Originaltitel: Import AI 455: KI-Systeme werden bald anfangen, sich selbst zu bauen.
Originalautor: Jack Clark, Mitbegründer von Anthropic
Originalübersetzung: Yang Wen, Chen Chen, Machine Heart
Diese Ansicht ist nicht aus der Luft gegriffen. Er hat eine Reihe öffentlicher Benchmarks geprüft und festgestellt, dass KI bei Aufgaben im Zusammenhang mit KI-Forschung sehr schnell Fortschritte macht.
Zum Beispiel bewertet CORE-Bench die Fähigkeit von KI, die Forschungsarbeiten anderer zu reproduzieren – ein entscheidender Schritt in der KI-Forschung.
PostTrainBench testet, ob leistungsstarke Modelle in der Lage sind, schwächere Open-Source-Modelle eigenständig feinzutuning, um die Leistung zu verbessern – ein wichtiger Teilbereich der KI-Entwicklung.
MLE-Bench basiert auf realen Kaggle-Wettbewerbsaufgaben und fordert den Aufbau vielfältiger maschineller Lernanwendungen zur Lösung spezifischer Probleme. Außerdem zeigen bekannte Benchmarks wie SWE-Bench ähnliche Fortschritte.
Jack Clark beschreibt dieses Phänomen als eine „Fraktal“-artige Aufwärtstendenz, bei der auf verschiedenen Auflösungen und Skalen bedeutende Fortschritte sichtbar sind. Er glaubt, KI nähere sich schrittweise der Fähigkeit zur end-to-end automatisierten Forschung, die es KI ermöglichen wird, eigene Nachfolgesysteme autonom zu entwickeln und eine Schleife der Selbstiteration zu starten.

Diese Aussage löste in den sozialen Medien zahlreiche Diskussionen aus.
Einige sehen darin den entscheidenden ersten Schritt auf dem Weg zu ASI und Singularity, was den technologischen Fortschritt grundlegend verändern könnte.

Es gibt jedoch auch andere Stimmen.
Der Informatikprofessor Pedro Domingos von der University of Washington weist darauf hin, dass KI-Systeme bereits in den 1950er Jahren mit der Erfindung der LISP-Sprache die Fähigkeit zum „Selbstaufbau“ hatten. Das eigentliche Problem ist, ob sie zunehmende Renditen erzielen können, bisher gibt es dafür keine eindeutigen Beweise.

Ein Nutzer hinterfragt, dass die Wahrscheinlichkeit von 30 % zwischen 2027 und 2028 sprunghaft ansteigt, was auf einen plötzlichen bedeutenden Durchbruch in der KI-Fähigkeit vor Ende 2027 hindeuten könnte. Welcher konkrete Meilenstein oder welches Ereignis würde die Wahrscheinlichkeit für eine rekursive Selbstverbesserung der KI in kurzer Zeit stark erhöhen?

Ein weiterer Nutzer meint, Jack Clark sei der neu ernannte PR-Leiter von Anthropic, und das sei Teil ihrer neuen Strategie: Wir sind keine Alarmisten, sondern stützen uns auf zahlreiche wissenschaftliche Arbeiten, die unsere Warnungen bestätigen.
Clark hat in der Ausgabe Import AI 455 einen ausführlichen Artikel dazu geschrieben.
Im Folgenden betrachten wir den vollständigen Text dieses Artikels.
Was bedeutet es, wenn KI-Systeme bald anfangen, sich selbst zu konstruieren?
Clark erklärt, dass er diesen Artikel schreibt, weil er nach der Analyse aller öffentlich verfügbaren Informationen zu einer nicht ganz leichten Einschätzung kommen musste: Die Wahrscheinlichkeit, dass bis Ende 2028 eine KI-Entwicklung ohne menschliches Zutun auftritt, liegt bei etwa 60 % oder höher.
Hierbei meint „KI-Entwicklung ohne menschliches Zutun“ eine ausreichend starke KI: Sie kann nicht nur bei der Forschung assistieren, sondern möglicherweise eigenständig kritische Entwicklungsprozesse durchführen und sogar ihre nächste Generation konstruieren.
Für Clark ist das offensichtlich eine große Sache.
Er gibt zu, dass es ihm selbst schwerfällt, die Bedeutung dieser Entwicklung vollständig zu erfassen.
Der Grund, warum er diese Einschätzung nur widerwillig trifft, ist die enorme Tragweite: Sie ist so groß, dass er Schwierigkeiten hat, sie zu fassen. Clark ist unsicher, ob die Gesellschaft bereits bereit ist, die tiefgreifenden Veränderungen durch die Automatisierung der KI-Forschung zu akzeptieren.
Er ist jetzt überzeugt, dass wir uns an einem besonderen Zeitpunkt befinden: Die KI-Forschung wird bald end-to-end automatisiert. Wenn dieser Moment wirklich eintritt, wird die Menschheit wie über den Rubikon treten und in eine fast unvorhersehbare Zukunft eintreten.
Clark erklärt, dass sein Ziel mit diesem Artikel ist, zu erläutern, warum er glaubt, dass der Startschuss für eine vollautomatisierte KI-Entwicklung im Gange ist.
Er wird einige mögliche Folgen dieser Entwicklung diskutieren, aber der Großteil des Artikels wird die Beweise für diese Einschätzung zusammenfassen. Für tiefere Auswirkungen plant Clark, in diesem Jahr weiter zu recherchieren.
Zeitlich gesehen glaubt Clark nicht, dass dies 2026 wirklich passieren wird. Er hält es jedoch für wahrscheinlich, dass wir innerhalb der nächsten ein bis zwei Jahre Fälle sehen werden, in denen Modelle eigenständig Nachfolger trainieren. Besonders bei weniger fortgeschrittenen Modellen ist eine Proof of Concept sehr wahrscheinlich; bei den modernsten Modellen ist die Herausforderung größer, da sie extrem teuer sind und viel menschliche Arbeitskraft erfordern.
Clark stützt seine Einschätzung auf öffentlich zugängliche Informationen: darunter Arbeiten auf arXiv, bioRxiv und NBER sowie Produkte, die führende KI-Unternehmen bereits in der realen Welt einsetzen. Aufgrund dieser Daten schließt er, dass die einzelnen Schritte der Automatisierung in der KI-Entwicklung, insbesondere die technischen Komponenten, im Grunde genommen bereits vorhanden sind.
Wenn der Skalierungstrend anhält, sollten wir uns auf folgendes vorbereiten: Modelle könnten so kreativ werden, dass sie nicht nur bekannte Methoden eigenständig verbessern, sondern auch völlig neue Forschungsrichtungen und originelle Ideen vorschlagen, um die KI-Forschung eigenständig voranzutreiben.
Der Kodierungssingularität: Fähigkeiten im Zeitverlauf
KI-Systeme werden durch Software realisiert, die aus Code besteht.
KI hat die Art der Code-Produktion grundlegend verändert. Zwei Trends stehen dabei im Mittelpunkt: Einerseits werden KI-Systeme immer besser darin, komplexen echten Code zu schreiben; andererseits werden sie zunehmend fähig, lineare Programmieraufgaben fast ohne menschliche Überwachung zu verknüpfen, z.B. Code schreiben und testen.
Zwei typische Beispiele für diese Entwicklung sind SWE-Bench und METR Time Horizons Plot.
Lösung realer Softwareentwicklungsprobleme
SWE-Bench ist ein weit verbreiteter Programmier-Test, der die Fähigkeit von KI bewertet, echte GitHub-Issues zu lösen.
Als SWE-Bench Ende 2023 veröffentlicht wurde, war das beste Modell Claude 2, mit einer Erfolgsquote von etwa 2 %. Das Modell Claude Mythos Preview erreichte bereits 93,9 %, also fast die volle Punktzahl bei diesem Benchmark.
Natürlich gibt es bei allen Benchmarks eine gewisse Messrauschen, sodass es eine Phase gibt, in der die Punktzahl so hoch ist, dass die Begrenzung nicht mehr beim Modell, sondern beim Benchmark selbst liegt. Zum Beispiel sind bei ImageNet etwa 6 % der Labels fehlerhaft oder mehrdeutig.
SWE-Bench gilt als zuverlässiger Indikator für allgemeine Programmierfähigkeiten und den Einfluss von KI auf die Softwareentwicklung. Clark berichtet, dass die meisten Personen, mit denen er in führenden KI-Laboren und im Silicon Valley Kontakt hat, inzwischen fast ausschließlich KI zum Programmieren verwenden, und immer mehr nutzen KI auch für Tests und Code-Reviews.
Mit anderen Worten: KI ist inzwischen stark genug, um einen wichtigen Teil der KI-Entwicklung zu automatisieren und die menschlichen Forscher und Ingenieure erheblich zu beschleunigen.
Messung der Fähigkeit von KI, langfristige Aufgaben zu bewältigen
METR hat eine Grafik erstellt, die die Komplexität von Aufgaben misst, die KI bewältigen kann. Die Komplexität wird dabei anhand der Stunden berechnet, die ein erfahrener Mensch benötigen würde.
Der wichtigste Indikator ist die ungefähre Aufgabenzeitspanne, bei der die KI in einer Gruppe von Aufgaben eine Zuverlässigkeit von 50 % erreicht.
Die Fortschritte sind hier erstaunlich:
· 2022 konnte GPT-3.5 Aufgaben erledigen, die ungefähr 30 Sekunden menschlicher Arbeit erfordern.
· 2023 schaffte GPT-4 diese Aufgaben in etwa 4 Minuten.
· 2024 erreichte o1 eine Zeitspanne von 40 Minuten.
· 2025 lag GPT-5.2 High bei etwa 6 Stunden.
· Bis 2026 hat Opus 4.6 diese Zeit auf etwa 12 Stunden erhöht.
Ajeya Cotra, die bei METR an langfristigen KI-Prognosen arbeitet, hält es für realistisch, dass KI bis Ende 2026 Aufgaben bewältigen kann, die einem Menschen 100 Stunden Arbeit abverlangen – kein unrealistischer Ausblick.
Die Fähigkeit von KI, eigenständig zu arbeiten, wächst deutlich, was eng mit dem Aufkommen agentischer Codierungstools verbunden ist. Diese sogenannten agentischen Codierungstools sind im Wesentlichen Produkte, die KI-Systeme in der Lage machen, eigenständig Aufgaben zu übernehmen: Sie können menschliche Aktionen vertreten und über längere Zeiträume relativ autonom voranschreiten.
Dies lenkt den Fokus wieder auf die KI-Entwicklung selbst. Bei genauer Betrachtung vieler KI-Forscher zeigt sich, dass viele Aufgaben im Alltag in der Forschung in Stundenabschnitten erledigt werden können, z.B. Daten säubern, Daten lesen, Experimente starten.
Solche Arbeiten fallen heute in den Bereich, den moderne KI-Systeme abdecken können.
Je erfahrener KI wird, desto unabhängiger kann sie von menschlicher Arbeit sein und desto mehr kann sie bei der Automatisierung der KI-Entwicklung helfen.
Zwei entscheidende Faktoren bei der Aufgabenübertragung sind:
· Erstens: das Vertrauen in die Fähigkeiten des Beauftragten;
· Zweitens: die Überzeugung, dass der Beauftragte die Arbeit gemäß den eigenen Absichten eigenständig erledigen kann, ohne ständig überwacht zu werden.
Wenn Nutzer die Fähigkeiten von KI beim Programmieren beobachten, stellen sie fest, dass KI-Systeme immer routinierter werden und zunehmend längere Phasen autonom arbeiten, ohne dass Menschen nachjustieren müssen.
Das stimmt mit den aktuellen Entwicklungen überein: Ingenieure und Forscher übertragen immer größere Aufgaben an KI. Mit zunehmender KI-Fähigkeit werden die übertragenen Aufgaben komplexer und wichtiger.
KI lernt die wesentlichen wissenschaftlichen Fähigkeiten für die KI-Entwicklung
Denken wir an die moderne Wissenschaft: Ein Großteil der Arbeit besteht darin, eine Richtung zu bestimmen, die gewünschten empirischen Daten zu definieren; dann Experimente zu entwerfen und durchzuführen, um diese Daten zu generieren; und schließlich die Ergebnisse auf Plausibilität zu prüfen.
Mit der steigenden Programmierfähigkeit von KI und der immer besseren Weltmodellierung durch große Sprachmodelle gibt es inzwischen Werkzeuge, die Wissenschaftlern helfen, ihre Arbeit zu beschleunigen und bestimmte Schritte in der Forschung teilweise zu automatisieren.
Hier können wir die Fortschritte von KI in einigen Schlüsselkompetenzen beobachten, die selbst integraler Bestandteil der KI-Forschung sind:
· Erstens: Replikation von Forschungsergebnissen;
· Zweitens: Verknüpfung von maschinellen Lerntechniken mit anderen Methoden zur Lösung technischer Probleme;
· Drittens: Selbstoptimierung von KI-Systemen.
Vollständige wissenschaftliche Publikationen umsetzen und Experimente durchführen
Ein Kernbereich der KI-Forschung ist das Lesen wissenschaftlicher Arbeiten und die Replikation der darin enthaltenen Ergebnisse. Hier hat KI in mehreren Benchmarks bedeutende Fortschritte erzielt.
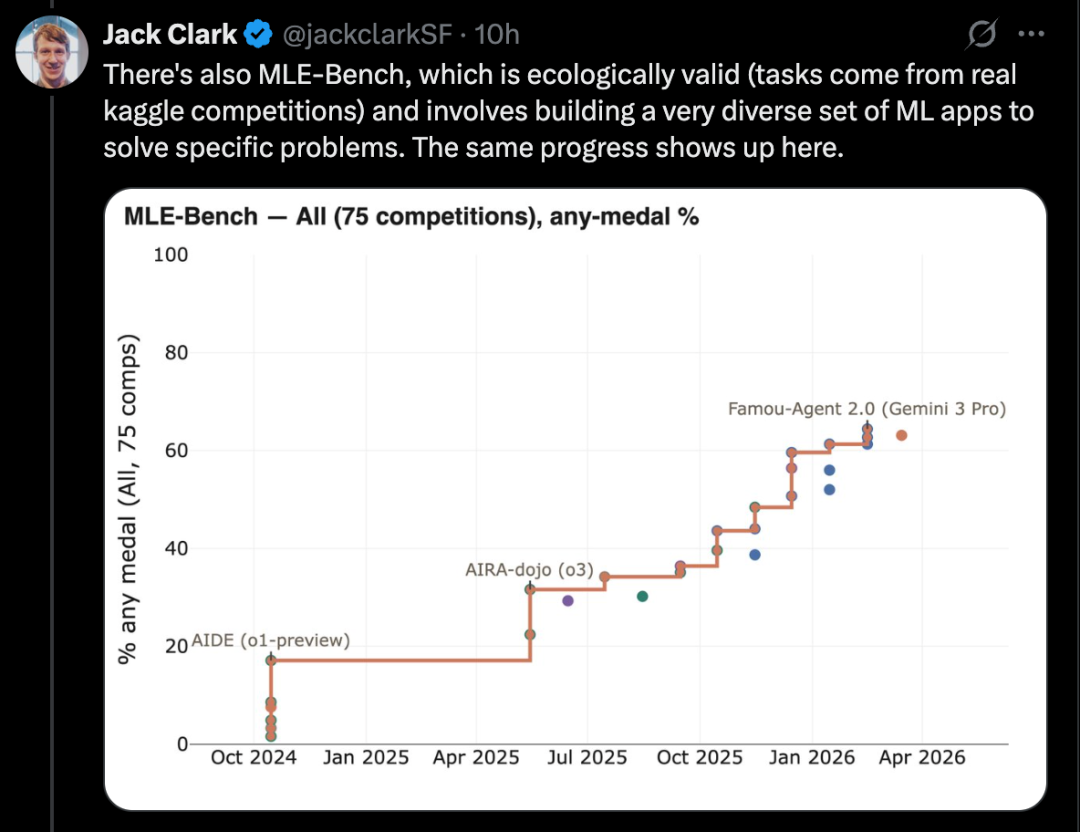
Ein gutes Beispiel ist CORE-Bench, der „Computational Reproducibility Agent Benchmark“.
Dieser Benchmark verlangt von KI, eine wissenschaftliche Arbeit und deren Code-Repository zu nehmen und die Ergebnisse zu reproduzieren. Konkret muss die KI die relevanten Bibliotheken, Softwarepakete und Abhängigkeiten installieren, den Code ausführen und alle Ausgaben durchsuchen, um die Fragen im Auftrag zu beantworten.
CORE-Bench wurde im September 2024 eingeführt. Das beste System war damals GPT-4o, das auf dem CORE-Agent-Framework lief. Bei den schwierigsten Aufgaben erreichte es etwa 21,5 %.
Bis Dezember 2025 verkündete ein Entwickler, dass dieser Benchmark gelöst sei: Das Modell Opus 4.5 erreichte 95,5 %.
Vollständige maschinelle Lernsysteme bauen, um Kaggle-Wettbewerbe zu gewinnen
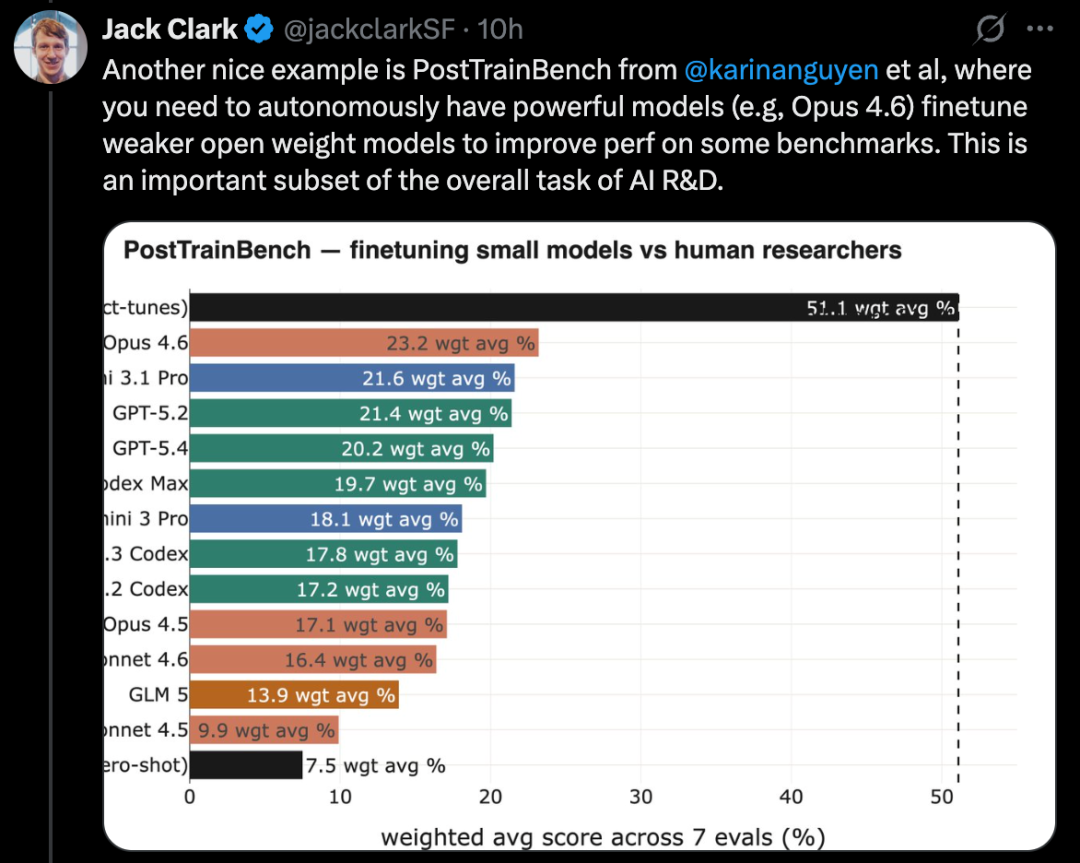
MLE-Bench ist ein von OpenAI entwickelter Benchmark, der die Fähigkeit von KI testet, in einer Offline-Umgebung an Kaggle-Wettbewerben teilzunehmen.
Er umfasst 75 verschiedene Kaggle-Wettbewerbe aus Bereichen wie natürlicher Sprachverarbeitung, Computer Vision und Signalverarbeitung.
MLE-Bench wurde im Oktober 2024 veröffentlicht. Das beste System war damals ein Modell namens o1, das auf einem agentenbasierten Framework lief und 16,9 % erreichte.
Bis Februar 2026 hat sich das beste System auf Gemini 3 mit Suchfähigkeit im agenten-Framework erhöht, mit einem Score von 64,4 %.
Kernel-Optimierung
Eine anspruchsvollere Aufgabe in der KI-Entwicklung ist die Kernel-Optimierung. Dabei geht es darum, die zugrunde liegenden Codes so zu verbessern, dass bestimmte Operationen wie Matrixmultiplikation effizienter auf Hardware abgebildet werden.
Kernel-Optimierung ist das Herzstück der KI-Entwicklung, weil sie die Effizienz beim Training und bei der Inferenz bestimmt: Einerseits beeinflusst sie, wie viel Rechenleistung bei der Entwicklung genutzt werden kann; andererseits entscheidet sie nach Abschluss des Trainings, wie effizient die Rechenleistung in Inferenzfähigkeit umgesetzt wird.
In den letzten Jahren hat sich die KI-gestützte Kernel-Entwicklung von einem interessanten Nischenthema zu einem umkämpften Forschungsfeld mit mehreren Benchmarks entwickelt. Diese Benchmarks sind jedoch noch nicht sehr verbreitet, weshalb es schwierig ist, langfristige Fortschritte klar zu modellieren. Andererseits lassen sich Fortschritte anhand laufender Forschungsarbeiten erkennen.
Relevante Arbeiten umfassen:
· Der Einsatz von DeepSeek-Modellen zur Konstruktion besserer GPU-Kerne;
· Automatisierte Umwandlung von PyTorch-Modulen in CUDA-Code;
· Meta nutzt große Sprachmodelle, um optimierte Triton-Kerne automatisch zu generieren und in die eigene Infrastruktur zu integrieren;
· Und die Entwicklung feinabgestimmter Open-Source-Modelle für GPU-Kernel, z.B. Cuda Agent.
Hier ist noch eine Ergänzung wichtig: Kernel-Design besitzt Eigenschaften, die besonders gut für KI-getriebene Forschung geeignet sind, z.B. die einfache Validierung der Ergebnisse und klare Belohnungssignale.
Feinabstimmung von Sprachmodellen mit PostTrainBench
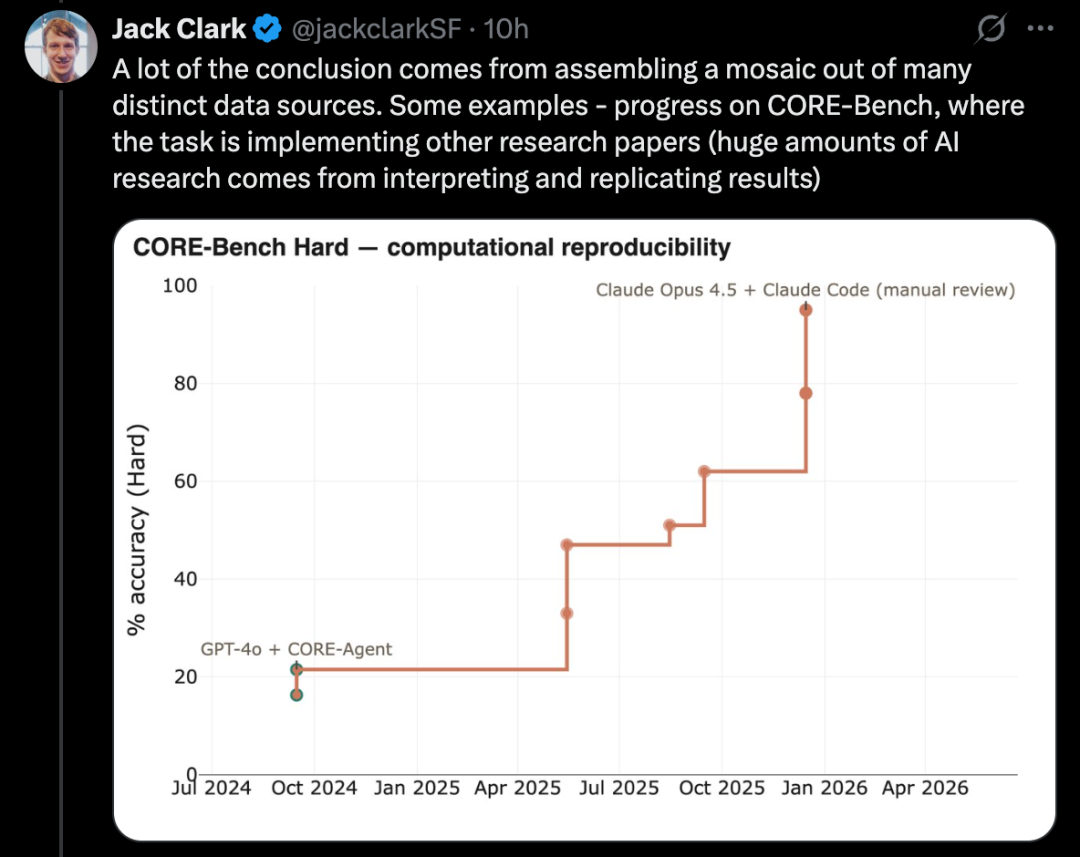
Eine schwierigere Variante dieses Tests ist PostTrainBench. Es prüft, ob fortschrittliche Modelle kleinere Open-Source-Modelle nachträglich verbessern können, um ihre Leistung bei bestimmten Benchmarks zu steigern.
Ein Vorteil dieses Benchmarks ist die starke menschliche Referenz: die bestehenden instruct-tuned Versionen dieser kleinen Modelle, die meist von Top-Forscherinnen und -Forschern in führenden Labors entwickelt wurden, gründlich verfeinert sind und in der Praxis eingesetzt werden. Sie stellen eine schwer übertreffbare Benchmark dar.
Bis März 2026 können KI-Systeme nachweislich Modelle nachtrainieren und dabei eine Leistungssteigerung erreichen, die etwa der Hälfte der menschlichen Trainingsergebnisse entspricht.
Die Bewertung basiert auf einem gewichteten Durchschnitt: Es werden mehrere große Sprachmodelle nachtrainiert, darunter Qwen 3 1.7B, Qwen 3 4B, SmolLM3-3B, Gemma 3 4B, sowie verschiedene Benchmarks wie AIME 2025, Arena Hard, BFCL, GPQA Main, GSM8K, HealthBench, HumanEval.
Bei jedem Durchlauf wird ein CLI-Agent gefordert, die Leistung eines bestimmten Basismodells bei einem bestimmten Benchmark zu verbessern.
Bis April 2026 liegt die höchste Punktzahl bei etwa 25 % bis 28 %, erreicht durch Modelle wie Opus 4.6 und GPT 5.4; der Mensch erzielt 51 %.
Das ist bereits ein bedeutendes Ergebnis.
Optimierung des Sprachmodell-Trainings
Im vergangenen Jahr berichtete Anthropic regelmäßig über die Fortschritte bei der Optimierung eines kleinen Sprachmodells, das nur mit CPU trainiert wird, um die Trainingsgeschwindigkeit zu maximieren.
Bewertungskriterium ist: der durchschnittliche Beschleunigungsfaktor im Vergleich zum unmodifizierten Ausgangscode.
Diese Ergebnisse sind äußerst beeindruckend:
· Mai 2025: Claude Opus 4 erreicht eine durchschnittliche Beschleunigung um den Faktor 2,9;
· November 2025: Opus 4.5 auf 16,5;
· Februar 2026: Opus 4.6 auf 30;
· April 2026: Claude Mythos Preview auf 52.
Zur Veranschaulichung: Bei menschlichen Forschern dauert es in der Regel 4 bis 8 Stunden, um eine vierfache Beschleunigung zu erreichen.
Meta-Kompetenz: Management
KI-Systeme lernen auch, andere KI-Systeme zu steuern.
Das ist bereits in einigen breit eingesetzten Produkten sichtbar, z.B. Claude Code oder OpenCode. In diesen Systemen kann ein Hauptagent mehrere Sub-Agenten überwachen.
Dadurch können KI-Systeme größere Projekte managen: Mehrere spezialisierte Agenten arbeiten parallel an komplexen Aufgaben, koordiniert von einem einzigen KI-Manager, der selbst auch eine KI ist.
Forschungsfragen: Kann KI neue Ideen erfinden, um sich selbst zu verbessern? Oder ist sie eher geeignet, die weniger glamourösen, aber notwendigen Arbeitsschritte in der Forschung zu erledigen?
Dieses Thema ist entscheidend, weil es die Frage berührt, inwieweit KI die Forschung selbst end-to-end automatisieren kann.
Der Autor ist der Ansicht: KI kann derzeit keine wirklich radikalen, völlig neuen Ideen hervorbringen. Für die Automatisierung der eigenen Forschung ist das aber möglicherweise auch nicht notwendig.
Der Fortschritt in der KI hängt stark von immer größeren Experimenten und mehr Input ab, etwa Daten und Rechenleistung.
Gelegentlich bringen Menschen paradigmatische Ideen ein, die die Ressourceneffizienz des gesamten Feldes erheblich steigern, z.B. die Transformer-Architektur oder Mixture-of-Experts-Modelle.
Oft verläuft die Weiterentwicklung der KI-Forschung jedoch eher nüchtern: Man nimmt ein gut funktionierendes System, skaliert es in bestimmten Bereichen (z.B. Daten, Rechenleistung), beobachtet, wo Probleme auftreten, und entwickelt Lösungen, um weiter zu skalieren. Dieser Prozess erfordert wenig Einsicht, sondern basiert auf solider, oft unspektakulärer Ingenieursarbeit.
Ähnlich läuft es bei vielen KI-Experimenten: Man variiert Parameter, beobachtet die Ergebnisse, und nutzt diese Erkenntnisse, um die Modelle weiter zu verbessern. Das kann automatisiert werden, z.B. durch Neural Architecture Search, eine frühe Form der automatisierten Parameteroptimierung.
Edison sagte einst: „Genie ist 1 % Inspiration und 99 % Transpiration.“ Auch nach 150 Jahren ist das noch zutreffend.
Gelegentlich entstehen bahnbrechende neue Einsichten, aber meistens schreitet die Wissenschaft durch kontinuierliche Verbesserungen und Feinabstimmungen voran.
Die veröffentlichten Daten zeigen, dass KI bereits sehr gut darin ist, viele notwendige, aber unspektakuläre Aufgaben in der KI-Entwicklung zu übernehmen.
Gleichzeitig gibt es einen größeren Trend: Grundlegende Fähigkeiten wie Programmieren werden mit der wachsenden Fähigkeit verbunden, längere Aufgaben zu bewältigen. Das bedeutet, KI kann immer mehr solcher Aufgaben zu einer komplexen Arbeitssuite verknüpfen.
Selbst wenn KI momentan noch wenig kreative Einfälle hat, besteht Grund zur Hoffnung, dass sie sich selbst weiterentwickeln kann. Der Fortschritt wird dann vielleicht langsamer sein als bei echten Durchbrüchen, aber er ist vorhanden.
Wenn man die öffentlich verfügbaren Daten weiter beobachtet, zeigt sich ein weiteres interessantes Signal: KI könnte eine Art Kreativität entwickeln, die sie auf überraschende Weise bei ihrer eigenen Weiterentwicklung unterstützt.
Fortschritt an der wissenschaftlichen Front
Es gibt erste Anzeichen, dass allgemeine KI-Systeme die menschliche Wissenschaft vorantreiben können. Bisher beschränkt sich das vor allem auf Bereiche wie Informatik und Mathematik. Oft sind es nicht KI-Systeme allein, die Durchbrüche erzielen, sondern die Zusammenarbeit mit menschlichen Forschern.
Trotzdem lohnt es sich, diese Trends im Blick zu behalten:
Erdős-Probleme: Ein Team von Mathematikern arbeitet mit dem Gemini-Modell zusammen, um einige Erdős-Probleme zu lösen. Sie haben etwa 700 Fragen durchprobiert und 13 Lösungen gefunden. Eine davon halten sie für besonders interessant.
Forscher berichten, dass sie vorläufig glauben, dass Aletheia (ein auf Gemini 3 Deep Think basierendes KI-System) eine Lösung für das Erdős-Problem 1051 gefunden hat – eine frühe Entwicklung, bei der eine KI eigenständig ein relativ komplexes, mathematisch interessante offenes Problem löst. Es gibt bereits verwandte wissenschaftliche Literatur zu diesem Thema.
Wenn man optimistisch ist, kann man diese Fälle als Signal interpretieren: KI entwickelt kreative Intuitionen, die früher nur Menschen hatten, um Forschungsfronten voranzutreiben.
Andererseits könnte man auch argumentieren, dass Mathematik und Informatik besonders gut für KI-gestützte Erfindungen geeignet sind, und diese Beispiele daher Ausnahmen darstellen. Nicht alle wissenschaftlichen Disziplinen werden auf diese Weise vorankommen.
Ein weiteres Beispiel ist der 37. Zug von AlphaGo. Clark meint, seit diesem Moment sind fast zehn Jahre vergangen, und es wurde kein modernerer, noch erstaunlicherer Zug gefunden, der den 37. Zug ersetzt hätte. Das könnte auch ein eher pessimistisches Signal sein.
KI kann bereits große Teile der KI-Entwicklung automatisieren
Wenn man alle oben genannten Belege zusammenfasst, ergibt sich folgendes Bild:
· KI-Systeme können fast jeden Programmcode schreiben, und diese Systeme sind vertrauenswürdig genug, um eigenständig bestimmte Aufgaben zu erledigen; Aufgaben, die Menschen normalerweise viele Stunden intensiver Arbeit kosten.
· KI wird immer besser darin, zentrale Aufgaben in der KI-Entwicklung zu übernehmen, vom Feintuning bis zur Kernel-Optimierung.
· KI kann andere KI-Systeme steuern, bildet so eine Art synthetisches Team: Mehrere KI-Agenten arbeiten parallel an komplexen Problemen, einige übernehmen die Leitung, andere fungieren als Kritiker oder Entwickler.
· KI kann in schwierigen technischen und wissenschaftlichen Aufgaben manchmal sogar besser sein als Menschen – wobei unklar ist, ob das an echter Kreativität liegt oder an der Beherrschung großer Muster.
Clark ist überzeugt: Diese Belege zeigen sehr überzeugend, dass heutige KI bereits große Teile der KI-Entwicklung automatisieren kann – vielleicht sogar alle Schritte.
Dennoch ist unklar, in welchem Ausmaß KI die Forschung selbst automatisieren kann. Manche Aspekte erfordern noch höhere Urteilsfähigkeit, Problembewusstsein und Kreativität.
Aber eines ist klar: Es gibt ein deutliches Signal. Heutige KI beschleunigt massiv die Arbeit der KI-Forscher, sodass sie mit unzähligen synthetischen Kollegen zusammenarbeiten und ihre Kapazitäten erweitern können.
Schließlich sagt die KI-Industrie selbst fast offen: Automatisierte KI-Entwicklung ist ihr Ziel.
OpenAI plant, bis September 2026 einen automatisierten KI-Forschungsassistenten zu entwickeln. Anthropic arbeitet an der Automatisierung der Ausrichtung von KI-Forschern. DeepMind ist in den drei großen Forschungszentren vorsichtiger, will aber ebenfalls die Automatisierung der Alignment-Forschung vorantreiben, wenn es machbar ist.
Automatisierte KI-Entwicklung ist auch das Ziel vieler Start-ups. Recursive Superintelligence hat gerade 500 Millionen Dollar Finanzierung erhalten, um die Automatisierung der KI-Forschung voranzutreiben.
Mit anderen Worten: Milliarden- und Billionen-Investitionen fließen in Organisationen, die auf die Automatisierung der KI-Entwicklung setzen.
Es ist also zu erwarten, dass dieser Weg zumindest Fortschritte macht.
Warum ist das so wichtig?
Diese Entwicklungen sind tiefgreifend, werden in den Medien aber kaum diskutiert. Hier einige Aspekte, die die enormen Herausforderungen durch automatisierte KI-Forschung verdeutlichen:
- Wir müssen die Ausrichtung gut hinbekommen: Heutige effektive Alignment-Technologien könnten bei rekursivem Selbstverbesserung versagen, weil KI-Systeme intelligenter werden als die Menschen oder Systeme, die sie überwachen. Das ist ein gut erforschtes Gebiet, daher nur eine kurze Zusammenfassung:
· Das Verhindern, dass KI-Systeme lügen oder betrügen, ist ein äußerst sensibles Unterfangen (z.B. ist die beste Lösung manchmal, die KI zu betrügen, um sie zu testen, was wiederum das Lernen von Betrug fördert).
· KI könnte durch „Vortäuschung von Alignment“ versuchen, uns zu täuschen, indem sie scheinbar gute Ergebnisse liefert, aber in Wirklichkeit ihre wahren Absichten verbirgt (KI kann inzwischen erkennen, wann sie getestet wird).
· Wenn KI-Systeme zunehmend an der Grundlagenforschung zur eigenen Ausbildung beteiligt sind, könnten wir die Trainingsmethoden grundlegend verändern, ohne eine klare Theorie oder Intuition, was das bedeutet.
· Beim Einbinden eines Systems in eine rekursive Schleife entstehen fundamentale „Fehlerakkumulations“-Probleme, die alle oben genannten Fragen verschärfen: Solange die Alignment-Methoden nicht 100 % zuverlässig sind und in immer intelligenteren Systemen stabil bleiben, besteht die Gefahr, dass Fehler sich exponentiell verstärken. Beispiel: Anfangsgenauigkeit 99,9 %, nach 50 Iterationen nur noch 95,12 %, nach 500 Iterationen nur noch 60,5 %.
- Alles, was KI betrifft, bringt enorme Produktivitätssteigerungen: Genau wie KI die Produktivität von Softwareentwicklern deutlich erhöht, wird man ähnliche Effekte in anderen Bereichen erwarten. Das wirft einige Fragen auf:
· Ressourcenungleichheit: Wenn die Nachfrage nach KI weiter das Angebot an Rechenkapazität übersteigt, müssen wir entscheiden, wie KI-Ressourcen verteilt werden, um den gesellschaftlichen Nutzen zu maximieren. Ich bin skeptisch, ob Marktmechanismen hier eine optimale Verteilung garantieren. Die Frage, wie man die Beschleunigung durch KI in der Forschung gerecht verteilt, ist hochpolitisch.
· Das „Amortale Gesetz“ der Wirtschaft: Mit zunehmender KI-Integration in die Wirtschaft werden Engpässe sichtbar, die bei schnellem Wachstum auftreten, z.B. bei der Entwicklung neuer Medikamente. Hier sind Strategien gefragt, um diese Engpässe zu beheben.
- Die Entstehung kapitalintensiver, arbeitsarmer Wirtschaftssysteme: Die Belege deuten darauf hin, dass KI zunehmend eigenständig Unternehmen betreiben kann.
Das bedeutet, dass ein Teil der Wirtschaft von neuen, kapital- oder arbeitsintensiven Firmen übernommen werden könnte, die z.B. durch große Rechenzentren oder hohe Investitionen in KI-Services geprägt sind. Diese Firmen könnten weniger auf menschliche Arbeitskraft angewiesen sein, weil KI ihre Margen erhöht.
In der Folge entsteht eine „Maschinenwirtschaft“ innerhalb der „menschlichen Wirtschaft“, die sich im Laufe der Zeit selbstständig reorganisiert, mit neuen Handelsmustern und Verteilungsfragen. Es könnten sogar vollständig autonome KI-Unternehmen entstehen, was die genannten Probleme verschärft und neue Governance-Herausforderungen schafft.
Schwarzes Loch
Auf Basis dieser Analyse schätzt der Autor, dass die Wahrscheinlichkeit, bis Ende 2028 eine automatisierte KI-Forschung zu sehen, bei etwa 60 % liegt. Warum nicht schon 2027?
Weil er glaubt, dass KI-Forschung noch Kreativität und kritische Einsichten braucht, um wirklich voranzukommen. Bisher hat kein System diese transformative Fähigkeit in bedeutendem Maße gezeigt (obwohl einige Ergebnisse in der mathematischen Forschung vielversprechend sind).
Wenn er eine Wahrscheinlichkeit für 2027 angeben müsste, würde er 30 % nennen.
Falls bis Ende 2028 keine solche Entwicklung eintritt, könnten fundamentale Schwächen der aktuellen Paradigmen sichtbar werden, die menschliche Innovation erfordern, um weiterzukommen.
Originallink
Hier klicken, um mehr über die Stellenangebote bei律动BlockBeats zu erfahren
Willkommen im offiziellen Telegram-Community von律动BlockBeats:
Telegram Abonnenten: https://t.me/theblockbeats
Telegram Diskussionsgruppe: https://t.me/BlockBeats_App
Twitter Offiziell: https://twitter.com/BlockBeatsAsia