Daniel Romero
用戶暫無簡介
Daniel Romero
市場現在給我們一些機會
好奇想聽聽大家的想法
大家都在買什麼?
查看原文好奇想聽聽大家的想法
大家都在買什麼?
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
$AMD 威尼斯超越$NVDA Vera 3倍
EPYC 威尼斯可能是新一代代理型 CPU 推動的領頭羊
AMD 比較 NVIDIA Vera、Intel Xeon 6980P、AMD EPYC 9965 Turin 以及未來的 AMD EPYC 威尼斯,在一個模擬的 100 kW 機架電力預算下
AMD 表示 EPYC 9965 的機架級吞吐量是 NVIDIA Vera 的 2.37 倍,約為 Intel Xeon 6980P 的 1.6 倍
AMD 表示未來的 EPYC 威尼斯將將優勢擴展到 NVIDIA Vera 的 3.30 倍
這個比較專注於代理型 AI 的 CPU 密集型基礎設施,包括協調、數據庫、網絡服務、API、緩存、中間件和控制平面服務
$AMD 認為機架級性能比單芯片基準更重要,因為數據中心受電力、冷卻、樓層空間和可部署基礎設施的限制
AMD 也表示,目前的 EPYC Turin 部署每個機架可以支持超過 27,000 個 CPU 核心,而未來的 EPYC 威尼斯可能超過 36,000 核心
然而,這些都是 AMD 模擬的估算,並非完全獨立的實際機架基準
這些結果應被視為方向性比較,而非直接測量的機架基準
查看原文EPYC 威尼斯可能是新一代代理型 CPU 推動的領頭羊
AMD 比較 NVIDIA Vera、Intel Xeon 6980P、AMD EPYC 9965 Turin 以及未來的 AMD EPYC 威尼斯,在一個模擬的 100 kW 機架電力預算下
AMD 表示 EPYC 9965 的機架級吞吐量是 NVIDIA Vera 的 2.37 倍,約為 Intel Xeon 6980P 的 1.6 倍
AMD 表示未來的 EPYC 威尼斯將將優勢擴展到 NVIDIA Vera 的 3.30 倍
這個比較專注於代理型 AI 的 CPU 密集型基礎設施,包括協調、數據庫、網絡服務、API、緩存、中間件和控制平面服務
$AMD 認為機架級性能比單芯片基準更重要,因為數據中心受電力、冷卻、樓層空間和可部署基礎設施的限制
AMD 也表示,目前的 EPYC Turin 部署每個機架可以支持超過 27,000 個 CPU 核心,而未來的 EPYC 威尼斯可能超過 36,000 核心
然而,這些都是 AMD 模擬的估算,並非完全獨立的實際機架基準
這些結果應被視為方向性比較,而非直接測量的機架基準
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
Cloudflare $NET 相信 AI 代理可能使 CPU 需求增加 20 倍
$AMD $INTC $ARM
該公司認為,如果每個工作人員都運行多個代理,使用當前的雲端模型,AI 代理可能會造成巨大的 CPU/伺服器基礎設施問題
數學計算:
美國:
⏩ 1 億知識工作者 × 1 代理 / 每 CPU 約 10 代理 = 1000 萬 CPU
全球:
⏩ 10 億知識工作者 × 10 代理 / 每 CPU 約 10 代理 = 10 億 CPU
Cloudflare 將此與目前全球每年約 3500 萬至 4500 萬的伺服器 CPU 生產量相比,暗示目前的方法可能需要約 20 倍的年度 CPU 產量
$NET 正在推廣 Agent Cloud 作為解決方案
它的運作方式如下:
1. 動態工作者取代完整容器
代理可以按需啟動,閒置時放回冷存儲,避免每個代理都運行一個繁重的常駐容器
2. 用於狀態的持久對象
代理需要記憶體/狀態來處理任務、文件、會話、進度和工具輸出。持久對象為每個代理/應用提供一個具有本地 SQLite 支持存儲的有狀態對象
3. 用於長時間運行代理的工作流程
代理可能會運行數分鐘、數小時或數天,等待批准、重試、外部事件或排程步驟。動態工作流程允許這些過程在步驟之間休眠,而不是持續消耗計算
查看原文$AMD $INTC $ARM
該公司認為,如果每個工作人員都運行多個代理,使用當前的雲端模型,AI 代理可能會造成巨大的 CPU/伺服器基礎設施問題
數學計算:
美國:
⏩ 1 億知識工作者 × 1 代理 / 每 CPU 約 10 代理 = 1000 萬 CPU
全球:
⏩ 10 億知識工作者 × 10 代理 / 每 CPU 約 10 代理 = 10 億 CPU
Cloudflare 將此與目前全球每年約 3500 萬至 4500 萬的伺服器 CPU 生產量相比,暗示目前的方法可能需要約 20 倍的年度 CPU 產量
$NET 正在推廣 Agent Cloud 作為解決方案
它的運作方式如下:
1. 動態工作者取代完整容器
代理可以按需啟動,閒置時放回冷存儲,避免每個代理都運行一個繁重的常駐容器
2. 用於狀態的持久對象
代理需要記憶體/狀態來處理任務、文件、會話、進度和工具輸出。持久對象為每個代理/應用提供一個具有本地 SQLite 支持存儲的有狀態對象
3. 用於長時間運行代理的工作流程
代理可能會運行數分鐘、數小時或數天,等待批准、重試、外部事件或排程步驟。動態工作流程允許這些過程在步驟之間休眠,而不是持續消耗計算
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
$ORCL 需要籌集更多資金以資助人工智能資本支出
“為了支持我們的資本投資計劃,我們預計在2027財年籌集約400億美元的債務和股權。這包括我們已宣布的20億美元市場發行的股權。”
查看原文“為了支持我們的資本投資計劃,我們預計在2027財年籌集約400億美元的債務和股權。這包括我們已宣布的20億美元市場發行的股權。”

- 打賞
- 按讚
- 回覆
- 轉發
- 分享
人工智慧應用於基因組學正升溫
三星電子投資1.75億美元於美國聖地牙哥的基因公司Element Biosciences
該投資使三星成為該公司的最大股東
Element生產基因測序系統,如AVITI和VITARI,並即將推出AVITI Dx和AVITI24產品。這些工具解碼DNA和RNA,應用於醫學研究、疾病檢測、藥物開發和診斷等領域
三星希望將Element的DNA測序和多組學技術與其在人工智慧、醫療設備和數字健康方面的能力相結合。目標是追求個人化醫療和下一代基因診斷的機會
查看原文三星電子投資1.75億美元於美國聖地牙哥的基因公司Element Biosciences
該投資使三星成為該公司的最大股東
Element生產基因測序系統,如AVITI和VITARI,並即將推出AVITI Dx和AVITI24產品。這些工具解碼DNA和RNA,應用於醫學研究、疾病檢測、藥物開發和診斷等領域
三星希望將Element的DNA測序和多組學技術與其在人工智慧、醫療設備和數字健康方面的能力相結合。目標是追求個人化醫療和下一代基因診斷的機會
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
$SMCI 總是想方設法讓投資者失望,即使所有條件都對它有利
查看原文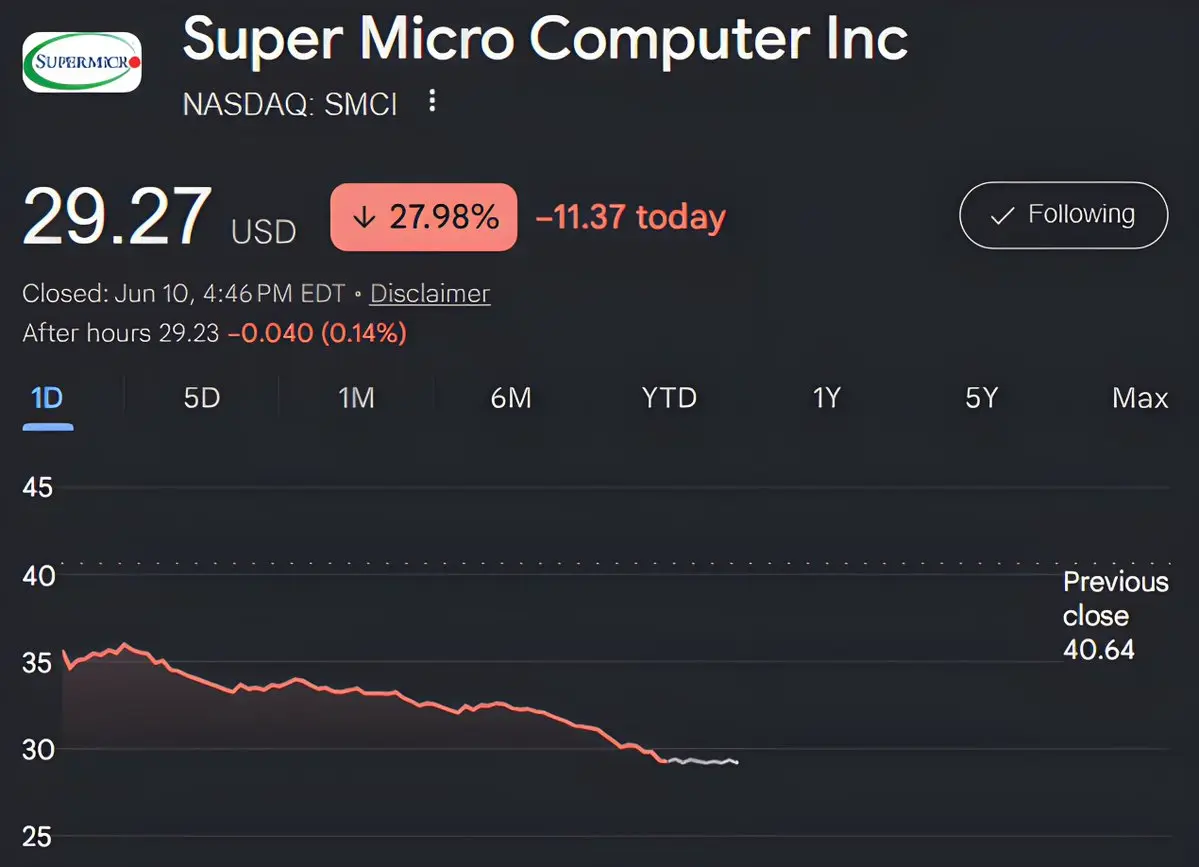
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
老實說,我相信市場在這裡喘口氣是最健康的事情
我們的大型股因為 Jensen 說了些好話而上漲了 60%,而小型股每週翻倍,因為有人在 X 上提到它們
查看原文我們的大型股因為 Jensen 說了些好話而上漲了 60%,而小型股每週翻倍,因為有人在 X 上提到它們
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
這是真的嗎?$NVDA CPO沒有延遲嗎?
我現在不知道該如何看待SemiAnalysis的報告
SemiAnalysis有優秀的專業人士,但他們有時候可能過於宣傳或誇大事情,只為了製造“突發新聞”
查看原文我現在不知道該如何看待SemiAnalysis的報告
SemiAnalysis有優秀的專業人士,但他們有時候可能過於宣傳或誇大事情,只為了製造“突發新聞”
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
CPO新聞並不是那麼重要
如果CPO延遲,部分短期需求可以由插拔式、LPO和NPO風格的架構來吸收
大多數暴露於CPO的公司也都暴露於光學收發器,實際上可能會從CPO採用的延遲中受益。因此,就股票而言,這基本上並不那麼重要
例如,像Coherent、Lumentum、Fabrinet、Broadcom、Marvell等公司可能會隨著時間受益於CPO,但它們也極度依賴當前的AI網路建設
查看原文如果CPO延遲,部分短期需求可以由插拔式、LPO和NPO風格的架構來吸收
大多數暴露於CPO的公司也都暴露於光學收發器,實際上可能會從CPO採用的延遲中受益。因此,就股票而言,這基本上並不那麼重要
例如,像Coherent、Lumentum、Fabrinet、Broadcom、Marvell等公司可能會隨著時間受益於CPO,但它們也極度依賴當前的AI網路建設

- 打賞
- 按讚
- 回覆
- 轉發
- 分享
剛開始在半導體供應鏈的新職位
⏩ <$1.5B 市值
⏩ 65% 市場份額
⏩ 高端產品的壟斷地位
⏩ 客戶包括:三星、SK海力士、美光、日月光、安靠、台積電…
⏩ 即將受益於未來十年的巨大順風
⏩ 正面暴露於HBM、面板級封裝和玻璃基板
⏩ 財務狀況良好,現金比負債多50%
查看原文⏩ <$1.5B 市值
⏩ 65% 市場份額
⏩ 高端產品的壟斷地位
⏩ 客戶包括:三星、SK海力士、美光、日月光、安靠、台積電…
⏩ 即將受益於未來十年的巨大順風
⏩ 正面暴露於HBM、面板級封裝和玻璃基板
⏩ 財務狀況良好,現金比負債多50%
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
$AMD 提前兩年達成財務目標
Bernstein的Stacy Rasgon,之前對$AMD持懷疑態度,現在預計AMD到2028年每股盈餘約達到20美元,這原本是AMD的2030年目標
主要原因不是GPU,而是伺服器CPU,AMD在伺服器CPU市場持續搶占份額,同時伺服器CPU的市場規模已大幅擴展
重點如下:
AMD的資料中心部門現在是主要的成長引擎,營收強勁成長,伺服器CPU市占率擴大,Lisa Su將長期伺服器CPU市場機會從$60B 提升到$120B
GPU的故事較為複雜。Rasgon認為AMD正從一個邊緣的AI GPU玩家轉變為更具相關性的玩家,可能達到10–11%的市佔率,但NVIDIA仍透過CUDA占據主導地位
結論是,僅靠AMD的CPU業務已足以支撐更大的盈利空間,而GPU則是額外的上行空間,前提是AMD能縮小與NVIDIA在軟體和生態系統上的差距
查看原文Bernstein的Stacy Rasgon,之前對$AMD持懷疑態度,現在預計AMD到2028年每股盈餘約達到20美元,這原本是AMD的2030年目標
主要原因不是GPU,而是伺服器CPU,AMD在伺服器CPU市場持續搶占份額,同時伺服器CPU的市場規模已大幅擴展
重點如下:
AMD的資料中心部門現在是主要的成長引擎,營收強勁成長,伺服器CPU市占率擴大,Lisa Su將長期伺服器CPU市場機會從$60B 提升到$120B
GPU的故事較為複雜。Rasgon認為AMD正從一個邊緣的AI GPU玩家轉變為更具相關性的玩家,可能達到10–11%的市佔率,但NVIDIA仍透過CUDA占據主導地位
結論是,僅靠AMD的CPU業務已足以支撐更大的盈利空間,而GPU則是額外的上行空間,前提是AMD能縮小與NVIDIA在軟體和生態系統上的差距

- 打賞
- 按讚
- 回覆
- 轉發
- 分享
伯恩斯坦報告記憶體價格出現大幅加速,DRAM 每位元平均售價(ASP)同比上升 211%,NAND 每位元 ASP 同比上升 282%
是的,按位元出貨量較上月疲軟,DRAM 下降 16.5%,NAND 下降 20.9%
儘管出貨位元大幅下降,DRAM 銷售額僅較上月下降 3.7%,因為 ASP 幾乎完全抵消了出貨量的疲軟
是的,按位元出貨量較上月疲軟,DRAM 下降 16.5%,NAND 下降 20.9%
儘管出貨位元大幅下降,DRAM 銷售額僅較上月下降 3.7%,因為 ASP 幾乎完全抵消了出貨量的疲軟
DRAM-3.40%
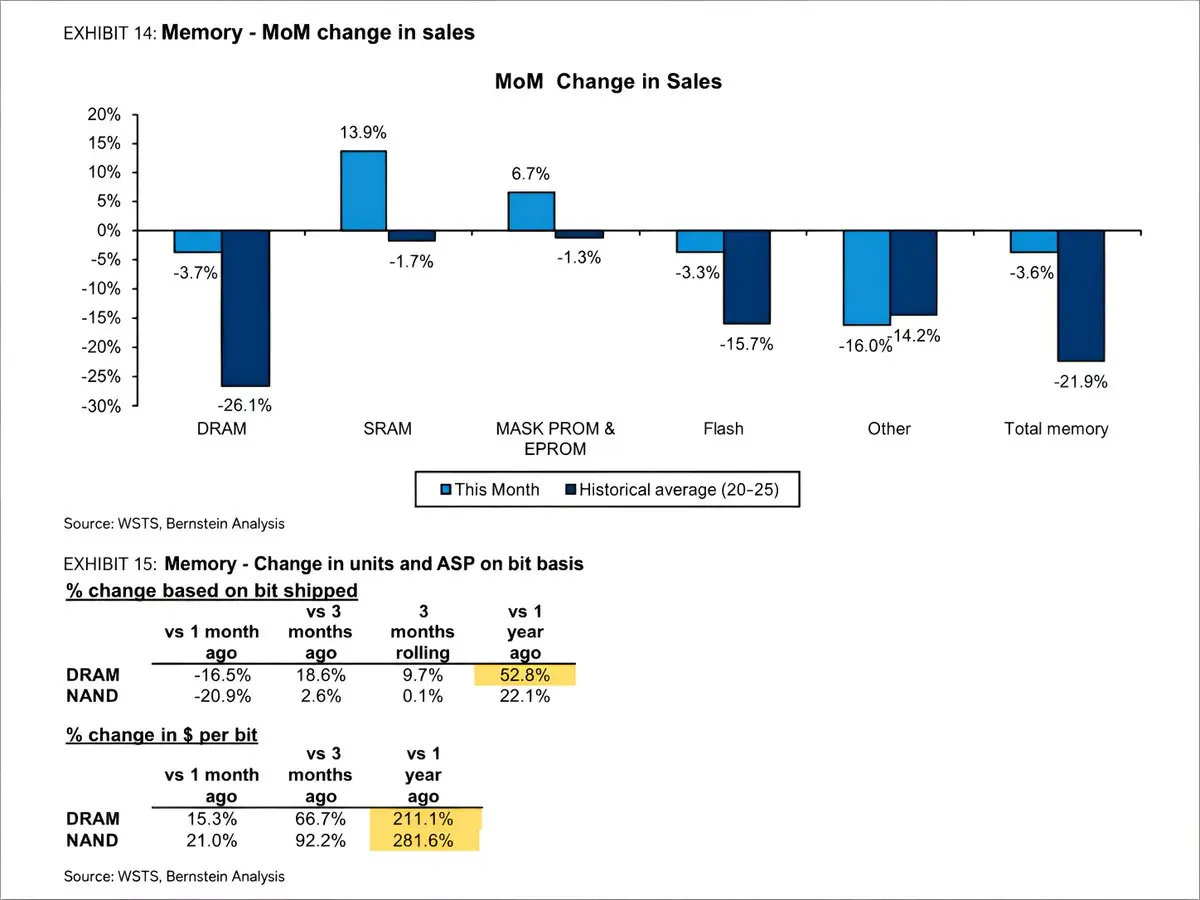
- 打賞
- 1
- 回覆
- 轉發
- 分享
伯恩斯坦報告記憶體價格出現大幅加速,DRAM 每位元平均售價(ASP)同比上升 211%,NAND 每位元 ASP 上升 282%
是的,按月出貨量較弱,DRAM 下降 16.5%,NAND 下降 20.9%
儘管出貨位元數大幅下降,DRAM 銷售額僅較上月下降 3.7%,因為 ASP 幾乎完全抵消了出貨量的疲軟
是的,按月出貨量較弱,DRAM 下降 16.5%,NAND 下降 20.9%
儘管出貨位元數大幅下降,DRAM 銷售額僅較上月下降 3.7%,因為 ASP 幾乎完全抵消了出貨量的疲軟
DRAM-3.40%
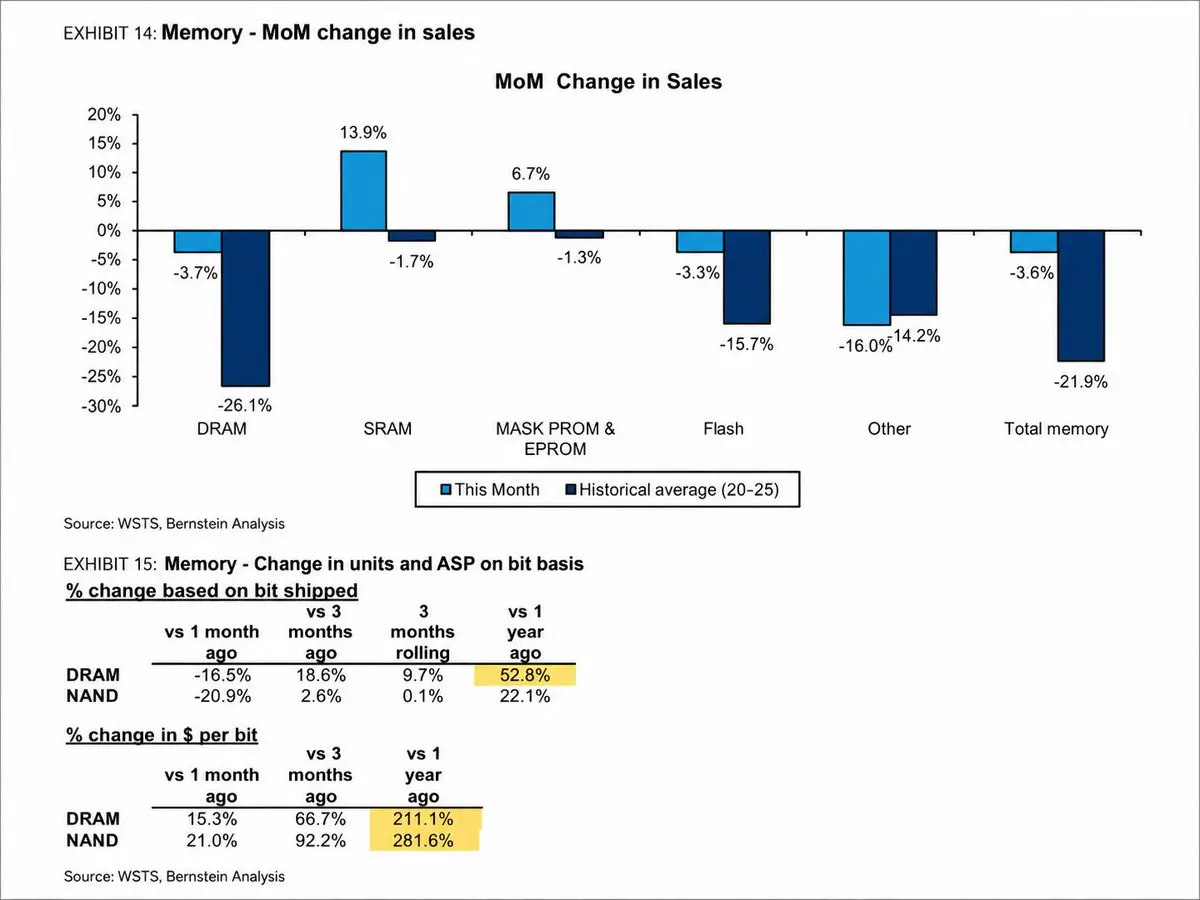
- 打賞
- 1
- 回覆
- 轉發
- 分享
這是一個微妙的轉變,但在過去的一年裡,OpenAI 已經失去了許多光環
我會說他們不再被視為第一的人工智慧實驗室,而 Altman 說的話似乎不再具有同樣的分量
他們剛剛宣布了首次公開募股,而 X 幾乎沒有在意
查看原文我會說他們不再被視為第一的人工智慧實驗室,而 Altman 說的話似乎不再具有同樣的分量
他們剛剛宣布了首次公開募股,而 X 幾乎沒有在意

- 打賞
- 1
- 回覆
- 轉發
- 分享
$NBIS 被美銀設定了280美元的目標價
估值基於2027年銷售額的8.5倍倍數
關鍵引用:
「該公司指出,通常每個GPU有3-4個客戶在競爭,我們認為這有助於提升定價杠杆和在選擇客戶時的選擇權」
查看原文估值基於2027年銷售額的8.5倍倍數
關鍵引用:
「該公司指出,通常每個GPU有3-4個客戶在競爭,我們認為這有助於提升定價杠杆和在選擇客戶時的選擇權」
- 打賞
- 1
- 回覆
- 轉發
- 分享
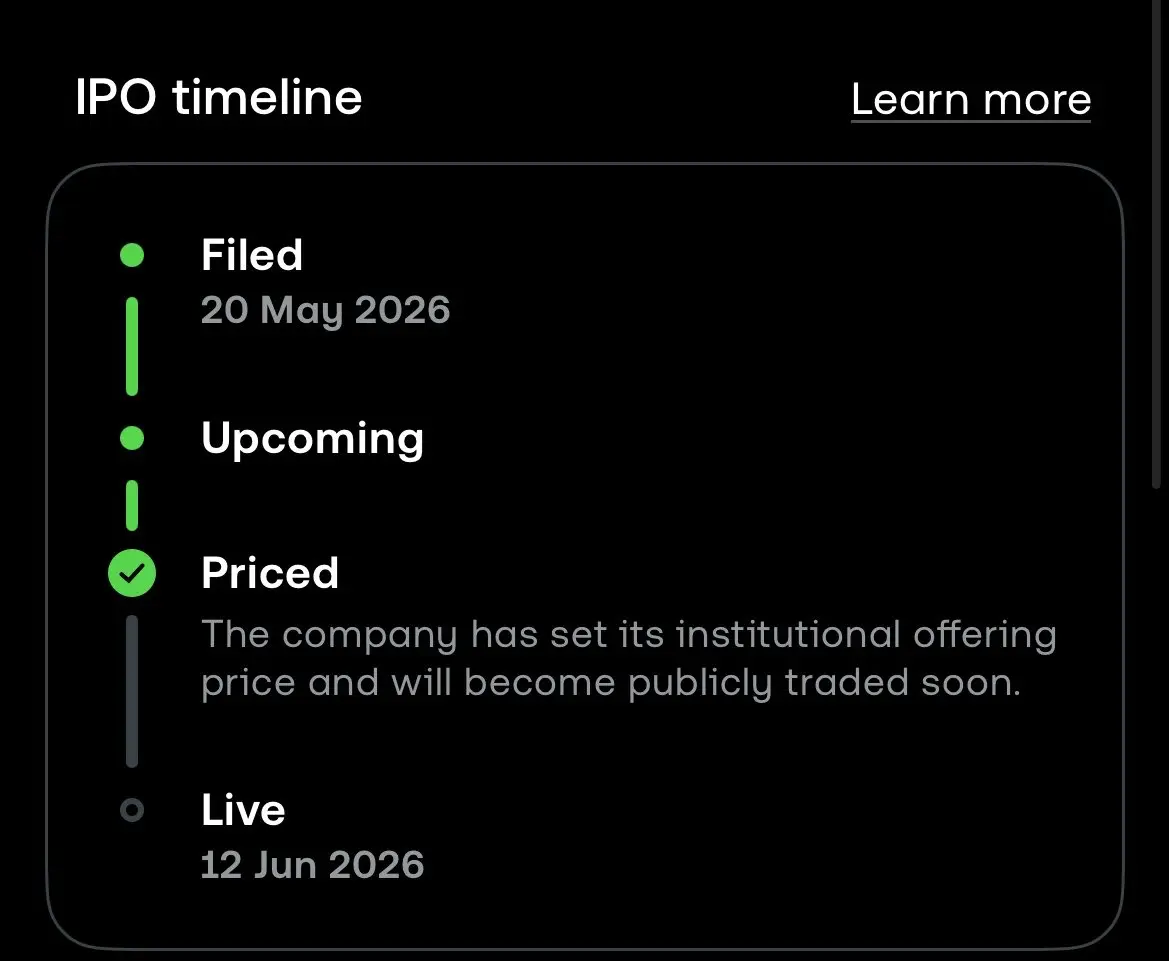
Trading 212 現在提供 $SPCX IPO
1.75兆美元估值
我看不出你如何在那個價格上獲得回報
它應該是 $1T max
在那個估值下,它可能達到 $GOOG 的市值,而那仍然只是 150% 的回報
而且即使計算 Google 和 Anthropic 的交易,它的市銷比也將達到 90 倍
我認為沒有上行空間
查看原文1.75兆美元估值
我看不出你如何在那個價格上獲得回報
它應該是 $1T max
在那個估值下,它可能達到 $GOOG 的市值,而那仍然只是 150% 的回報
而且即使計算 Google 和 Anthropic 的交易,它的市銷比也將達到 90 倍
我認為沒有上行空間
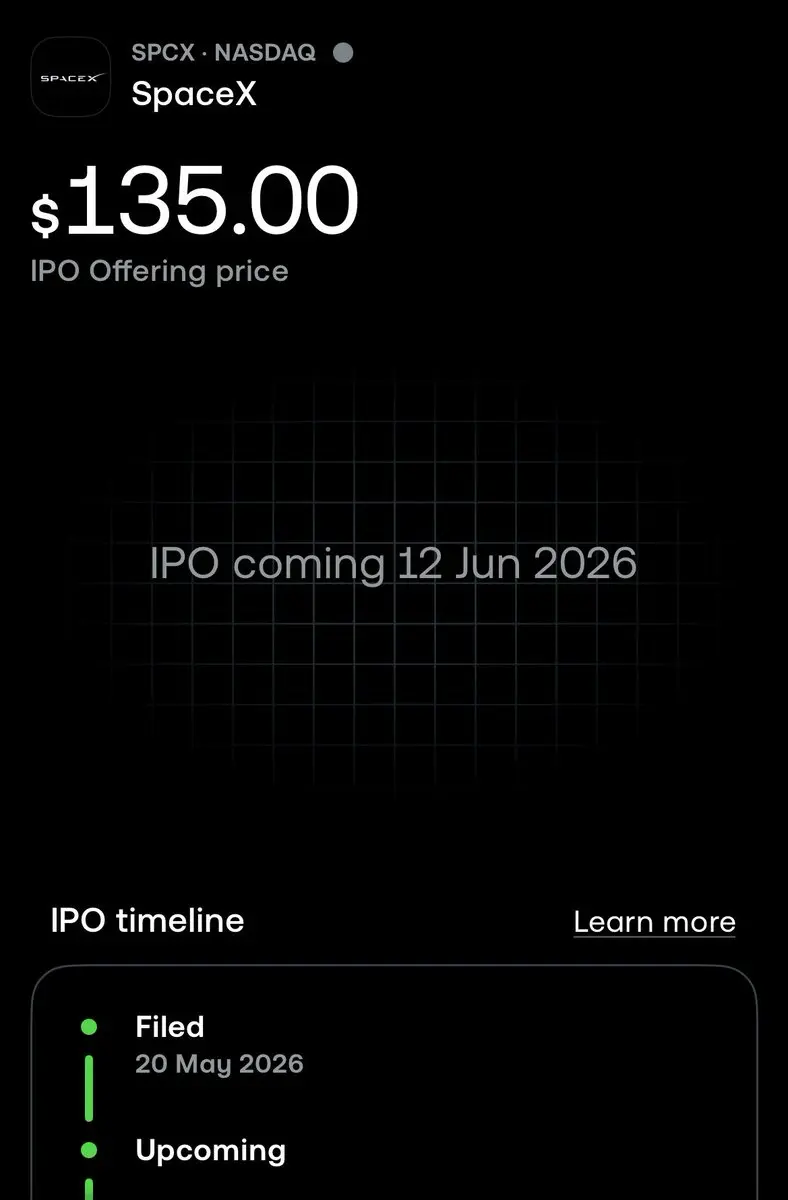
- 打賞
- 4
- 回覆
- 轉發
- 分享
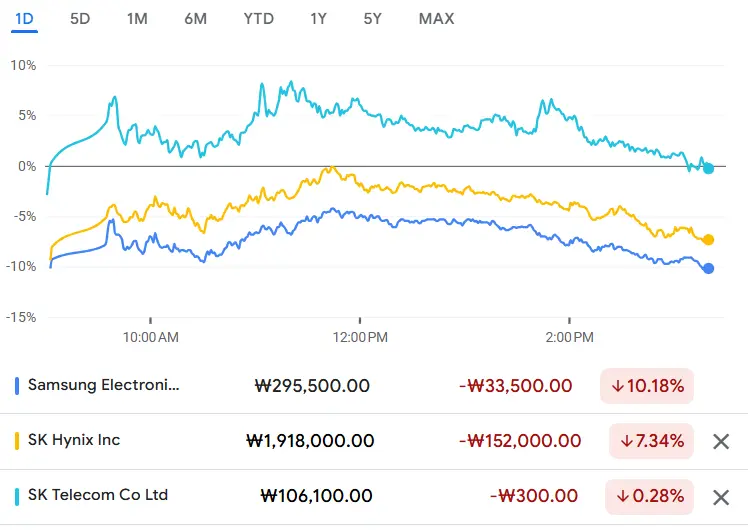
韓國股票今天呈現不錯的折扣
$SKM 展現出一些強勢
查看原文$SKM 展現出一些強勢
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
這個記憶體週期將持續讓投資者感到驚喜
伯恩斯坦現在預計,HBM4 的價格將從大約每GB 16.6美元上升到2027年的每GB 37美元,屆時 Vera Rubin 大量出貨
這意味著比目前的 HBM4 價格增加超過兩倍
$MU $5930 $000660
查看原文伯恩斯坦現在預計,HBM4 的價格將從大約每GB 16.6美元上升到2027年的每GB 37美元,屆時 Vera Rubin 大量出貨
這意味著比目前的 HBM4 價格增加超過兩倍
$MU $5930 $000660
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
TD Cowen 將 $AMD 的目標價從 500 美元上調至 600 美元,並在與管理層會面後維持買入評級
主要點是 AMD 的 AI 機會看起來比之前更強。管理層認為其 $120B AI 的市場規模可能偏保守,因為代理 AI 增加了對高效能 CPU、GPU 和低延遲系統的需求
TD Cowen 認為 AMD 正成為 NVIDIA 在 AI 基礎設施方面的主要商業替代方案,這得益於其 CPU 優勢、AI 加速器路線圖以及更廣泛的平台工作
查看原文主要點是 AMD 的 AI 機會看起來比之前更強。管理層認為其 $120B AI 的市場規模可能偏保守,因為代理 AI 增加了對高效能 CPU、GPU 和低延遲系統的需求
TD Cowen 認為 AMD 正成為 NVIDIA 在 AI 基礎設施方面的主要商業替代方案,這得益於其 CPU 優勢、AI 加速器路線圖以及更廣泛的平台工作

- 打賞
- 1
- 1
- 轉發
- 分享
devia:
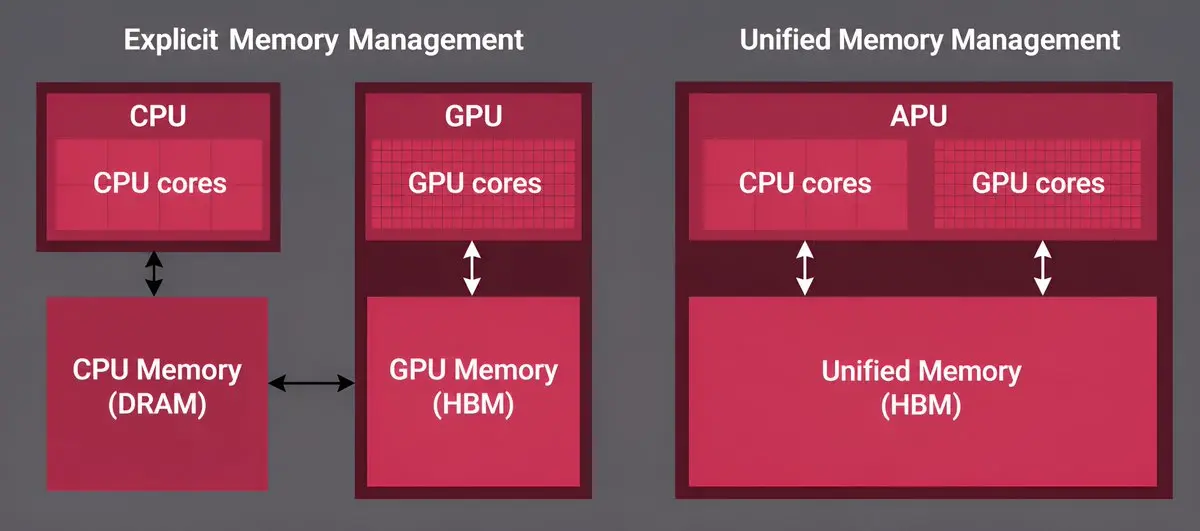
amd 也是一家不錯的公司$AMD 表示統一記憶體架構(UMA)正變得對人工智慧電腦、工作站以及未來高性能平台越來越重要
這個想法是讓 CPU、GPU 和記憶體共享一個大型記憶體池,而不是將系統記憶體與 GPU VRAM 分開。這有助於 AI 工作負載,因為大型模型需要大量可存取的記憶體
瑞芯微處理器(Ryzen CPU)和 Radeon 圖形的副總裁兼總經理 David McAfee 表示:
「有了 Strix Halo,隨著 $NVDA 進入這個領域,將會有很多焦點放在 UMA 系統上,以及辨識這些 UMA 系統能做什麼的正確架構。」
「這是一個全新的工作負載,一個我們正在解決的全新計算空間,我認為它將影響我們的產品選擇、產品路線圖和部署選項的許多方面。」
「NVIDIA 在他們的公告中所做的,是對該架構的肯定。」
「由於這些系統的統一記憶體池,代理計算的出現和運行超大模型具有非常獨特的價值。」
統一記憶體架構正迅速成為下一代計算的基礎支柱
隨著代理人工智慧推動對大規模共享記憶體池的需求,AMD 和 NVIDIA 現在都在驗證 UMA 方法
AMD 對這一方向的信心,通過 Strix Halo 和預期的 Ryzen AI MAX 400 系列,表明我們仍處於這一趨勢的初期
隨著統一系統模糊了 CPU、GPU 和記憶體之間的界線,它們可能釋放出新的性能、效率和能力
查看原文這個想法是讓 CPU、GPU 和記憶體共享一個大型記憶體池,而不是將系統記憶體與 GPU VRAM 分開。這有助於 AI 工作負載,因為大型模型需要大量可存取的記憶體
瑞芯微處理器(Ryzen CPU)和 Radeon 圖形的副總裁兼總經理 David McAfee 表示:
「有了 Strix Halo,隨著 $NVDA 進入這個領域,將會有很多焦點放在 UMA 系統上,以及辨識這些 UMA 系統能做什麼的正確架構。」
「這是一個全新的工作負載,一個我們正在解決的全新計算空間,我認為它將影響我們的產品選擇、產品路線圖和部署選項的許多方面。」
「NVIDIA 在他們的公告中所做的,是對該架構的肯定。」
「由於這些系統的統一記憶體池,代理計算的出現和運行超大模型具有非常獨特的價值。」
統一記憶體架構正迅速成為下一代計算的基礎支柱
隨著代理人工智慧推動對大規模共享記憶體池的需求,AMD 和 NVIDIA 現在都在驗證 UMA 方法
AMD 對這一方向的信心,通過 Strix Halo 和預期的 Ryzen AI MAX 400 系列,表明我們仍處於這一趨勢的初期
隨著統一系統模糊了 CPU、GPU 和記憶體之間的界線,它們可能釋放出新的性能、效率和能力
- 打賞
- 4
- 回覆
- 轉發
- 分享
熱門話題
查看更多3.87萬 熱度
31.4萬 熱度
72.58萬 熱度
69.31萬 熱度
78.65萬 熱度