تحديات منظومة بيانات البلوكشين الحديثة
تواجه الشركات الناشئة المتخصصة في فهرسة بيانات البلوكشين الحديثة عدداً من التحديات، من بينها:
- ضخامة حجم البيانات. مع تزايد بيانات البلوكشين، يجب أن يتوسع الفهرس لمواكبة الحمل المتزايد وتوفير وصول فعال للبيانات، ما يؤدي بدوره إلى زيادة تكاليف التخزين، وبطء احتساب المؤشرات، وزيادة الضغط على خادم قواعد البيانات.
- تعقيد خطوط معالجة البيانات. تتسم تقنية البلوكشين بالتعقيد، ويتطلب بناء فهرس بيانات شامل وموثوق فهماً عميقاً لهياكل البيانات والخوارزميات الأساسية، ويزداد هذا التعقيد مع تنوع تطبيقات البلوكشين. فعلى سبيل المثال، غالباً ما تُنشأ رموز NFTs في شبكة Ethereum عبر العقود الذكية وفق معيارَي ERC721 وERC1155، بينما تُنفذ على Polkadot عادة ضمن بيئة تشغيل البلوكشين نفسها. في النهاية، يجب التعامل مع كل هذه الحالات كـNFTs وتخزينها على هذا الأساس.
- قدرات التكامل. لتقديم أقصى قيمة للمستخدمين، قد تحتاج حلول فهرسة بيانات البلوكشين إلى دمج الفهرس مع أنظمة أخرى مثل منصات التحليل أو واجهات برمجة التطبيقات (APIs)، ما يمثل تحدياً كبيراً ويتطلب جهداً في تصميم البنية التقنية.
ومع انتشار استخدام تقنية البلوكشين، ارتفع حجم البيانات المخزنة على الشبكة نتيجة زيادة المستخدمين، حيث تضيف كل معاملة بيانات جديدة. كما تطورت استخدامات البلوكشين من تطبيقات نقل الأموال البسيطة مثل Bitcoin إلى تطبيقات أكثر تعقيداً تتضمن تنفيذ منطق الأعمال ضمن العقود الذكية، وهذه الأخيرة تولد كميات ضخمة من البيانات، ما زاد من تعقيد وحجم البلوكشين مع مرور الوقت.
في هذا المقال، نستعرض تطور بنية تقنية Footprint Analytics كمثال لدراسة كيفية معالجة منظومة Iceberg-Trino لتحديات بيانات البلوكشين.
قامت Footprint Analytics بفهرسة بيانات 22 بلوكشين عامة، و17 سوق NFT، و1900 مشروع GameFi، وأكثر من 100,000 مجموعة NFT ضمن طبقة تجريد بيانات دلالية، لتقدم بذلك أكثر حلول مستودعات بيانات البلوكشين شمولاً على مستوى العالم.
أما بيانات البلوكشين، التي تتجاوز 20 مليار سجل معاملات مالية وغالباً ما يستعلم عنها محللو البيانات، فهي تختلف عن سجلات الإدخال في مستودعات البيانات التقليدية.
شهدنا ثلاث ترقيات رئيسية خلال الأشهر الماضية لتلبية متطلبات الأعمال المتزايدة:
البنية 1.0 Bigquery
في بداية Footprint Analytics، اعتمدنا على Google Bigquery كمحرك تخزين واستعلام؛ وهو منتج يتميز بسرعة كبيرة وسهولة الاستخدام ويوفر قوة حسابية ديناميكية وبنية UDF مرنة تساعدنا على إنجاز المهام بسرعة.
لكن Bigquery واجه عدة مشكلات:
- عدم ضغط البيانات، ما يرفع تكاليف التخزين، خصوصاً عند حفظ بيانات أكثر من 22 بلوكشين تابعة لـFootprint Analytics.
- محدودية التوازي: يدعم Bigquery فقط 100 استعلام متزامن، وهو غير مناسب لسيناريوهات الاستخدام الكثيف لدى Footprint Analytics.
- الارتباط بمنتج Google Bigquery المغلق المصدر.
لذلك قررنا البحث عن بنى بديلة.
البنية 2.0 OLAP
اهتممنا ببعض منتجات OLAP الرائجة، حيث تكمن أبرز ميزاتها في سرعة الاستعلام العالية ودعمها لآلاف الاستعلامات المتزامنة.
اخترنا قاعدة بيانات Doris كأحد أفضل محركات OLAP لتجربتها، وحققت أداءً جيداً، لكننا واجهنا لاحقاً بعض التحديات:
- أنواع بيانات مثل Array أو JSON لم تكن مدعومة بعد (نوفمبر 2022)، وهذه الأنواع شائعة في بعض البلوكشينات مثل حقل topic في سجلات evm، ما أثر على قدرتنا في حساب العديد من مؤشرات الأعمال.
- دعم محدود لـDBT وعمليات الدمج، وهي متطلبات أساسية لمهندسي البيانات في سيناريوهات ETL/ELT لتحديث البيانات المفهرسة.
لذا لم نتمكن من استخدام Doris لكامل خط أنابيب البيانات في الإنتاج، بل استخدمناه كمحرك استعلام OLAP لحل جزء من المشكلة، مع توفير استعلامات سريعة وعالية التوازي.
لكن لم نستطع استبدال Bigquery بـDoris، واضطررنا لمزامنة البيانات دورياً من Bigquery إلى Doris، ما أدى إلى تراكم عمليات التحديث عند انشغال محرك OLAP بخدمة استعلامات المستخدمين، وبالتالي تباطأت عمليات الكتابة والمزامنة وأحياناً أصبحت مستحيلة.
أدركنا أن OLAP يحل بعض المشكلات، لكنه لا يمثل الحل الشامل لمنظومة Footprint Analytics، خاصة في خط معالجة البيانات، فمشكلتنا أعمق وأكثر تعقيداً، وOLAP كمحرك استعلام فقط لم يكن كافياً.
البنية 3.0 Iceberg + Trino
مع إطلاق Footprint Analytics 3.0، أعدنا تصميم البنية التحتية بالكامل، وقمنا بفصل التخزين والحوسبة والاستعلام إلى ثلاثة مكونات مستقلة، مستفيدين من دروس البنيتين السابقتين وتجارب مشاريع البيانات الضخمة الناجحة مثل Uber وNetflix وDatabricks.
مقدمة حول بحيرة البيانات
اتجهنا أولاً نحو بحيرة البيانات، وهي نوع جديد من التخزين يدعم البيانات المهيكلة وغير المهيكلة، وتعد مثالية لبيانات البلوكشين التي تتنوع بين البيانات الخام غير المهيكلة والبيانات المجردة المنظمة التي تشتهر بها Footprint Analytics. توقعنا أن تحل بحيرة البيانات مشكلة التخزين، وأن تدعم محركات الحوسبة الرئيسية مثل Spark وFlink لتسهيل التكامل مع مختلف محركات المعالجة مع تطور Footprint Analytics.
يتكامل Iceberg بكفاءة مع Spark وFlink وTrino وغيرها من محركات الحوسبة، ما يتيح لنا اختيار المحرك الأنسب لكل مؤشر. على سبيل المثال:
- Spark للعمليات الحسابية المعقدة.
- Flink للحوسبة الفورية.
- Trino لمهام ETL البسيطة عبر SQL.
محرك الاستعلام
بعد حل Iceberg لمشكلات التخزين والحوسبة، كان علينا اختيار محرك الاستعلام الأنسب. لم تكن الخيارات كثيرة، ودرسنا البدائل التالية:
- Trino: محرك استعلام SQL
- Presto: محرك استعلام SQL
- Kyuubi: Serverless Spark SQL
كان الأهم أن يكون محرك الاستعلام متوافقاً مع البنية الحالية لدينا:
- دعم Bigquery كمصدر بيانات
- دعم DBT لإنتاج العديد من المؤشرات
- دعم أداة BI metabase
بناءً على ذلك اخترنا Trino، الذي يوفر دعماً ممتازاً لـIceberg، كما أن فريق الدعم استجاب بسرعة فائقة حيث تم إصلاح خطأ خلال يوم واحد وإصداره في النسخة الأحدث خلال أسبوع. كان هذا الخيار الأمثل لفريق Footprint الذي يحتاج لاستجابة تنفيذية عالية.
اختبار الأداء
بعد تحديد المسار، أجرينا اختبار أداء لمزيج Trino + Iceberg، وكانت النتائج مذهلة من حيث سرعة الاستعلامات.
وبينما ظل Presto + Hive لسنوات أضعف الخيارات في مجال OLAP، فقد فاق مزيج Trino + Iceberg جميع التوقعات.
وفيما يلي نتائج اختباراتنا:
الحالة 1: دمج مجموعتي بيانات ضخمتين
جدول بحجم 800 GB (table1) يدمج مع جدول آخر بحجم 50 GB (table2) ويجري حسابات أعمال معقدة
الحالة 2: استخدام جدول كبير لاستعلام مميز
اختبار SQL: select distinct(address) from table group by day

مزيج Trino+Iceberg أسرع بثلاثة أضعاف تقريباً من Doris بنفس التكوين.
ميزة إضافية أخرى هي أن Iceberg يدعم صيغ بيانات مثل Parquet وORC، ما يسمح بضغط البيانات وتخزينها بكفاءة، حيث يشغل تخزين الجداول في Iceberg فقط حوالي خمس المساحة المستخدمة في مستودعات البيانات الأخرى. يوضح الجدول التالي حجم التخزين لنفس الجدول في قواعد البيانات الثلاث:

ملاحظة: النتائج أعلاه أمثلة عملية من الإنتاج الفعلي وتُعرض للمرجعية فقط.
・أثر الترقية
منحتنا تقارير الأداء ثقة كافية، واستغرق فريقنا نحو شهرين لإتمام الترحيل، وهذه صورة توضح البنية بعد الترقية.
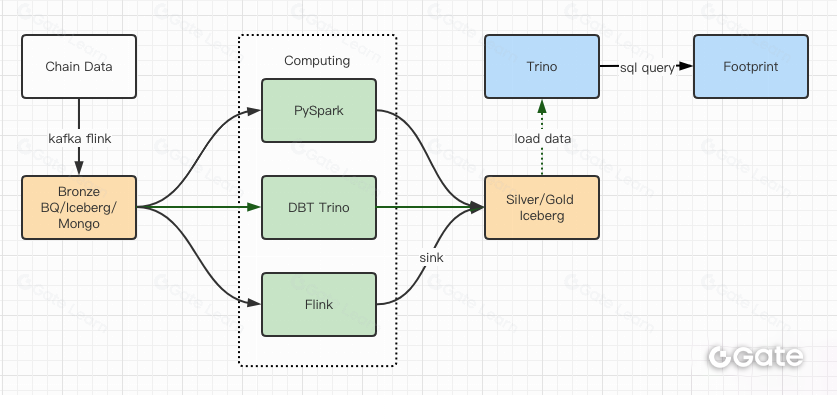
- محركات حوسبة متعددة تلبي جميع احتياجاتنا.
- يدعم Trino أداة DBT، ويمكنه الاستعلام مباشرة من Iceberg، ما ألغى الحاجة لمزامنة البيانات.
- أداء Trino + Iceberg المتميز يتيح لنا إتاحة جميع بيانات Bronze (البيانات الخام) للمستخدمين.
الخلاصة
منذ انطلاقها في أغسطس 2021، أنجز فريق Footprint Analytics ثلاث ترقيات معمارية خلال أقل من عام ونصف، مدفوعاً بالعزيمة لتقديم أفضل تقنيات قواعد البيانات لمستخدمي الكريبتو وتنفيذ بنية تحتية متطورة.
وقد أدت ترقية Footprint Analytics 3.0 إلى تجربة جديدة للمستخدمين، حيث أصبح بإمكانهم من مختلف الخلفيات الوصول إلى رؤى وتحليلات أكثر تنوعاً:
- بفضل أداة Metabase BI، أصبح بإمكان المحللين الوصول إلى بيانات البلوكشين المفككة، والاستكشاف بحرية تامة باستخدام أدوات متعددة (بدون كود أو تقني)، واستعلام سجل البيانات بالكامل، وتحليل مجموعات البيانات المتقاطعة للحصول على رؤى فورية.
- دمج بيانات البلوكشين وخارج البلوكشين للتحليل عبر web2 وweb3.
- من خلال بناء واستعلام المؤشرات على طبقة تجريد الأعمال في Footprint، يوفر المحللون والمطورون %80 من وقت معالجة البيانات المتكررة ويركزون على المؤشرات الجوهرية، والبحث، وتطوير الحلول.
- تجربة سلسة من منصة Footprint Web حتى استدعاءات REST API، وجميعها تعتمد على SQL.
- تنبيهات فورية وإشعارات قابلة للتنفيذ حول الإشارات الأساسية لدعم قرارات الاستثمار.






