Composants principaux d’un coprocesseur ZK
Un coprocesseur ZK se compose de plusieurs éléments fondamentaux qui fonctionnent ensemble pour décharger le calcul tout en préservant la vérifiabilité. Au cœur du système se trouve l’environnement d’exécution, souvent mis en œuvre sous la forme d’une machine virtuelle zero‑knowledge (zkVM) ou d’un compilateur de circuits spécifique à un domaine. Cet environnement interprète le code ou les tâches de calcul et les convertit en un circuit arithmétique adapté à la génération de preuves zero‑knowledge.
Le prouveur est l’entité qui effectue le calcul et génère la preuve cryptographique. Il prend les données d’entrée, exécute la logique requise off-chain et construit une preuve succincte qui atteste de l’exactitude du calcul sans révéler de détails sensibles. Le vérificateur, généralement un contrat intelligent déployé sur la blockchain cible, vérifie cette preuve en utilisant des ressources minimales. De par sa conception, la vérification est beaucoup moins exigeante en termes de calcul que le calcul original, ce qui permet une validation efficace on-chain.
L’interface de données, qui gère la manière dont le coprocesseur accède aux informations provenant de différentes sources,est un élément de soutien. Certains coprocesseurs interrogent directement les données on‑chain, tandis que d’autres agrègent des ensembles de données historiques ou externes, tels que des réseaux de stockage décentralisés ou des API off‑chain. L’intégrité de ces données doit également pouvoir être prouvée, souvent par des preuves de Merkle ou des engagements cryptographiques similaires.
Flux de calcul
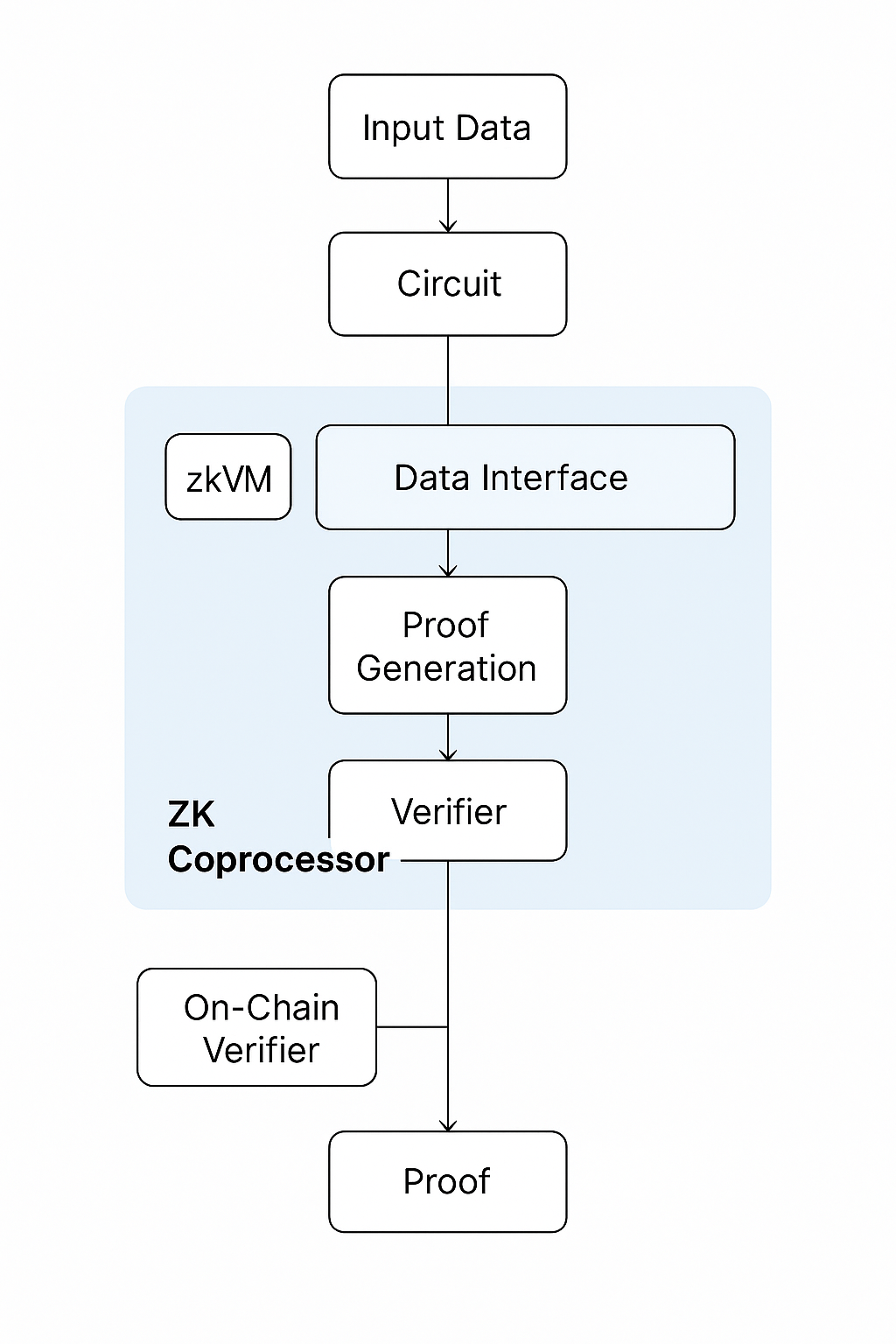
Le fonctionnement d’un coprocesseur ZK suit une séquence claire qui sépare le calcul lourd de la vérification légère. Le processus commence lorsqu’une application décentralisée ou un contrat intelligent demande un calcul qui ne peut pas être effectué efficacement on‑chain. Cette demande est envoyée au coprocesseur, qui recueille les données nécessaires, soit à partir de l’état de la blockchain, soit à partir de flux de données externes, soit à partir de sources fournies par l’utilisateur.
Une fois les entrées assemblées, le coprocesseur exécute le calcul dans son environnement zkVM ou circuit. Au cours de cette étape, le calcul est transformé en un circuit arithmétique structuré, ce qui permet de générer une preuve à zero‑knowledge. Cette preuve résume l’ensemble du processus d’exécution d’une manière qui peut être vérifiée sans réexécuter le calcul lui-même.
Une fois la preuve générée, elle est transmise à la blockchain. Le contrat intelligent vérificateur valide ensuite la preuve à l’aide de clés de vérification connues du public. Si la preuve est valide, le résultat du calcul est accepté et peut être utilisé pour mettre à jour l’état on‑chain, déclencher la logique du contrat intelligent ou servir d’entrée pour d’autres processus décentralisés. Ce flux garantit le maintien de l’intégrité des calculs sans sacrifier l’efficacité.
Techniques de génération de preuves
La génération de preuves est l’aspect de l’architecture du coprocesseur ZK qui nécessite le plus de calculs. Il s’appuie sur des méthodes cryptographiques avancées telles que les engagements polynomiaux et les multiplications multiscalaires, qui transforment un calcul en un ensemble de contraintes algébriques. Ces contraintes sont ensuite résolues pour produire une preuve succincte.
Les systèmes modernes optimisent ce processus grâce à plusieurs techniques. Les transformations de Fourier rapides (FFT ) ou les transformations théoriques des nombres (NTT) sont utilisées pour accélérer les opérations polynomiales, qui sont essentielles aux constructions zk‑SNARK et zk‑STARK. Larécursivité est une autre technique qui gagne en importance, permettant aux preuves d’être imbriquées dans d’autres preuves. Les systèmes de preuves récursives permettent une vérification incrémentale, où les grands calculs sont décomposés en preuves plus petites qui sont ensuite regroupées en une seule vérification succincte.
Ces optimisations sont essentielles pour adapter les coprocesseurs ZK aux charges de travail réelles. Sans eux, la génération de preuves pourrait devenir excessivement lente ou gourmande en ressources, ce qui compromettrait les avantages du calcul off‑chain.
Vérification on‑chain
La phase de vérification se déroule sur la blockchain cible et est intentionnellement conçue pour avoir un coût de calcul minimal. Une fois que le coprocesseur a soumis une preuve, le contrat de vérification exécute un algorithme de vérification en utilisant des paramètres précalculés. Dans les systèmes zk‑SNARK, il s’agit souvent d’un contrôle d’appariement en temps constant, tandis que les vérificateurs zk‑STARK s’appuient sur des engagements basés sur le hachage et des protocoles FRI (Fast Reed‑Solomon Interactive Oracle Proofs of Proximity).
La brièveté des preuves zero‑knowledge signifie que la vérification ne nécessite généralement que quelques kilo-octets de données et peut être exécutée dans une fraction du temps nécessaire à un calcul équivalent on‑chain. C’est cette efficacité qui rend les coprocesseurs ZK viables dans les environnements de production. La preuve confirme non seulement l’exactitude du calcul, mais aussi l’intégrité des entrées et le déterminisme de la sortie.
Modèle de sécurité et menaces
La sécurité des coprocesseurs ZK repose à la fois sur la solidité cryptographique et sur la conception du système. Sur le plan cryptographique, leurs garanties dépendent de la dureté des problèmes sous-jacents, tels que les appariements de courbes elliptiques ou les engagements basés sur le hachage. Tant que ces primitives restent sécurisées, les preuves qu’elles génèrent ne peuvent pas être falsifiées.
Cependant, des vulnérabilités peuvent apparaître dans la manière dont le coprocesseur est mis en œuvre ou dans la manière dont les données sont obtenues. Un prouveur malveillant pourrait tenter de contourner les contraintes du circuit ou introduire des données incorrectes dans le calcul. Pour pallier ce problème, les coprocesseurs s’appuient souvent sur des engagements publics, des racines Merkle ou des flux de données fiables pour prouver que les données utilisées sont légitimes. L’audit des circuits et une vérification formelle rigoureuse sont également essentiels pour prévenir les erreurs dans la conception elle-même.
Le système élargi doit également tenir compte de la vivacité et de la disponibilité. Si le coprocesseur est centralisé ou contrôlé par un seul opérateur, il introduit des hypothèses de confiance potentielles ou des risques de censure. Les nouveaux modèles visent à décentraliser les réseaux de coprocesseurs, ce qui permet à plusieurs prouveurs de rivaliser ou de collaborer pour générer des preuves, réduisant ainsi la dépendance à l’égard d’une seule entité.





