Microsoft 讓 GPT 和 Claude 共同運作——而結果超越了所有現有的 AI 研究工具
Decrypt
簡述
- 微軟發布了兩種不同模式,將 GPT 與 Claude 配對,以提升 AI 研究的品質。
- Critique 讓模型協作,而 Council 則讓它們並行運作,第三位裁判模型則找出其中的差異。
- 這種雙模型工作流程能修正幻覺、薄弱引用以及其他與單一模型 AI 研究相關的問題。
今年,深度研究型 AI 一直是科技領域最熱門的軍備競賽之一。今年 12 月,Google 宣布了其在 Gemini 上的研究代理;2025 年 2 月,OpenAI 發布了自己的研究代理;xAI 隨後跟進;Perplexity 也加碼投入;而 Anthropic 的 Claude 則在去年 4 月推出其代理,並在需要詳盡、附引用的回答的專業人士中累積了忠實用戶。 每家公司都在試圖說服你:他們那個單一 AI 模型就是這個房間裡最聰明的研究者。微軟剛剛則表示:為什麼一定要選一個? 該公司在週一宣布了 Copilot 的 Researcher 工具兩項新功能——名為 Critique 和 Council——它們讓 OpenAI 的 GPT 與 Anthropic 的 Claude 以序列方式投入同一項研究任務。根據微軟針對產業基準所做的測試結果,這個結果的得分高於該測試中包含的所有系統,其中也包括頂尖 AI 公司所提供的模型。
在 M365 Copilot 中推出 Critique:一個新的多模型深度研究系統。
你可以讓多個模型一起運作,以產生最佳回應與報告。pic.twitter.com/m4RlQmCKzs
— Satya Nadella (@satyanadella) 2026 年 3 月 30 日
微軟解釋:「Critique 是一個為複雜研究任務而設計的全新多模型深度研究系統。它將生成與評估分離,並利用來自 Frontier labs 的多種模型組合,包括 Anthropic 與 OpenAI。」「一個模型負責生成階段:規劃任務、在檢索過程中反覆迭代,並產出初版草稿;而第二個模型則聚焦於審查與精煉,在最終報告產出之前扮演專家審稿者。」 下面這個基本問題,正是 Critique 被設計用來修正的:如今每一種 AI 研究工具都以相同方式運作。你提出問題,單一模型負責規劃搜尋、掃描資料來源、撰寫報告,然後把成果交回給你。這個單一模型要做所有事情,且沒有人檢查它的工作。 這可能導致一些幻覺悄悄混進來、引用出現錯誤、出現偽造或不準確的主張等等。
Critique 將這套工作流程拆成兩段。GPT 負責第一階段——它會規劃研究、抓取資料來源並撰寫初版草稿。接著 Claude 會接手並以嚴格編輯的角色介入:審查報告是否具備事實正確性、引用品質,以及答案是否真正回應了被提出的問題。只有在這次審查之後,最終報告才會送達使用者。微軟表示,這些角色未來也能反向運作——Claude 起草、GPT 進行批判,不過就目前而言,GPT 會先行。
在 DRACO 基準測試上——這是一種標準化測試,涵蓋跨越 10 個領域的 100 個複雜研究任務,包括醫學、法律與科技——配有 Critique 的 Copilot 得分為 57.4 分;而僅使用 Anthropic 的 Claude Opus 則單獨達到 42.7 分。微軟的整合系統擊敗了下一個最佳結果,差距接近 14%。
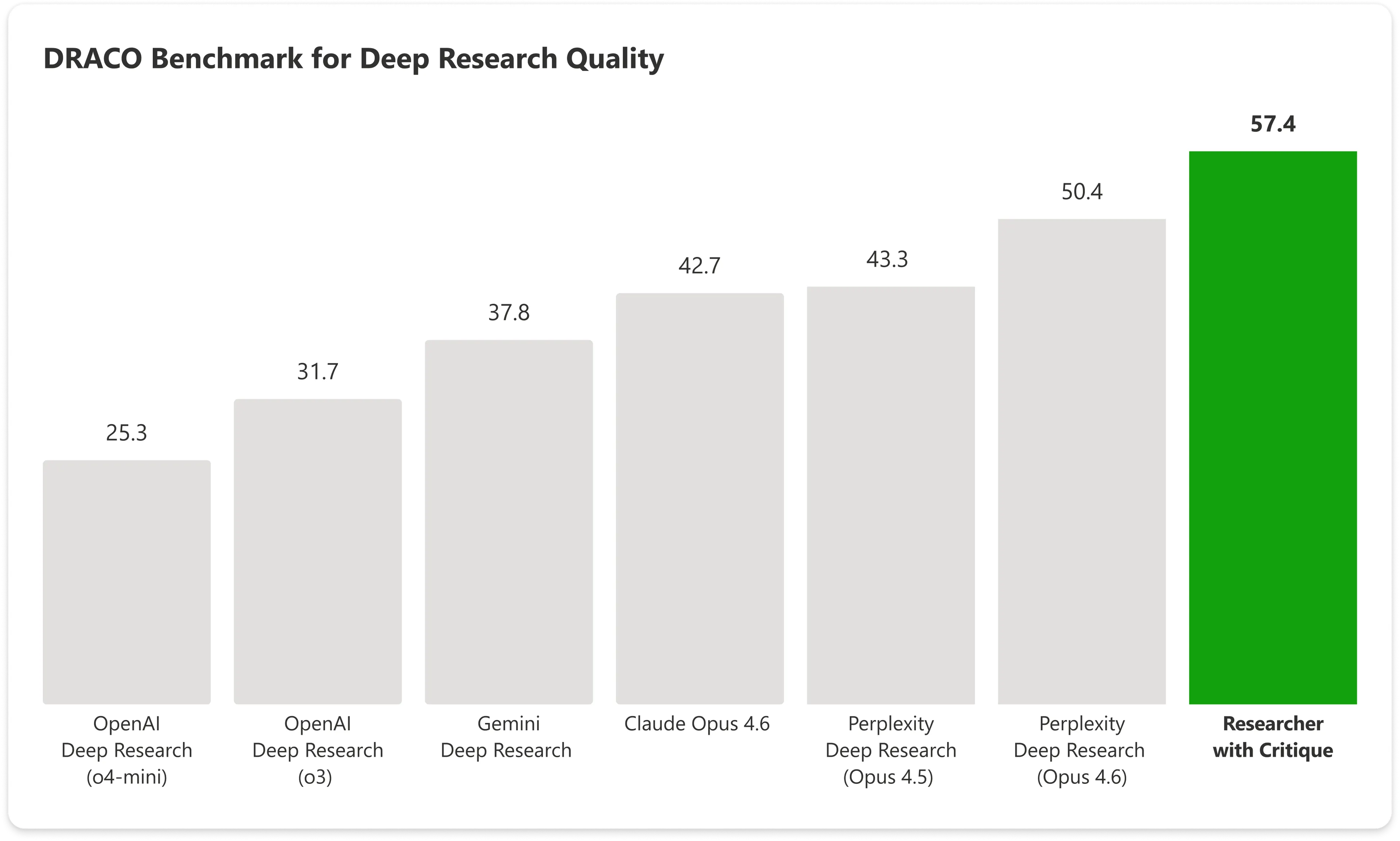
圖片:Microsoft
最大的增幅出現在分析的廣度與呈現品質上,同時事實正確性也顯示出顯著改善。
第二項功能 Council 採取了針對同一問題的不同做法。Council 不像 Critique 那樣讓一個模型審查另一個模型的工作,而是讓 GPT 與 Claude 同時 運作,並把它們完整的報告並排呈現。接著第三個「裁判」模型會讀取兩者,並撰寫摘要,說明兩個 AI 在哪些地方一致、在哪些地方出現分歧,以及各自又捕捉到了哪些對方沒注意到的獨特角度。一直以來,對 AI 研究工具進行人工比較都是使用者必須自行完成的事。
在 Critique 中,模型本質上是彼此 協作;而在 Council 中,模型則是彼此 競爭。
Critique 是 Researcher 的預設體驗;至於 Council 則需要你在選單中選擇「Model Council」,才能啟用並排模式。這兩項功能目前都提供給已加入微軟 Frontier 計畫的使用者——這是 Copilot 最新能力的早期存取管道。要使用微軟 365 Copilot 授權($30/每位使用者/月)是必需的,但使用者也需要先加入 Frontier 才能存取這些功能。
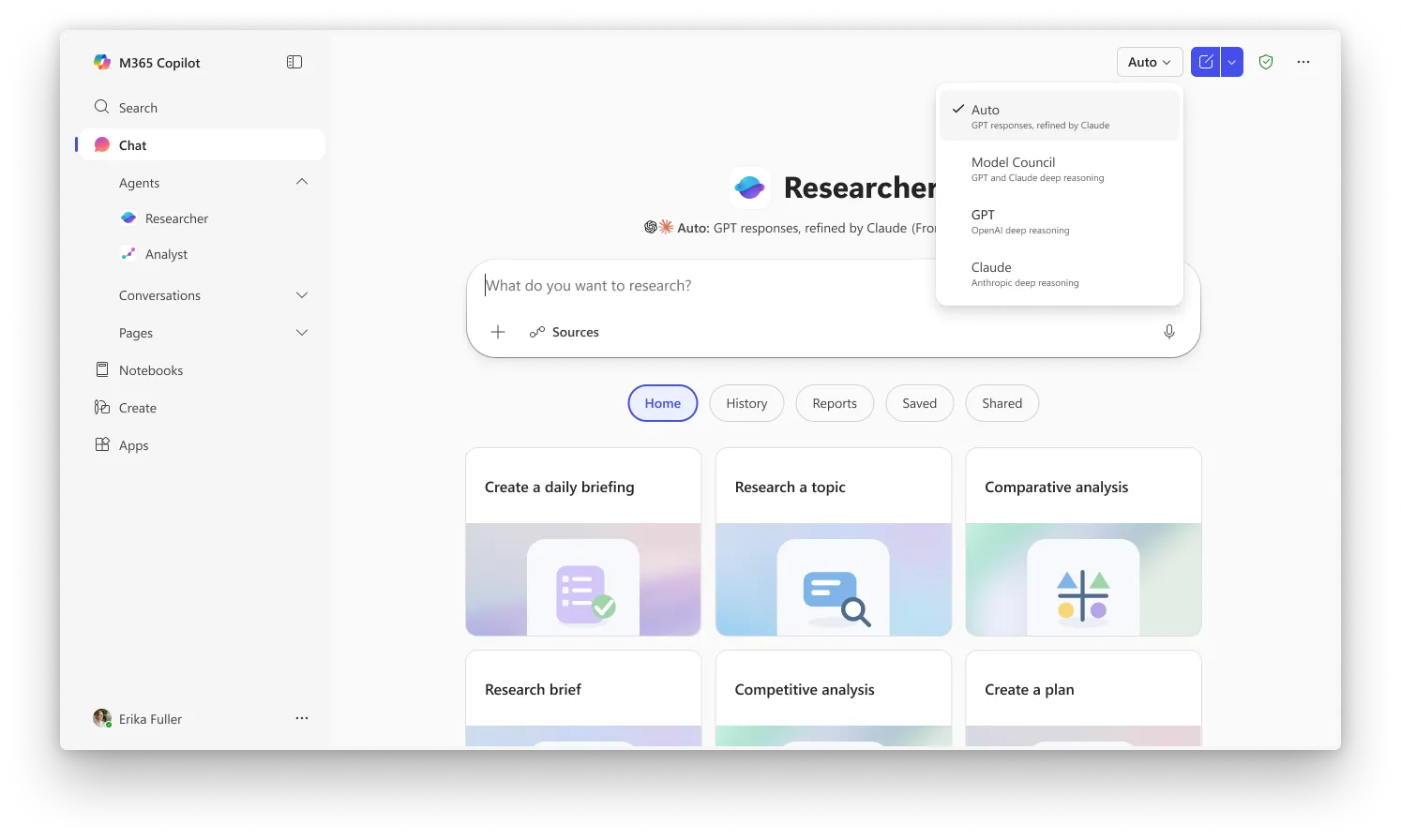
圖片:Microsoft
OpenAI 與微軟有一段多數十億美元的合作夥伴關係,但微軟的賭注在於:沒有任何單一模型能長期保持在頂端,而真正的價值在於協調層(orchestration layer)——它會將任務路由到最合適的那種模型組合。
免責聲明:本頁面資訊可能來自第三方,不代表 Gate 的觀點或意見。頁面顯示的內容僅供參考,不構成任何財務、投資或法律建議。Gate 對資訊的準確性、完整性不作保證,對因使用本資訊而產生的任何損失不承擔責任。虛擬資產投資屬高風險行為,價格波動劇烈,您可能損失全部投資本金。請充分了解相關風險,並根據自身財務狀況和風險承受能力謹慎決策。具體內容詳見聲明。
留言
0/400
暫無留言