
AI-система памяти MemPalace, разработанная Мила Джовович Вичкич, заявила о тесте на максимальный балл и быстро стала популярной, но сообщество обвинило её в читерстве на тестах и введении в заблуждение данными. Практическая проверка показала, что эффект преувеличен и присутствует множество ошибок; команда признала недостатки и уже работает над исправлениями.
Мила Джовович Вичкич создала AI-памятьный дворец, вызвав интерес извне
Вчера (4/7) в AI-сообществе случилось крупное событие: голливудская актриса Мила Джовович (известная по «Обители зла» и «Пятому элементу»), совместно с разработчиком Ben Sigman с помощью Claude Code помогла создать «MemPalace» — open-source систему AI-памяти.
Внезапно широко распространилась версия «голливудская суперзвезда из другой сферы сделала проект на идеальный балл», и к настоящему моменту MemPalace на GitHub также набрала более 20k звезд, но очень быстро разработческое сообщество начало сомневаться: правда ли там есть что-то стоящее или это всего лишь хайп?
Сначала о мотивации появления MemPalace: в официальной документации говорится, что система призвана решить проблему, когда содержимое диалогов пользователей с AI, процессы принятия решений и обсуждения архитектуры обычно исчезают после завершения рабочей сессии, что приводит к «падению до нуля» месячных усилий.
Чтобы решить эту проблему, MemPalace использует пространственную архитектуру для хранения памяти: информация четко классифицируется в крылья, представляющие персоналии или проекты, а также в структуре разных уровней — коридоры, комнаты и ящики — при этом исходный текст диалога сохраняется для последующего семантического поиска.
Разработчики утверждают, что MemPalace получила 100% идеальный результат в эталоне долгосрочной памяти LongMemEval, и при этом достигла точности 96,6% без вызова любых внешних API, а также может полностью работать локально, не требуя подписки на облачные сервисы, и оснащена заявленной AAAK-диалектной системой, которая якобы позволяет добиться 30-кратного без потерь сжатия.
Источник изображения: GitHub Голливудская звезда Мила Джовович Вичкич создала AI-памятный дворец, вызвав интерес извне
Коллеги и сообщество одновременно задают вопросы, тестирование и продвижение с изъянами
Но результаты, якобы полученные MemPalace на LongMemEval на максимум, очень быстро вызвали сомнения у коллег.
PenfieldLabs — компания, также занимающаяся созданием AI-систем памяти, — указала, что MemPalace, якобы получившая идеальный балл на датасете LoCoMo, математически не могла этого достичь, потому что сами стандартные ответы в этом датасете содержат 99 ошибок.
В ходе анализа PenfieldLabs выяснили, что 100% результат MemPalace получен за счет установки числа обращений (retrieval) равным 50, но наивысший уровень этапов диалога в тестовом датасете составляет всего 32 раза, а это означает, что система напрямую обходит стадию retrieval и отдает все данные на чтение AI-модели.
По поводу 100% результата в LongMemEval обнаружили, что разработчики имели дело с тремя конкретными ошибочными вопросами, по которым была написана специальная исправляющая программа; при этом есть подозрение, что выполнено читерство на тестовом наборе.

Источник изображения: Reddit коллеги PenfieldLabs указали, что MemPalace, якобы получившая идеальный балл на датасете LoCoMo, математически не могла этого достичь
Проверка пользователями на GitHub: в бенчмарке есть элемент введения в заблуждение
Пользователь GitHub hugooconnor после проверки оставил комментарий: MemPalace заявляет точность retrieval до 96,6%, но на деле она вообще не использует архитектуру памятного дворца, которую продвигает. hugooconnor утверждает, что их тест просто вызывает стандартные функции базового хранилища данных ChromaDB и вообще не затрагивает логики классификации, подчеркиваемой в проекте — крылья, комнаты или ящики.
После теста hugooconnor обнаружил, что когда система действительно включает эти «дворцовые» фирменные логики классификации, результаты retrieval, напротив, ухудшаются. Например, в режиме комнаты точность падает до 89,4%, а при включении технологии сжатия AAAK точность еще ниже — до 84,2%; оба значения оказываются ниже, чем у работы с настройками базовой базы данных.
hugooconnor также раскритиковал метод тестирования: среда MemPalace намеренно сужает retrieval-диапазон для каждого вопроса примерно до 50 этапов диалога, и искать ответы в слишком маленькой выборке оказывается слишком просто.
Если расширить диапазон до более чем 19 000 этапов диалога в реальном сценарии, точность традиционного поиска по ключевым словам падает до 30%, что показывает: текущий способ тестирования MemPalace скрывает реальные проблемы поиска.
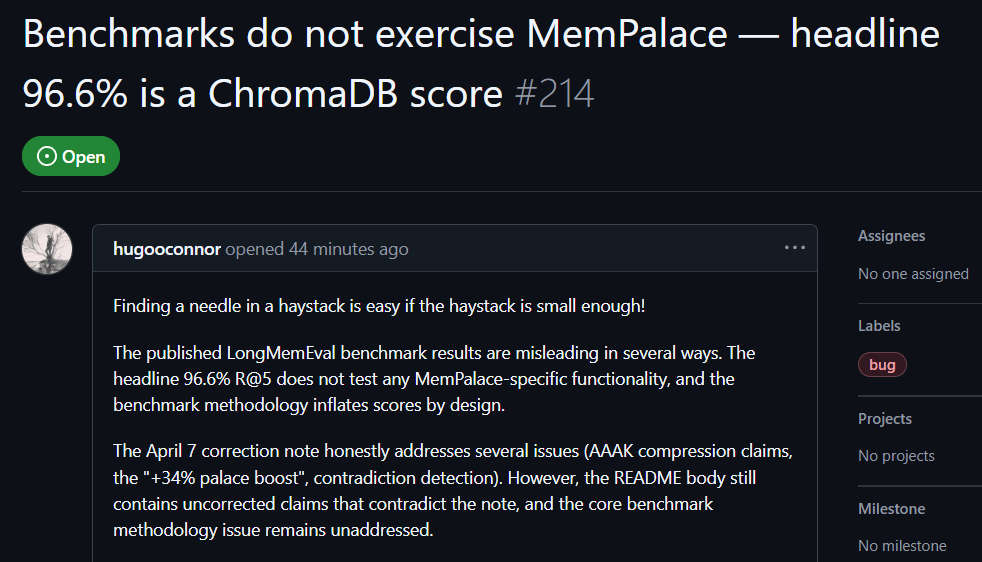
Источник изображения: GitHub GitHub-пользовательская проверка, MemPalace бенчмарк содержит элементы введения в заблуждение
При этом, хотя разработчики уже опубликовали исправляющее заявление и признали, что технология AAAK действительно прошла верификацию как сжатие с потерями, и пообещали скорректировать документацию и дизайн системы в соответствии с жесткой критикой со стороны сообщества, основной описательный документ проекта по-прежнему сохраняет множество не исправленных преувеличений: в том числе заявления о 30-кратном без потерь сжатии и приросте retrieval на 34%, а также сравнительные графики с другими конкурентами полностью без указания источников.
Исходный код MemPalace столкнулся с множеством Bug
По мере того как всё больше разработчиков скачивают тесты, на платформе GitHub появляется множество сообщений о Bug в исходном коде MemPalace.
Пользователь cktang88 перечислил несколько серьезных недостатков, включая то, что сжимающая команда не работает и приводит к сбою системы, ошибку в логике подсчета количества слов в аннотациях, а также неточность статистических данных при «копании» комнат, и то, что сервер при каждом вызове загружает все интерпретационные данные в память, создавая серьезную проблему чрезмерного расхода ресурсов.
Другие указанные проблемы включают, например, что система принудительно записывает имена членов семьи разработчика в стандартный конфигурационный файл, а также наличие жесткого ограничения в показе при запросе статуса — на уровне 10k записей.
Для решения этих проблем open-source сообщество уже начало активно заниматься исправлениями. Пользователь adv3nt3 подал несколькозапросовна исправления, включая правку статистических данных «копания», удаление заданных по умолчанию имен членов семьи и перенос (отсрочку) времени инициализации при запуске знаний-графа.** Позднее и разработчики признали эти ошибки и продолжают поэтапно исправлять код в рамках взаимодействия с сообществом.
Вайб-кодинг у Милы Джовович — крут, а маркетинговый подход — не крут
Что касается проекта MemPalace, пользователь Hacker News darkhanakh сделал такой вывод: у MemPalace возникает ощущение OpenClaw — то есть результаты бенчмарка искусственно подгоняются так, чтобы выглядели безупречно, а затем их упаковывают и продают как какой-то крупный прорыв.
Он считает, что базовая технология MemPalace, возможно, действительно может быть интересной, но при таких изъямах в методологии тестирования и при этом еще и продвигается идея «самого высокого публичного результата за всю историю» — это, по меньшей мере, не совсем уместно: «Но, правда, насчет того, что Мила Джовович играет в Vibe Coding — я думаю, это всё равно довольно круто».
Дополнительное чтение:
AI пишет код и снова косячит! Проблемы кибербезопасности в приложении «惜食獵人» (перекатный товар с истекающим сроком годности), GPS дома — полностью без защиты
Связанные статьи
Карапати раскрывает: полный метод создания личной базы знаний с помощью LLM
У основателя команды OpenAI и бывшего главного директора по ИИ в Tesla Андрея Карпатия появилась на X публикация о рабочем процессе «LLM Knowledge Bases» — он объяснил, как в последнее время перевёл большие объёмы использования токенов с «управления кодом» на «управление знаниями»: с помощью LLM он объединяет разрозненные статьи, материалы, папки, изображения в автоматизированную личную wiki, которую поддерживает в актуальном состоянии. Весь процесс уже накоплен в его собственных исследовательских проектах: около ~100 статей, ~400 тыс. слов, и всё это на протяжении всего времени LLM пишет и обновляет. Эта статья систематизирует полную настройку Karpathy и даёт разработчикам, которые хотят всё скопировать, список, который можно реализовать на практике.
Ключевая идея: raw-данные → компиляция LLM → wiki → Q&A
Философию дизайна Karpathy можно свести к одному
ChainNewsAbmedia2ч назад
Bitcoin Treasury Firm K Wave Media получила до $485M на создание инфраструктуры для ИИ
По данным ChainCatcher, компания K Wave Media, которая владеет биткоин-казначейством и котируется на Nasdaq, 4 мая объявила о стратегическом развороте в сторону инфраструктуры для ИИ, получив поддержку капитала в размере до 485 миллионов долларов для инвестиций в центры обработки данных, услуг аренды GPU, а также для приобретений и партнерств в сфере инфраструктуры ИИ.
Компания
GateNews4ч назад
Antimatter запускает план ИИ-ЦОД с финансированием в €300 млн
Antimatter — компания по облачной инфраструктуре для AI-нагрузок из Франции — запустилась 4 мая, объединив три существующие компании: Datafactory, Policloud и Hivenet. Компания привлекает 300 миллионов евро (351 миллион долларов США), чтобы развернуть 100 микромодулей дата-центров в 2026 году для AI-инференса
CryptoFrontier5ч назад
Министерство образования «館館有 AI» — библиотека бесплатно использует ChatGPT, Claude! Действующие время и место — в одном месте
Министерство образования продвигает инициативу «в каждом библиотечном учреждении есть AI»: начиная с IV квартала этого года в национальных библиотеках, включая Национальную библиотеку, в каждой библиотеке установят по 5 AI-компьютеров. Пользователи могут бесплатно пользоваться такими инструментами, как ChatGPT, Claude, Gemini, используя читательский билет, чтобы сократить разрыв в платном AI. Планируется расширение до 47 библиотек национальных университетов; финансирование будет обеспечиваться за счёт средств самих школ или за счёт грантов. При этом необходимо преодолеть такие вызовы, как распределение времени использования, управление учётными записями, вопросы приватности и лицензирования.
ChainNewsAbmedia6ч назад
Экономика AI-виртуальных моделей: Aitana, Emily и разбор 4 комплектов Markdown-систем
AI виртуальные модели из темы-эксперимента превратились в полноценный бизнес с доходом по несколько десятков тысяч долларов в месяц, а весь технический stack за 18 месяцев быстро созрел. В этой статье собраны три показательных кейса: Aitana López из The Clueless (Барселона, €10k в месяц), Emily Pellegrini, созданная анонимным автором (еженедельный доход около 10 тысяч долларов), а также недавний кейс «Maya», который распространяется на платформе X: по данным, студентка из Техаса собрала AI-виртуальную личность с помощью 4 файлов markdown, а в первый месяц на аккаунте OnlyFans заработала 43 тысячи долларов.
Aitana López: собственная виртуальная модель The Clueless, доход до €10 000 в месяц
Aitana López — это
ChainNewsAbmedia9ч назад
TipTip достигает прибыльности по EBITDA, поскольку ИИ усиливает развлекательное билетирование
Индонезийская развлекательная платформа для развлечений и впечатлений TipTip объявила 4 мая, что достигла корпоративной рентабельности по EBITDA в начале 2026 года благодаря контролю затрат, улучшению юнит-экономики и партнёрству с ведущим инвестором East Ventures.
Рост продаж билетов на развлечения
Развлекательное направление TipTip's entertainment t
CryptoFrontier11ч назад