Les initiés affirment que DeepSeek V4 surpassera Claude et ChatGPT en programmation, lancement prévu dans quelques semaines
En bref
- DeepSeek V4 pourrait sortir dans quelques semaines, visant des performances de codage de niveau élite.
- Des insiders affirment qu’il pourrait surpasser Claude et ChatGPT sur des tâches de code à long contexte.
- Les développeurs sont déjà en ébullition avant une éventuelle disruption.
DeepSeek prévoit de lancer son modèle V4 vers la mi-février, et si les tests internes en sont une indication, les géants de l’IA de la Silicon Valley devraient être nerveux. La startup d’IA basée à Hangzhou pourrait viser une sortie autour du 17 février—le Nouvel An lunaire, naturellement—avec un modèle spécifiquement conçu pour les tâches de codage, selon The Information. Des personnes ayant une connaissance directe du projet affirment que V4 dépasse à la fois Claude d’Anthropic et la série GPT d’OpenAI dans des benchmarks internes, notamment lorsqu’il s’agit de gérer des prompts de code extrêmement longs. Bien sûr, aucun benchmark ni aucune information sur le modèle n’a été partagé publiquement, il est donc impossible de vérifier directement ces affirmations. DeepSeek n’a pas non plus confirmé les rumeurs.
Cependant, la communauté des développeurs n’attend pas de communiqué officiel. Les subreddits r/DeepSeek et r/LocalLLaMA s’animent déjà, les utilisateurs accumulent des crédits API, et les passionnés sur X ont rapidement partagé leurs prédictions selon lesquelles V4 pourrait consolider la position de DeepSeek comme le outsider déterminé à ne pas jouer selon les règles milliardaires de la Silicon Valley.
Anthropic a bloqué les abonnements à Claude dans des applications tierces comme OpenCode, et aurait coupé l’accès à xAI et OpenAI.
Claude et Claude Code sont excellents, mais pas encore 10x meilleurs. Cela poussera simplement d’autres laboratoires à accélérer le développement de leurs modèles/agents de codage.
DeepSeek V4 serait en cours de sortie…
— Yuchen Jin (@Yuchenj_UW) 9 janvier 2026
Ce ne serait pas la première disruption de DeepSeek. Lorsqu’elle a lancé son modèle de raisonnement R1 en janvier 2025, cela a déclenché une vente massive de $1 trillions sur les marchés mondiaux. La raison ? Le R1 de DeepSeek égalait le modèle o1 d’OpenAI sur les benchmarks de mathématiques et de raisonnement, malgré un coût de développement rapporté à seulement $6 millions—environ 68 fois moins cher que ce que dépensaient les concurrents. Son modèle V3 a ensuite atteint 90,2 % sur le benchmark MATH-500, dépassant largement les 78,3 % de Claude, et la mise à jour récente “V3.2 Speciale” a encore amélioré ses performances.
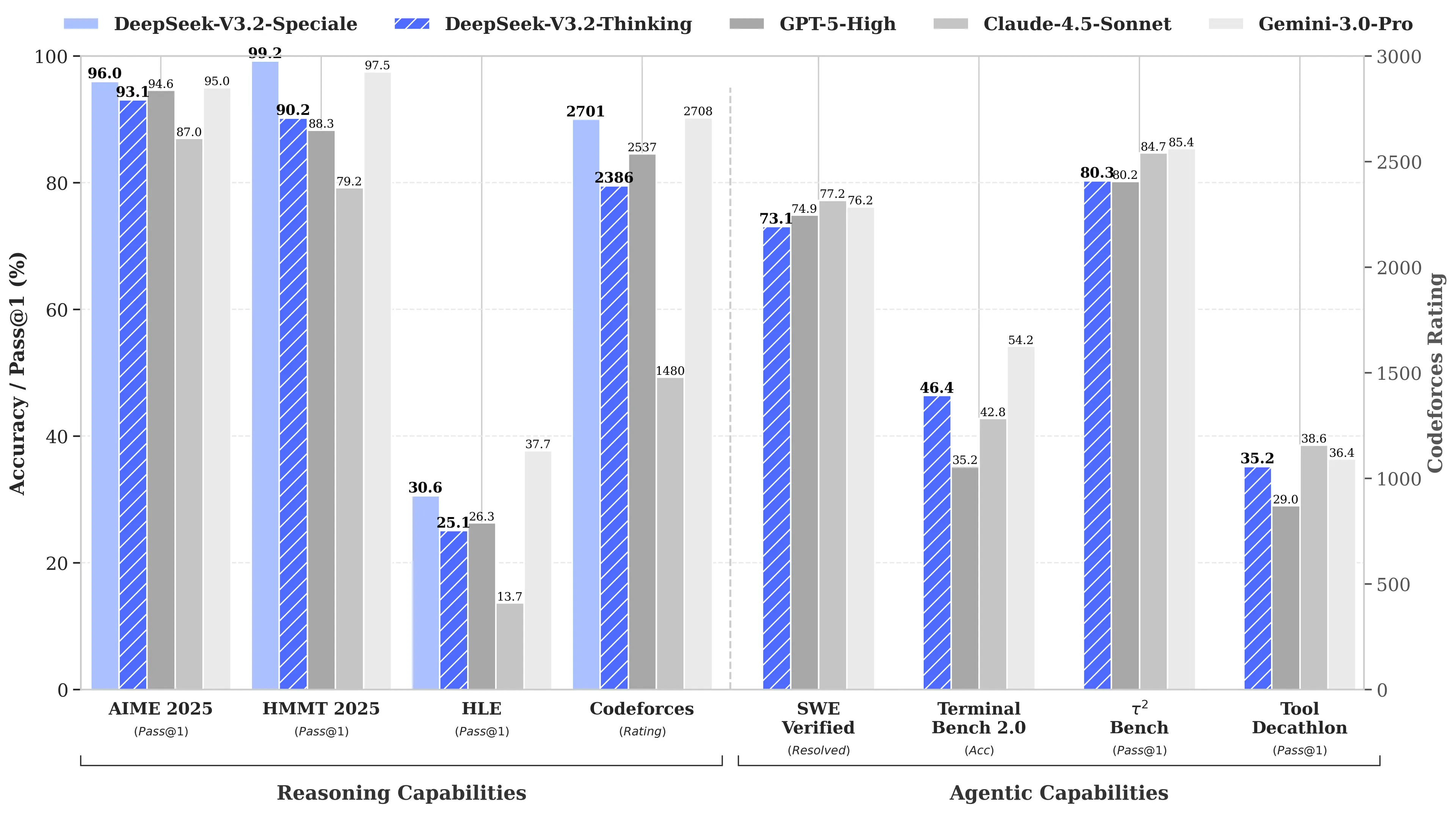
Image : DeepSeek
L’objectif principal de V4 en matière de codage serait une pivot stratégique. Alors que R1 mettait l’accent sur le raisonnement pur—logique, mathématiques, preuves formelles—V4 est un modèle hybride (raisonnement et tâches non-raisonnement) qui cible le marché des développeurs d’entreprise où une génération de code haute précision se traduit directement en revenus.
Pour prétendre à la domination, V4 devrait battre Claude Opus 4.5, qui détient actuellement le record vérifié du SWE-bench à 80,9 %. Mais si l’on se fie aux lancements passés de DeepSeek, cela pourrait ne pas être impossible à réaliser, même avec toutes les contraintes auxquelles un laboratoire d’IA chinois serait confronté.
La sauce secrète pas si secrète
Supposons que les rumeurs soient vraies, comment ce petit laboratoire pourrait-il réaliser un tel exploit ?
L’arme secrète de l’entreprise pourrait se trouver dans son article de recherche du 1er janvier : Manifold-Constrained Hyper-Connections, ou mHC. Co-écrit par le fondateur Liang Wenfeng, cette nouvelle méthode d’entraînement répond à un problème fondamental dans la montée en puissance des grands modèles de langage—comment augmenter la capacité d’un modèle sans qu’il devienne instable ou n’explose lors de l’entraînement.
Les architectures traditionnelles d’IA forcent toutes les informations à passer par un seul chemin étroit. mHC élargit ce chemin en plusieurs flux pouvant échanger des informations sans provoquer l’effondrement de l’entraînement.
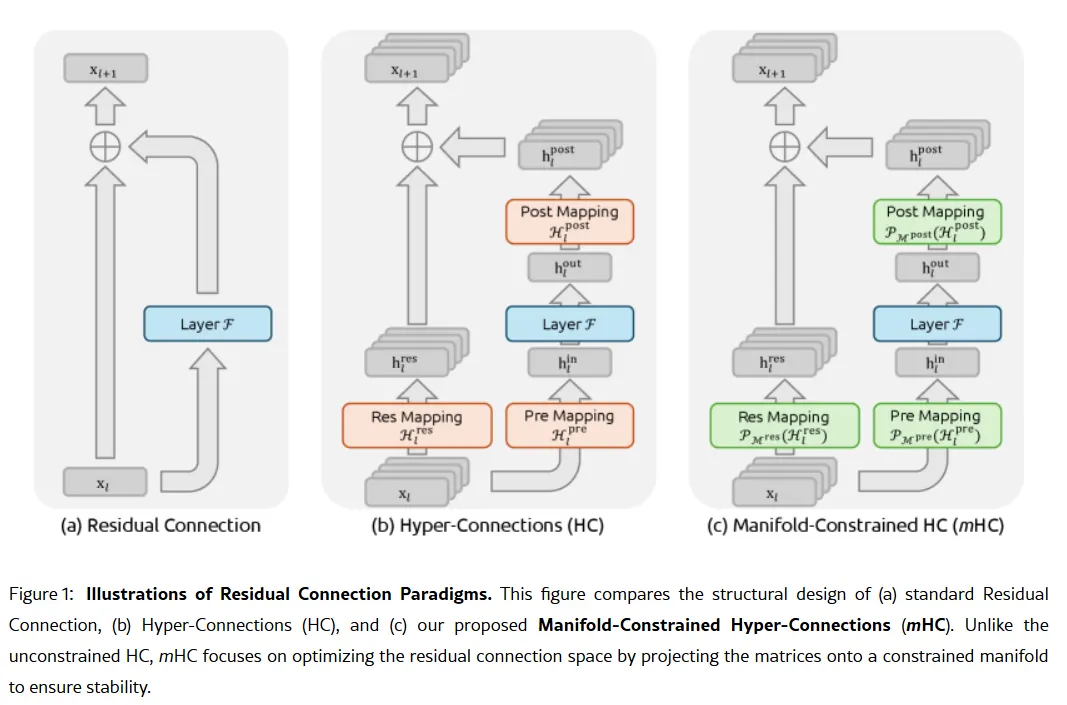
Image : DeepSeek
Wei Sun, analyste principal en IA chez Counterpoint Research, a qualifié mHC de “percée remarquable” dans des commentaires à Business Insider. La technique, a-t-elle dit, montre que DeepSeek peut “contourner les goulets d’étranglement du calcul et débloquer des avancées en intelligence,” même avec un accès limité aux puces avancées en raison des restrictions à l’exportation américaines. Lian Jye Su, analyste en chef chez Omdia, a noté que la volonté de DeepSeek de publier ses méthodes témoigne d’une “confiance nouvelle dans l’industrie chinoise de l’IA.” L’approche open-source de l’entreprise en a fait un favori parmi les développeurs qui la voient comme incarnant ce qu’OpenAI était avant de pivoter vers des modèles fermés et des levées de fonds de milliards de dollars.
Tout le monde n’est pas convaincu. Certains développeurs sur Reddit se plaignent que les modèles de raisonnement de DeepSeek gaspillent du calcul sur des tâches simples, tandis que des critiques soutiennent que les benchmarks de l’entreprise ne reflètent pas la complexité du monde réel. Un post Medium intitulé “DeepSeek Craint—Et j’en ai fini de faire semblant que ça n’existe pas” est devenu viral en avril 2025, accusant les modèles de produire du “nonsense de boilerplate avec des bugs” et des “bibliothèques hallucinnées.”
DeepSeek porte aussi un bagage. Des préoccupations concernant la vie privée ont hanté l’entreprise, certains gouvernements ayant interdit l’application native de DeepSeek. Les liens de l’entreprise avec la Chine et les questions sur la censure dans ses modèles ajoutent une friction géopolitique aux débats techniques.
Pourtant, l’élan est indéniable. DeepSeek a été largement adopté en Asie, et si V4 tient ses promesses en matière de codage, l’adoption par les entreprises en Occident pourrait suivre.
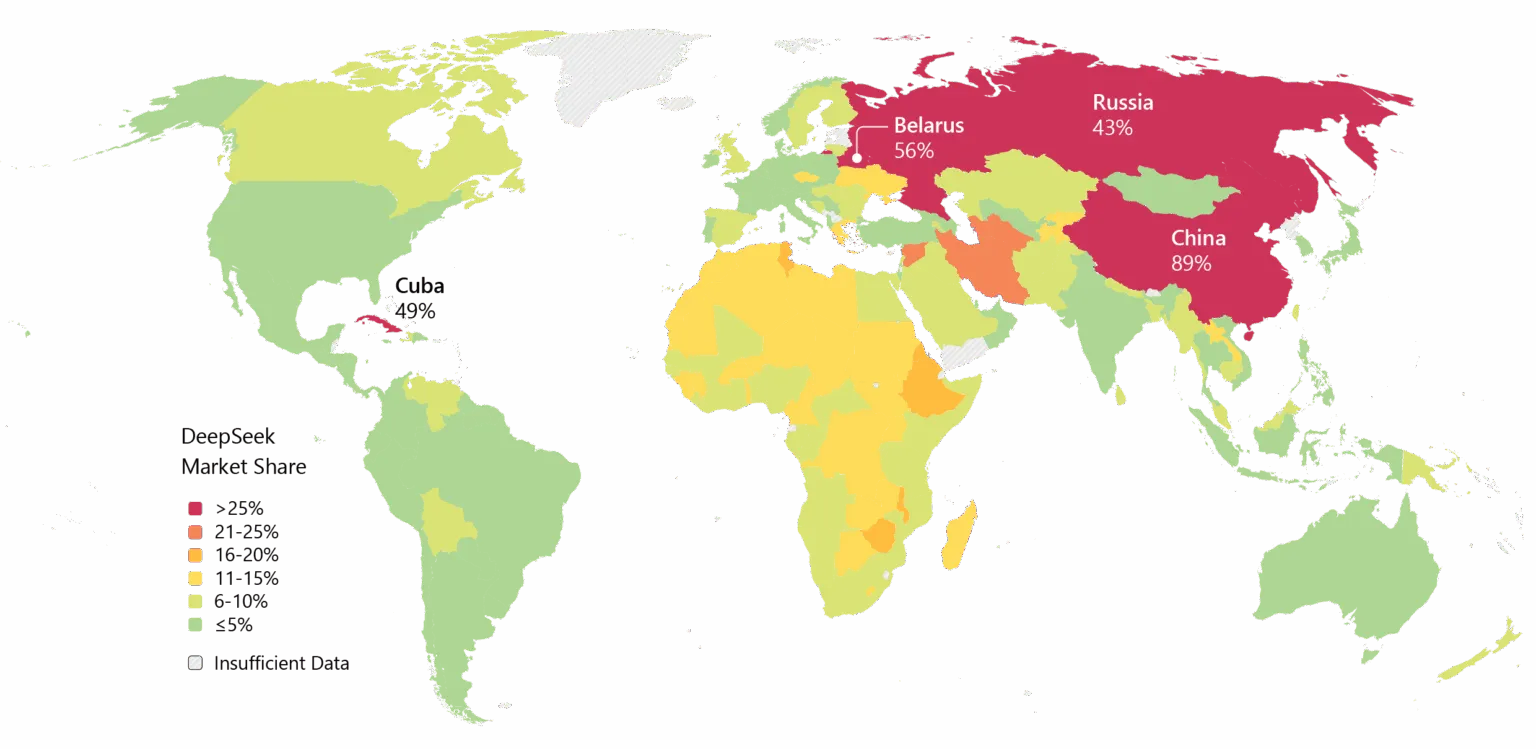
Image : Microsoft
Il y a aussi le timing. Selon Reuters, DeepSeek avait initialement prévu de lancer son modèle R2 en mai 2025, mais a prolongé la période après que le fondateur Liang soit devenu insatisfait de ses performances. Maintenant, avec V4 qui viserait février et R2 potentiellement en août, l’entreprise avance à un rythme qui suggère de l’urgence—ou de la confiance. Peut-être les deux.