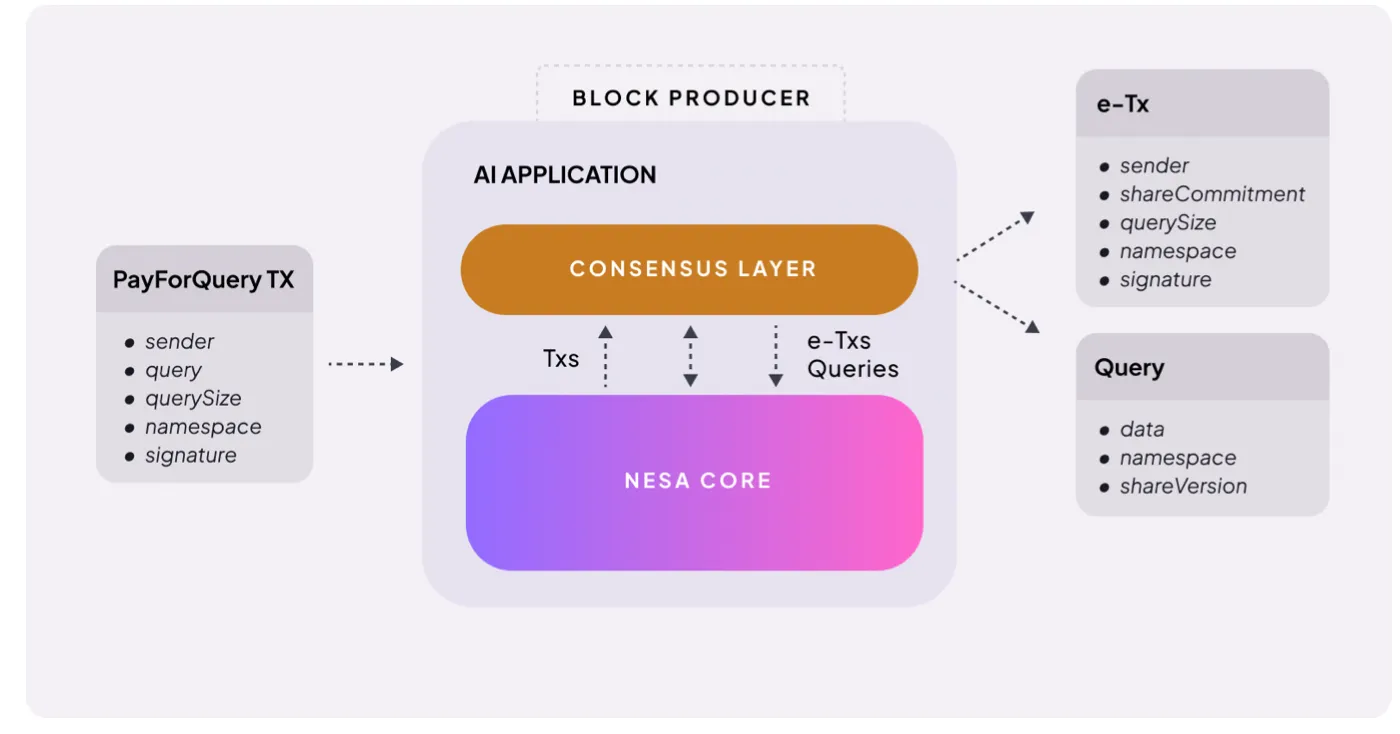
กลไกก็ตรงไปตรงมา เมื่อผู้ใช้ร้องขอ inference AI จะต้องจ่ายค่าธรรมเนียม ซึ่ง Nesa เรียกว่า PayForQuery ซึ่งประกอบด้วยค่าธรรมเนียมคงที่ต่อการทำธุรกรรมบวกกับค่าที่ขึ้นอยู่กับปริมาณข้อมูล
ค่าธรรมเนียมสูงขึ้น ก็จะได้รับความสำคัญในการประมวลผลมากขึ้น ซึ่งคล้ายกับ gas fee ในบล็อกเชน
รายรับเหล่านี้จะเป็นของ “นักขุด” (miners) ในเครือข่าย เพื่อเข้าร่วม ผู้ขุดต้องวางหลักประกันเป็น $NES ในจำนวนที่กำหนด ก่อนรับงาน เมื่อส่งผลผิดพลาดหรือไม่ตอบสนอง ก็จะถูกหักเงินจากหลักประกัน หากทำงานถูกต้องและรวดเร็ว ก็จะได้รับรางวัลสูงขึ้น
$NES ยังเป็นเครื่องมือในการบริหารจัดการด้วย โทเค็นนี้สามารถใช้ในการเสนอแนะและลงคะแนนเสียงในเรื่องต่างๆ เช่น โครงสร้างค่าธรรมเนียม อัตราการจูงใจ ฯลฯ
โดยสรุป $NES ทำหน้าที่สามอย่าง: เป็นค่าธรรมเนียมสำหรับ inference, เป็นหลักประกันและรางวัลของนักขุด, และเป็นเครื่องมือในการบริหารเครือข่าย ไม่มีโทเค็น ก็ไม่สามารถรันโหนดได้; ไม่มีโหนด ก็ไม่สามารถพูดถึง AI ความเป็นส่วนตัวได้
สิ่งที่ควรระวังคือ ระบบเศรษฐกิจของโทเค็นขึ้นอยู่กับสมดุลของความต้องการและการให้บริการ หากความต้องการ inference สูงขึ้น นักขุดก็จะได้รับรางวัลมากขึ้น หากรางวัลไม่สมดุล ก็อาจส่งผลต่อเสถียรภาพของเครือข่าย
เป็นวัฏจักรที่ขับเคลื่อนด้วยความต้องการและการตอบสนอง—แต่การจุดประกายวัฏจักรนี้เป็นเรื่องที่ยากที่สุดในช่วงเริ่มต้น
ลูกค้าบริษัทอย่าง P&G ก็ใช้งานเครือข่ายนี้ในสภาพแวดล้อมการผลิตแล้ว ซึ่งเป็นสัญญาณเชิงบวก แต่เมื่อขนาดเครือข่ายขยายตัว ความสมดุลระหว่างมูลค่าของโทเค็นและรางวัลนักขุดจะคงอยู่หรือไม่ ก็ยังต้องติดตาม
7. ความจำเป็นของ AI ความเป็นส่วนตัว
Nesa พยายามแก้ปัญหาอย่างชัดเจน: เปลี่ยนโครงสร้างที่ทำให้ข้อมูลของผู้ใช้ถูกเปิดเผยต่อบุคคลที่สามในขณะใช้งาน AI
เทคโนโลยีพื้นฐานแข็งแรงและเชื่อถือได้ โดยใช้เทคโนโลยีเข้ารหัสหลัก—EE และ HSS-EE ซึ่งมาจากงานวิจัยทางวิชาการ และตัวจัดการ inference แบบเมตาMetaInf ก็ได้รับการเผยแพร่ใน COLM 2025
นี่ไม่ใช่แค่การอ้างอิงงานวิจัยธรรมดา แต่ทีมวิจัยได้ออกแบบโปรโตคอลเองและนำไปใช้งานจริงในเครือข่าย
ในโครงการ AI แบบกระจายศูนย์ มีไม่กี่โครงการที่สามารถพิสูจน์ความถูกต้องของเทคโนโลยีเข้ารหัสในระดับวิชาการ และนำไปใช้งานจริงได้แล้ว เช่นเดียวกับที่บริษัทใหญ่อย่าง P&G ก็ใช้งาน inference บนโครงสร้างนี้ ซึ่งเป็นสัญญาณที่สำคัญสำหรับโครงการในระยะเริ่มต้น
อย่างไรก็ตาม ก็ยังมีข้อจำกัดชัดเจน:
- ขอบเขตตลาด: ลูกค้าองค์กรเป็นเป้าหมายหลัก; ผู้ใช้ทั่วไปอาจยังไม่พร้อมจ่ายเพื่อความเป็นส่วนตัว
- ประสบการณ์ใช้งาน: Playground ดูเหมือนเครื่องมือ Web3/การลงทุน มากกว่าจะเป็น AI สำหรับใช้งานในชีวิตประจำวัน
- การทดสอบขนาดใหญ่: การทดสอบในสภาพแวดล้อมควบคุมไม่เท่ากับการรองรับหลายพันโหนดในสภาพแวดล้อมจริง
- จังหวะตลาด: ความต้องการ AI ความเป็นส่วนตัวมีอยู่จริง แต่ความต้องการ AI ความเป็นส่วนตัวแบบกระจายศูนย์ยังไม่ได้รับการพิสูจน์; องค์กรยังคุ้นเคยกับ API แบบศูนย์กลาง
หลายบริษัทยังคงนิยมใช้ API แบบศูนย์กลางอยู่ และการสร้างโครงสร้างพื้นฐานบนบล็อกเชนก็ยังมีอุปสรรคสูง
เรายังอยู่ในยุคที่แม้แต่เจ้าหน้าที่ความปลอดภัยไซเบอร์ของสหรัฐ ก็ยังอัปโหลดเอกสารลับให้ AI ได้ ความต้องการ AI ความเป็นส่วนตัวจึงมีอยู่แล้วและจะเติบโตต่อไป
Nesa มีเทคโนโลยีที่ได้รับการรับรองทางวิชาการและโครงสร้างพื้นฐานที่ใช้งานจริง เพื่อรองรับความต้องการนี้ แม้จะมีข้อจำกัด แต่ก็ได้เปรียบในจุดเริ่มต้นแล้ว
เมื่อตลาด AI ความเป็นส่วนตัวเปิดกว้างขึ้น Nesa จะเป็นชื่อที่ถูกพูดถึงเป็นอันดับต้นๆ แน่นอน