Nhà giao dịch định lượng (Quant) gemchange_ltd đã đăng một bài viết dài trên X, liệt kê toàn bộ lộ trình học tập của anh ấy: “Nếu bắt đầu lại từ đầu, tôi sẽ học theo thứ tự nào” — từ lý thuyết xác suất đến vi tích phân ngẫu nhiên, năm cấp độ toán học, chỉ trong 18 tháng có thể từ người không biết gì trở thành người thực sự hiểu về giao dịch định lượng. Bài viết này dựa trên bài đăng nổi bật của anh ấy trên X mang tên “How I’d Become a Quant If I Had to Start Over Tomorrow”, được Flip dịch và biên tập lại.
(Tóm tắt trước đó: Không dựa vào hoa hồng, không khoe lệnh, một nhà giao dịch chỉ dựa vào chiến lược chiến thắng liên tục dựa trên phân tích chu kỳ)
(Bổ sung nền tảng: Ghi chú sinh tồn của nữ trader hàng đầu trong lĩnh vực tiền mã hóa: Đừng để “giàu nhanh” phá hỏng bạn)
Mục lục bài viết
Chuyển đổi
- Phần I: Lý thuyết xác suất, ngôn ngữ của bất định
- Phần II: Thống kê — Học cách lắng nghe dữ liệu
- Phần III: Đại số tuyến tính — Máy móc vận hành mọi thứ
- Phần IV: Vi tích phân và tối ưu hóa — Ngôn ngữ của sự biến đổi
- Phần V: Vi tích phân ngẫu nhiên — Ngưỡng cửa thực sự của Quant
- Polymarket
- LMSR định giá niềm tin như thế nào
- Bản đồ sự nghiệp giao dịch định lượng: Bốn dạng mô hình
- Hộp công cụ và danh sách sách tham khảo
- Ba điều tác giả ước gì mình biết sớm hơn
Lời tuyên bố biên dịch: Bài viết này không phải là lời khuyên đầu tư, thị trường có rủi ro, vui lòng tự nghiên cứu kỹ lưỡng.
Trước tiên, một vài con số: Đến năm 2025, tổng gói lương của các nhà Quant mới tốt nghiệp tại các tổ chức hàng đầu dao động từ 300.000 đến 500.000 USD/năm. Tuyển dụng AI/ML trong ngành tài chính tăng trưởng trung bình 88% mỗi năm. Con đường này có bản đồ chưa?
Bài viết này là thứ mà tác giả ước gì khi mới bắt đầu, có ai đó đưa cho anh ấy. Lộ trình học tập đã được sắp xếp theo thứ tự “bạn nên học gì trước”, mỗi khái niệm dựa trên khái niệm trước đó, giống như chơi game: bạn không thể nhảy cấp. Nhưng nếu bạn thực sự nghiêm túc, không chỉ xem các video giới thiệu tài chính nhàm chán trên YouTube (đó chỉ là lãng phí thời gian), mà thực sự giải đề, tự làm — khoảng 18 tháng, bạn sẽ từ người không biết gì trở thành người hiểu rõ một chút về lĩnh vực này.
Hãy để tất cả kiến thức giao dịch bạn nghĩ mình đã biết sang một bên. Phần lớn mọi người nghĩ rằng giao dịch định lượng là chọn cổ phiếu, có quan điểm về Tesla, dự đoán báo cáo tài chính. Thật ra không phải vậy. Giao dịch Quant là toán học. Bạn làm về mối quan hệ thống kê, định giá các thị trường kém hiệu quả, và lợi thế mang tính cấu trúc dựa trên thực tế “thị trường là hệ thống phức tạp do những người có thể mắc lỗi hệ thống vận hành.”
Phần I: Lý thuyết xác suất, ngôn ngữ của bất định
Mọi thứ trong tài chính định lượng cuối cùng đều có thể rút gọn thành một câu hỏi: Tỷ lệ thắng là bao nhiêu? Nó có đứng về phía tôi không?
Đó chính là xác suất. Nếu bạn không hiểu sâu về xác suất, những phần phía sau của bài viết này sẽ không ý nghĩa gì với bạn.
Xác suất có điều kiện: Cách suy nghĩ của nhà Quant
Người bình thường nghĩ theo giá trị tuyệt đối: việc này đúng hay sai. Nhà Quant dùng cách suy nghĩ theo điều kiện: dựa trên những gì tôi biết hiện tại, khả năng xảy ra của việc này là bao nhiêu?
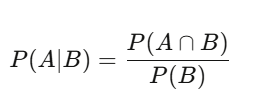
P(A|B) = P(A∩B) / P(B) — Cho biết, khi B xảy ra, xác suất của A bằng xác suất cả hai cùng xảy ra chia cho xác suất của B. Nghe có vẻ đơn giản, nhưng ảnh hưởng rất sâu rộng. Một cổ phiếu có 60% ngày tăng giá — đó là xác suất cơ bản. Nhưng ngày có khối lượng giao dịch cao hơn trung bình, xác suất tăng là 75%. Điều kiện này mới là thông tin có ý nghĩa; xác suất 60% ban đầu chỉ là nhiễu.
Định lý Bayes: Cập nhật đánh giá của bạn ngay lập tức
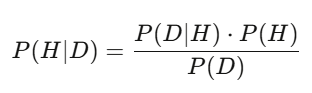
Sau = (xác suất nhận dữ liệu này khi giả thuyết đúng) × tiên nghiệm ÷ (xác suất nhận dữ liệu này trong mọi giả thuyết). Trong thực tế, bạn dùng sampling Monte Carlo để tính. Cách suy nghĩ tương tự: Bayes là cách bạn điều chỉnh đánh giá của mình ngay khi có thông tin mới. Giả sử mô hình nói cổ phiếu đó đáng 50 USD, báo cáo tài chính ra, doanh thu cao hơn dự kiến 3% — xác suất hậu nghiệm theo Bayes sẽ tăng lên. Người cập nhật nhanh nhất, chính xác nhất, sẽ thắng.
Giá trị kỳ vọng và phương sai: Hai người bạn tốt nhất của bạn
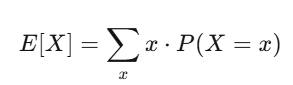
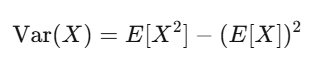
Giá trị kỳ vọng thể hiện độ tin cậy của niềm tin bạn; phương sai thể hiện rủi ro. Nếu chiến lược của bạn có kỳ vọng dương và bạn có thể chịu đựng được dao động do phương sai mang lại, khả năng cao bạn sẽ có lợi nhuận.
Bài tập Level 1 (mỗi ngày 2 giờ, 3-4 tuần)
- Đọc: Blitzstein & Hwang, “Introduction to Probability” (PDF miễn phí của Harvard), làm hết tất cả các bài từ chương 1 đến 6
- Lập trình: mô phỏng 10.000 lần tung đồng xu, dùng trực quan để chứng minh định luật số lớn
- Lập trình: tự xây dựng bộ cập nhật Bayes, nhập tiên nghiệm và khả năng hợp lý, xuất ra hậu nghiệm
import numpy as np
import matplotlib.pyplot as plt
# Định luật số lớn: trung bình chạy hội tụ về xác suất thực
np.random.seed(42)
lans = np.random.choice([0, 1], size=10000, p=[0.5, 0.5])
trung_binh = np.cumsum(lans) / np.arange(1, 10001)
plt.figure(figsize=(10, 4))
plt.plot(trung_binh, linewidth=0.7)
plt.axhline(y=0.5, color='r', linestyle='--', label='Xác suất thực')
plt.xlabel('Số lần tung')
plt.ylabel('Trung bình chạy')
plt.title('Minh họa định luật số lớn')
plt.legend()
plt.savefig('lln.png', dpi=150)
print(f"Sau 10,000 lần: {trung_binh[-1]:.4f} (Xác suất thực: 0.5000)")
Phần II: Thống kê — Học cách lắng nghe dữ liệu
Sau khi biết nói ngôn ngữ xác suất, bạn cần học cách “nghe” dữ liệu để rút ra điều gì. Bài học đầu tiên của thống kê là: Phần lớn các phát hiện có vẻ ý nghĩa thực ra chỉ là nhiễu.

Kiểm định giả thuyết: Bộ lọc nhiễu của bạn
Bạn xây dựng mô hình, backtest ra lợi nhuận trung bình hàng năm 15%. Thật vậy không? Đặt giả thuyết vô hiệu H₀: “Chiến lược này có kỳ vọng lợi nhuận bằng 0”, tính thống kê kiểm định, ra p-value. Nhưng chú ý: nếu bạn thử 1.000 chiến lược ngẫu nhiên, chỉ dựa vào may mắn, có tới 50 chiến lược sẽ có p-value dưới 0.05. Đây là vấn đề kiểm tra nhiều lần. Giải pháp là chỉnh sửa Bonferroni (chia mức ý nghĩa cho số lần kiểm tra), hoặc kiểm soát tỷ lệ phát hiện giả. Mọi người mới bắt đầu đều đánh giá quá cao những gì mình tìm ra có ý nghĩa. 10 chiến lược đầu tiên của bạn đều chỉ là nhiễu. Hãy chấp nhận điều này, sẽ tiết kiệm rất nhiều tiền.
Phân tích hồi quy: Phân tích lợi nhuận
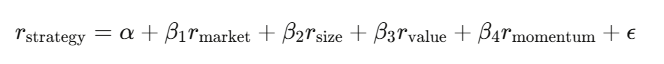
Hồi quy tuyến tính y = Xβ + ε là công cụ chủ đạo trong tài chính. Bạn hồi quy lợi nhuận chiến lược theo các yếu tố rủi ro đã biết, phần chệch α chính là phần lợi nhuận vượt trội — phần không thể giải thích bằng các yếu tố đã biết.
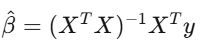
Nếu sau khi kiểm soát các yếu tố, α bằng 0, thì “lợi thế” của bạn chỉ là rủi ro thị trường ngụy trang. Phải dùng sai số chuẩn của Newey-West, vì dữ liệu tài chính có tự tương quan và dị hướng biến thiên, dùng sai số chuẩn bình thường như lái xe trên đường có kính vỡ.
** Ước lượng hợp lý cực đại (MLE)**
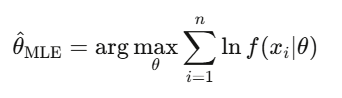
Đây là phương pháp hiệu chỉnh mô hình trong tài chính: phù hợp mô hình GARCH, ước lượng tham số jump diffusion, hoặc hiệu chỉnh định giá quyền chọn theo giá thị trường. Khi ai đó nói “calibrating” một mô hình, hầu hết đều đang nói đến MLE.
Bài tập Level 2 (4-5 tuần)
- Đọc: Wasserman, “All of Statistics”, từ chương 1 đến 13
- Tải dữ liệu lợi nhuận thực của cổ phiếu (sử dụng yfinance), kiểm tra tính phân phối chuẩn (chắc chắn thất bại), dùng MLE phù hợp phân phối t, so sánh kết quả
- Dùng statsmodels chạy hồi quy ba yếu tố Fama-French trên danh mục cổ phiếu
- Thực hiện kiểm tra hoán vị: xáo trộn ngày tháng 10.000 lần, so sánh hiệu suất sau hoán vị với hiệu suất thực
Phần III: Đại số tuyến tính — Máy móc vận hành mọi thứ
Nghe có vẻ nhàm chán, nhưng đại số tuyến tính chính là máy móc vận hành mọi thứ: xây dựng danh mục, phân tích thành phần chính, mạng nơ-ron, ước lượng hiệp phương sai, mô hình yếu tố. Không biết ma trận, không thể làm Quant.

Tư duy ma trận
Ma trận hiệp phương sai Σ mô tả cách mỗi tài sản di chuyển tương đối với các tài sản khác. Với 500 cổ phiếu, Σ là ma trận 500×500, có 125.250 giá trị riêng biệt. Ph variance của danh mục có thể rút gọn thành biểu thức: w’Σw, dạng bậc hai này là trung tâm của lý thuyết danh mục Markowitz, quản lý rủi ro, và mọi thứ khác.
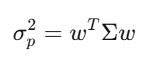
** Giá trị riêng: Những thứ thực sự quan trọng**
Trong vũ trụ 500 cổ phiếu, 5 vector đặc trưng đầu tiên giải thích tới 70% tổng phương sai. Các thành phần còn lại chỉ là nhiễu. Lần đầu dùng phân tích giá trị riêng, thế giới thay đổi: đây là giảm chiều, cũng là nền tảng của đầu tư theo yếu tố.
Bài tập Level 3 (4-6 tuần)
- Xem: Toàn bộ khóa học đại số tuyến tính MIT 18.06 của Gilbert Strang, không bỏ qua phần nào
- Đọc: Strang, “Introduction to Linear Algebra”, làm hết tất cả bài tập
- Thực hiện PCA trên lợi nhuận của S&P 500, vẽ biểu đồ phổ giá trị riêng, tìm ra 3 thành phần chính
- Tự xây dựng tối ưu hóa danh mục theo phương pháp trung bình phương sai
import numpy as np
import cvxpy as cp
np.random.seed(42)
n_assets = 10
mu = np.random.uniform(0.04, 0.15, n_assets)
A = np.random.randn(n_assets, n_assets) * 0.1
cov = A @ A.T + np.eye(n_assets) * 0.01
w = cp.Variable(n_assets)
objective = cp.Minimize(cp.quad_form(w, cov))
constraints = [
mu @ w >= 0.08, # Yêu cầu lợi nhuận tối thiểu
cp.sum(w) == 1, # Đầu tư toàn bộ vốn
w >= -0.1, # Tối đa 10% short
w <= 0.3 # Tối đa 30% long
]
prob = cp.Problem(objective, constraints)
prob.solve()
ret = mu @ w.value
vol = np.sqrt(w.value @ cov @ w.value)
sharpe = (ret - 0.03) / vol
print(f"Lợi nhuận danh mục: {ret:.4f}")
print(f"Độ lệch chuẩn danh mục: {vol:.4f}")
print(f"Tỉ lệ Sharpe: {sharpe:.4f}")
Phần IV: Vi tích phân và tối ưu hóa — Ngôn ngữ của sự biến đổi
Vi tích phân là ngôn ngữ mô tả sự biến đổi. Trong tài chính, mọi thứ đều biến đổi: giá cả, độ biến động, tương quan, phân phối xác suất mỗi giây đều thay đổi. Vi tích phân mô tả và khai thác các biến đổi này. Đạo hàm xuất hiện trong backprop của mạng nơ-ron, và trong tính toán các tham số Hy Lạp của quyền chọn.
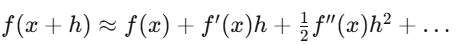
Phép khai triển Taylor là xấp xỉ cấp một của Delta hedging, Gamma hedging bổ sung điều chỉnh cấp hai. Vi tích phân Itô khác với vi tích phân thông thường vì các thành phần cấp hai của quá trình ngẫu nhiên không biến mất.
Bài tập Level 4 (4-5 tuần)
- Đọc: Boyd & Vandenberghe, “Convex Optimization” (PDF miễn phí của Stanford), từ chương 1 đến 5
- Tự làm gradient descent từ đầu, tối thiểu hóa hàm Rosenbrock
- Dùng cvxpy giải bài toán tối ưu danh mục có ràng buộc chi phí giao dịch
Phần V: Vi tích phân ngẫu nhiên — Ngưỡng cửa thực sự của Quant
Trước khi học vi tích phân ngẫu nhiên, bạn chỉ là một nhà khoa học dữ liệu yêu thích tài chính. Sau khi học xong, bạn mới chính thức trở thành Quant. Đây là khả năng mô hình hóa tính ngẫu nhiên trong thời gian liên tục, từ nguyên lý đầu tiên dẫn ra phương trình Black-Scholes, và hiểu tại sao thị trường phái sinh trị giá hàng nghìn tỷ USD lại vận hành như vậy.

Vận động Brown: Định dạng hóa tính ngẫu nhiên
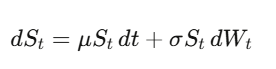
Vận động Brown (quá trình Wiener) W_t là một quá trình ngẫu nhiên liên tục thời gian. Cột mốc quan trọng — mọi thứ sau này đều dựa vào đó — là dW_t có “kích thước” bằng √dt, nghĩa là (dW_t)² = dt. Nghe có vẻ kỹ thuật, nhưng đây là một sự thật quan trọng nhất trong tài chính định lượng.
Định lý Itô
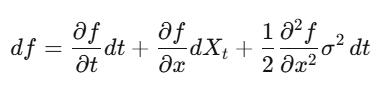
Trong vi tích phân thông thường, ta khai triển Taylor, các thành phần (dx)² nhỏ đến mức có thể bỏ qua. Nhưng khi x là quá trình ngẫu nhiên, (dW_t)² là cấp một, không thể bỏ qua. Định lý Itô: df = (∂f/∂t + μ∂f/∂x + ½σ²∂²f/∂x²)dt + σ∂f/∂x dW_t. Áp dụng vào định giá quyền chọn, ta có phương trình Black-Scholes.
Dẫn xuất Black-Scholes từ đầu
Bước 1: Giả sử V(S,t) là giá quyền chọn, dùng định lý Itô để tính dV.
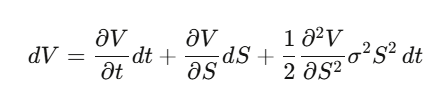
Bước 2: Tạo danh mục Delta hedge Π = V − (∂V/∂S)·S, tính dΠ — các thành phần dW_t sẽ triệt tiêu hoàn toàn, danh mục này gần như không rủi ro cục bộ.
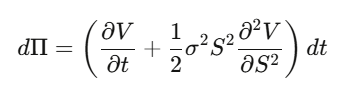
Bước 3: Danh mục đầu tư không rủi ro này phải sinh lợi theo lãi suất phi rủi ro.
Bước 4: Thay vào, sắp xếp, ta có phương trình vi phân riêng của Black-Scholes.
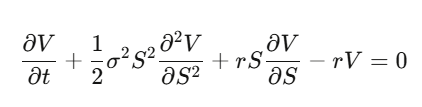
Chú ý điều gì đã xảy ra: tốc độ drift μ biến mất. Giá quyền chọn không còn liên quan đến kỳ vọng lợi nhuận của cổ phiếu, cũng không liên quan đến khẩu vị rủi ro. Bạn có thể coi mọi người là trung tính rủi ro để định giá quyền chọn. Hiểu rõ điều này lần đầu sẽ khiến bạn chóng mặt.
Với quyền chọn mua châu Âu có giá thực thi K, đáo hạn T, giải phương trình PDE này sẽ cho ra:
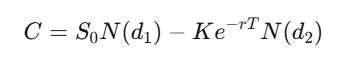
Trong đó d_1=
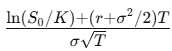
d_2=
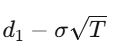
Các tham số Hy Lạp
- Delta Δ: Mỗi 1 USD thay đổi giá cổ phiếu, quyền chọn sẽ thay đổi bao nhiêu — tỷ lệ hedge của bạn
- Gamma Γ: Tốc độ thay đổi của Delta, thể hiện độ lồi của vị thế
- Theta Θ: Mất giá trị thời gian, vị thế dài thường âm
- Vega V: Độ nhạy với độ biến động, phần mà phần lớn lợi nhuận của các phái sinh nằm ở đây
- Rho ρ: Độ nhạy với lãi suất
import numpy as np
from scipy.stats import norm
def black_scholes(S, K, T, r, sigma, option_type='call'):
d1 = (np.log(S/K) + (r + sigma**2/2)*T) / (sigma*np.sqrt(T))
d2 = d1 - sigma*np.sqrt(T)
if option_type == 'call':
return S*norm.cdf(d1) - K*np.exp(-r*T)*norm.cdf(d2)
else:
return K*np.exp(-r*T)*norm.cdf(-d2) - S*norm.cdf(-d1)
def monte_carlo_option(S0, K, T, r, sigma, n_sims=500000):
Z = np.random.standard_normal(n_sims)
ST = S0 * np.exp((r - sigma**2/2)*T + sigma*np.sqrt(T)*Z)
payoffs = np.maximum(ST - K, 0)
price = np.exp(-r*T) * np.mean(payoffs)
stderr = np.exp(-r*T) * np.std(payoffs) / np.sqrt(n_sims)
return price, stderr
S, K, T, r, sigma = 100, 105, 1.0, 0.05, 0.2
bs_price = black_scholes(S, K, T, r, sigma)
mc_price, mc_err = monte_carlo_option(S, K, T, r, sigma)
print(f"Black-Scholes: ${bs_price:.4f}")
print(f"Monte Carlo: ${mc_price:.4f} ± {mc_err:.4f}")
Level 5: Bài tập (6-8 tuần, cấp độ khó nhất)
- Đọc: Shreve, “Stochastic Calculus for Finance II” — tiêu chuẩn vàng
- Lựa chọn thay thế: Arguin, “A First Course in Stochastic Calculus” — mới hơn, dễ tiếp cận hơn
- Tự chứng minh: dùng Itô để tính đạo hàm của f(S) = ln(S), dẫn ra phần trừ -σ²/2
- Tự chứng minh: toàn bộ phương trình Black-Scholes, bắt đầu từ lý thuyết Delta hedge
- Lập trình: tự xây dựng Black-Scholes từ đầu, so sánh với mô phỏng Monte Carlo, kiểm tra hội tụ
Polymarket
Đây là thị trường dự đoán thú vị nhất hiện nay, và các phép toán phía sau liên kết tất cả các chủ đề trong bài viết này:
Xác suất (probability), lý thuyết thông tin (information theory), tối ưu l convex (convex optimization), lập trình số nguyên (integer programming).
LMSR định giá niềm tin như thế nào
Quy tắc điểm thị trường (Logarithmic Market Scoring Rule - LMSR)
Do Robin Hanson phát minh, dùng để điều khiển các thị trường dự đoán tự động.
Với n kết quả (outcomes), hàm chi phí là:
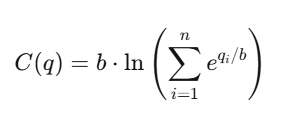
Trong đó:
- q_i: số lượng chưa thanh lý của kết quả thứ i (outstanding shares)
- b: tham số thanh khoản (liquidity parameter)
Giá của kết quả i là:
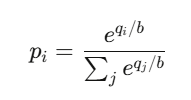
Thực ra, đây chính là hàm softmax —
cũng là hàm nền tảng của các bộ phân loại trong mạng nơ-ron (neural network classifiers).
Các đặc tính của nó gồm:
- Tổng các giá luôn bằng 1
- Giá luôn nằm trong khoảng (0,1)
- Thị trường luôn tồn tại giá, tương đương cung cấp thanh khoản vô hạn
Và mất mát tối đa của nhà tạo lập thị trường (market maker) bị giới hạn ở:
b × ln(n)
Bản đồ sự nghiệp giao dịch định lượng: Bốn dạng mô hình
Quant Researcher (QR): Tìm quy luật trong dữ liệu cấp PB, xây mô hình dự đoán, thiết kế chiến lược, cần trình độ toán học/thống kê/ML cao cấp hoặc nổi bật từ đại học. Ở các tổ chức như Jane Street, QR có hàng chục nghìn GPU.
Quant Developer/Engineer (QD): Xây dựng nền tảng giao dịch, engine thực thi, pipeline dữ liệu thời gian thực để mô hình của nhà nghiên cứu có thể vận hành thật sự. Yêu cầu kỹ năng C++/Rust/Python cho hệ thống độ trễ thấp, sản xuất.
Quant Trader (QT): Người ra quyết định, quản lý vốn, kiểm soát rủi ro, đưa ra các phán đoán tức thì. Thu nhập biến động lớn nhất, năm đỉnh có thể lên tới hàng chục triệu USD.
Risk Quant: Người kiểm duyệt, xác nhận mô hình, tính VaR, kiểm thử áp lực, tuân thủ pháp luật. Con đường sự nghiệp ổn định hơn, nhưng giới hạn thấp hơn. Các vai trò AI/ML mới nổi (dùng deep learning tạo tín hiệu) là hướng phát triển nhanh nhất, tuyển dụng tăng 88% năm 2025.
Dưới đây là mức lương trung bình tại các tổ chức hàng đầu Mỹ (Jane Street, Citadel, HRT):
- Nhân viên mới ra trường: 300.000 – 500.000 USD/ năm + tổng gói
- Trung cấp (3-7 năm): 550.000 – 950.000 USD
- Chuyên sâu (8 năm trở lên): 1 triệu – 3 triệu USD+
- Nhà giao dịch/PM nổi bật: 3 triệu – 30 triệu USD+
Các tổ chức trung bình như Two Sigma, DE Shaw, lương cho nhân viên mới khoảng 250.000 – 350.000 USD tổng gói. Trung bình, nhân viên của Jane Street năm 2025 đạt mức lương trung bình khoảng 1,4 triệu USD/năm, tính trung bình.
Quy trình phỏng vấn: Sơ tuyển hồ sơ → kiểm tra trực tuyến (dùng Zetamac tính nhẩm, mục tiêu trên 50 điểm, câu hỏi logic) → phỏng vấn qua điện thoại (vấn đề xác suất, trò chơi cá cược) → Superday (3-5 vòng liên tiếp, mô phỏng giao dịch, viết mã, trình bày trên bảng) — Jane Street cố tình ra đề khó đến mức không thể giải hết, để xem bạn tận dụng gợi ý và hợp tác ra sao. Gần đây, hơn 2/3 thực tập sinh là cử nhân CNTT, 1/3 là toán học, kiến thức tài chính không bắt buộc.
Chuẩn bị phỏng vấn tốt nhất là sách “Green Book” của Zhou Xinfeng (hướng dẫn thực chiến phỏng vấn tài chính định lượng, hơn 200 câu hỏi thực tế), kết hợp QuantGuide.io (phiên bản LeetCode dành cho định lượng) và Brainstellar để luyện tập.
Hộp công cụ và danh sách sách tham khảo
Ngăn xếp kỹ thuật Python: Xử lý dữ liệu dùng pandas/polars (Polars nhanh hơn 10-50 lần trên dữ liệu lớn), tính toán số dùng numpy/scipy, machine learning dạng bảng dùng xgboost/lightgbm, deep learning dùng pytorch, tối ưu hóa dùng cvxpy, phái sinh dùng QuantLib, thống kê dùng statsmodels, backtest dùng NautilusTrader hoặc vectorbt.
Nguồn dữ liệu miễn phí: yfinance, Finnhub (60 lần yêu cầu mỗi phút), Alpha Vantage. Trung cấp dùng Polygon.io (199 USD/tháng, độ trễ dưới 20ms). Còn cao cấp là Bloomberg Terminal (khoảng 32.000 USD/năm).
Danh sách sách theo thứ tự:
- Toán học nền tảng: Blitzstein & Hwang “Xác suất” → Strang “Đại số tuyến tính” → Wasserman “Tất cả về thống kê” → Boyd & Vandenberghe “Tối ưu hóa l convex” → Shreve “Vi tích phân ngẫu nhiên I & II”
- Tài chính định lượng: Hull “Quyền chọn, hợp đồng tương lai và các phái sinh khác” → Natenberg “Định giá và độ biến động quyền chọn” → López de Prado “Học máy trong tài chính nâng cao” → Ernest Chan “Giao dịch định lượng” → Zuckerman “Người giải mã bí ẩn thị trường”
- Phỏng vấn: Zhou “Green Book” → Crack “Nghe trên phố” → Joshi “Các câu hỏi phỏng vấn Quant”
- Cuộc thi: Kaggle của Jane Street (giải thưởng 100.000 USD), WorldQuant BRAIN (hơn 100.000 người dùng, mua tín hiệu alpha trả phí), Citadel Datathon (lối vào nhanh đến vị trí chính thức)
Ba điều tác giả ước gì mình biết sớm hơn
Ước lượng sai số mới là kẻ thù thực sự. Đặt cược Full Kelly, tối đa Markowitz không ràng buộc, mô hình ML với quá nhiều đặc trưng — tất cả đều thất bại vì quá khớp với nhiễu trong ước lượng tham số. Toán học vận hành hoàn hảo dưới tham số thực. Nhưng bạn không bao giờ có tham số thực. Khoảng cách giữa lý thuyết và thực tế luôn là sai số ước lượng, và những Quant giỏi nhất là những người thực sự tôn trọng điều này.
Công cụ đã dân chủ hóa, nhưng khả năng phán đoán thì không. Ai cũng có thể lấy được QuantLib, Polygon.io, PyTorch. Kỹ thuật là điều kiện cần, nhưng chưa đủ. Lợi thế nằm ở dữ liệu độc đáo, mô hình độc đáo hoặc khả năng thực thi độc đáo, chứ không phải cài đặt pip tốt hơn.
Toán học là hàng rào phòng thủ. AI có thể viết code, đề xuất chiến lược. Nhưng khả năng suy luận ra tại sao định lý Itô có phần dư thừa đó, chứng minh giá trị chiết khấu theo đo lường trung tính rủi ro là martingale, biết trong bài toán arbitrage danh mục, lề lồi là chặt hay lỏng — chính khả năng toán học này mới phân biệt “Quant tạo lợi thế” và “Quant mượn lợi thế của người khác”. Lợi thế mượn có hạn đến ngày hết hạn.
