GoogleのGemini 3 Deep Think大規模アップグレード:推論能力はOpus 4.6やGPT-5.2を圧倒し、「最も研究に優れたAI」になることを目指す
Googleは「Gemini 3 Deep Think」の大規模アップデートを発表しました。ARC-AGI-2テストにおいて、84.6%の高得点を記録し、Claude Opus 4.6(68.8%)やGPT-5.2(52.9%)を大きく上回り、Codeforcesでは「伝説の師範」レベルに到達しました。 (前回の概要:ChatGPTの学習モード登場:家庭教師の黄昏、それとも黄金の教育時代の夜明けか?) (背景補足:Googleが正式に「Gemini 3」をリリース!世界最高知能AIモデルの登場、その注目ポイントは?)
この記事の目次
- 試験だけじゃない、人間の誤りも捕捉
- 市場シェアの地殻変動
- 暗号産業への波紋
- 科学の決勝戦は始まったばかり
Googleは本日(13日)、Gemini 3 Deep Thinkの大規模アップグレードを発表しました。ARC-AGI-2(AIの背後にある推論能力を測るテストで、知識量ではなく規則の抽出力を問うもの)において、Deep Thinkは84.6%を獲得しました。
参考までに、Claude Opus 4.6(Thinking Maxモード)は68.8%、GPT-5.2(Thinking xhighモード)は52.9%、人間の平均は約60%です。
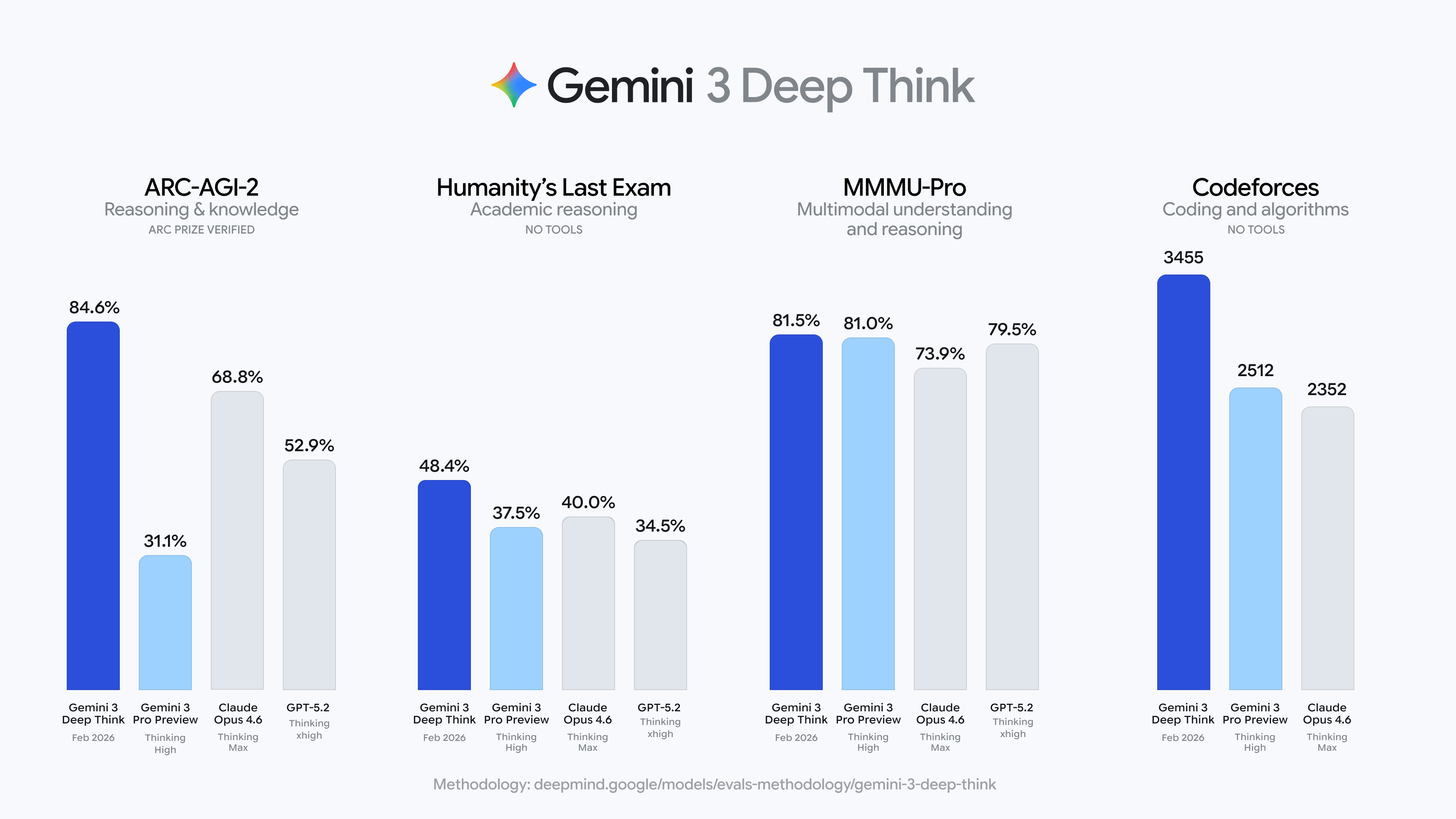
さらに驚くべきことに、元のARC-AGI-1ではDeep Thinkは96%を記録し、「AI最難関試験の一つ」とされる基準テストの壁をほぼ打ち破っています。
現在、Deep ThinkはGoogle AI Ultraのサブスクライバー向けに提供されており、APIは企業向けに早期アクセスが可能です。
試験だけじゃない、人間の誤りも捕捉
スコア以外の点として、Googleは発表の中で重要な詳細を明かしています。Deep Thinkは、同行の専門家による査読を経た数学論文をレビューしている際に、これまで誰も気づかなかった論理的な抜け穴を見つけ出しました。この論文はロッターズ大学の数学者によって確認されています。
この事例の重要性は、モデルの標準化テストでのパフォーマンスではなく、実際のオープンな科学の場面で示された能力にあります。査読は学術界の最も重要な品質管理メカニズムであり、AIがこの過程で安定して価値ある補助を提供できるなら、その科学研究の加速効果はスコア以上のものとなるでしょう。
Deep Thinkはまた、2025年の国際物理オリンピックと化学オリンピックの筆記試験で金メダルレベルに達し、CodeforcesのElo評価は3455点となり、「伝説の師範」レベルに到達しています。これは、世界でごく少数の人間プログラマーだけが到達できるレベルです。
さらに、「人類最後の試験」(Humanity’s Last Exam)と呼ばれる、各分野の専門家が設計し、意図的にAIの解答困難さを狙った基準テストでは、Deep Thinkは48.4%(ツール未使用)を記録し、新記録を樹立しました。
市場シェアの地殻変動
AIの三大巨頭による技術競争は、市場の構図を変えつつあります。ChatGPTの市場占有率はピーク時の87%から約68%に低下し、Geminiは5%未満から18%以上に急上昇、AnthropicのClaudeも企業向け市場を着実に侵食しています。
Googleの競争優位は、その配信力にあります。GeminiはAndroidシステム、Chromeブラウザ、Google Workspace、検索エンジンに内蔵されており、モデルの能力が競合と並んだ場合でも、Googleはチャネルの優位性を活かしてユーザーを獲得できます。
しかし、配信の優位性は両刃の剣です。Geminiの体験が十分でなければ、他の競合よりも早くユーザーの信頼を失う可能性があります。ユーザーは「受動的に接触」しているためです。一方、OpenAIのユーザーは積極的に支払っているため、より高い忍耐力と粘着性を持ちます。
暗号産業への波紋
AIの軍拡競争のたびに、計算基盤の需要が高まっています。最先端モデルの訓練に必要なGPUクラスターのコストは、2024年の数億ドル規模から、2026年には数十億ドル規模へと膨れ上がっています。これにより、次の二つの動きが生まれています。
**第一、ビットコインマイナーの変革。**マイニングの収益性が圧縮される中(JPモルガンは今週、BTCの生産コストを7.7万ドルと推定し、価格は6.6万ドル付近)、大規模な計算インフラを持つマイナーはAI計算サービスへの転換を加速させています。
高コストのマイニング企業は「撤退」ではなく、「転業」です。ビットコインの採掘からAI計算リースへのシフトです。
**第二、AIトークンのストーリー。**GoogleやOpenAI、Anthropicが大規模アップグレードを発表するたびに、分散型計算の関連トークン(例:分散型計算プロトコル)は短期的に投機的な盛り上がりを見せることがあります。
しかし、これらのトークンの根本的な問題は変わりません。分散型計算は遅延とスループットの面で、企業レベルのAI訓練のニーズにはまだ遠く及びません。ストーリーは速く進むかもしれませんが、インフラは追いついていません。
科学の決勝戦は始まったばかり
Deep Thinkのアップグレードにより、Googleは再びAI競争の先頭に立ちました。少なくとも推論と科学の分野ではそうです。しかし、Googleの発表の言葉には微妙な変化も見られます。それは、「最も賢い汎用AI」ではなく、「科学のために生まれたAI」と繰り返し強調している点です。
汎用AIの基準テストがますます飽和し、差別化が難しくなる中、「私のAIは科学研究を支援できる」という価値提案は、「スコアが高いAI」よりも説得力があります。Deep Thinkが本当に査読を安定して支援し、薬物発見を加速し、物理シミュレーションで人間の見落としを見つけられるなら、それはスコアランキング以上に意義深いことです。
問題は、「基準テストで高得点を取る」から「実際の科学場面で信頼できる補助を行う」までの距離は、Googleが示唆するよりも遥かに遠い可能性があることです。基準テストには正解がある一方、科学には正解がないからです。

関連記事
ETH短期で1.30%上昇:オンチェーンの大口送金と流動性集中による価格突破抵抗線