Купити криптовалюту
Оплачуйте
USD
Купити та продати
HOT
Купуйте та продавайте криптовалюту через Apple Pay, картки, Google Pay, Банківський переказ тощо
P2P
0 Fees
Нульова комісія, понад 400 способів оплати та зручна купівля й продаж криптовалют
Gate Card
Криптовалютна платіжна картка, що дозволяє здійснювати безперешкодні глобальні транзакції.
Торгівля
Базовий
Спот
Вільно торгуйте криптовалютою
Маржа
Збільшуйте свій прибуток за допомогою кредитного плеча
Конвертація та блокова торгівля
0 Fees
Торгуйте будь-яким обсягом без комісій та прослизань
Токени з кредитним плечем
Отримайте швидкий доступ до позицій кредитного плеча
Премаркет
Торгуйте новими токенами до їх офіційного лістингу
Ф'ючерси
Ф'ючерси
Сотні контрактів розраховані в USDT або BTC
Опціони
HOT
Торгівля ванільними опціонами європейського зразка
Єдиний рахунок
Максимізуйте ефективність вашого капіталу
Демо торгівля
Запуск ф'ючерсів
Підготуйтеся до ф’ючерсної торгівлі
Ф'ючерсні події
Беріть участь у подіях, щоб виграти щедрі винагороди
Демо торгівля
Використовуйте віртуальні кошти для безризикової торгівлі
Earn
Запуск
CandyDrop
Збирайте цукерки, щоб заробити аірдропи
Launchpool
Швидкий стейкінг, заробляйте нові токени
HODLer Airdrop
Утримуйте GT і отримуйте масові аірдропи безкоштовно
Launchpad
Будьте першими в наступному великому проекту токенів
Бали Alpha
NEW
Торгуйте ончейн-активами і насолоджуйтеся аірдроп-винагородами!
Ф'ючерсні бали
NEW
Заробляйте фʼючерсні бали та отримуйте аірдроп-винагороди
Інвестиції
Simple Earn
Заробляйте відсотки за допомогою неактивних токенів
Автоінвестування
Автоматичне інвестування на регулярній основі
Подвійні інвестиції
Купуйте дешево і продавайте дорого, щоб отримати прибуток від коливань цін
Soft Staking
Earn rewards with flexible staking
Криптопозика
0 Fees
Заставте одну криптовалюту, щоб позичити іншу
Центр кредитування
Єдиний центр кредитування
Центр багатства VIP
Індивідуальне управління капіталом сприяє зростанню ваших активів
Управління приватним капіталом
Індивідуальне управління активами для зростання ваших цифрових активів
Квантовий фонд
Найкраща команда з управління активами допоможе вам отримати прибуток без клопоту
Стейкінг
Стейкайте криптовалюту, щоб заробляти на продуктах PoS
Розумне кредитне плече
NEW
Жодної примусової ліквідації до дати погашення — прибуток із плечем без зайвих ризиків
Випуск GUSD
Використовуйте USDT/USDC для випуску GUSD з дохідністю на рівні казначейських облігацій
Більше
X Планує «Smart Cashtags» для зв’язку крипто- та фондових тікерів з актуальними цінами
12год тому
Чи повинні політики мати право використовувати ринки прогнозів? Законопроект пропонує заборону
14год тому
Популярні теми
Дізнатися більше5.99K Популярність
6.92K Популярність
50.55K Популярність
13.92K Популярність
87.14K Популярність
Популярні активності Gate Fun
Дізнатися більше- Рин. кап.:$3.53KХолдери:00.00%
- Рин. кап.:$3.58KХолдери:20.04%
- 3

梭哈
梭哈
Рин. кап.:$0.1Холдери:10.00% - Рин. кап.:$0.1Холдери:00.00%
- Рин. кап.:$3.64KХолдери:20.62%
Закріпити
Інсайдери стверджують, що DeepSeek V4 перевершить Claude та ChatGPT у програмуванні, запуск відбудеться протягом кількох тижнів
Коротко
Згідно з повідомленнями, DeepSeek планує випустити свою модель V4 приблизно наприкінці лютого, і якщо внутрішні тести є будь-яким показником, гіганти штучного інтелекту з Кремнієвої долини мають бути насторожі. Заснований у Ханчжоу AI-стартап може орієнтуватися на випуск приблизно 17 лютого — природно, в День Лунарного Нового року — з моделлю, спеціально розробленою для завдань з кодування, згідно з The Information. Люди, які мають пряме знання про проект, стверджують, що V4 перевищує як Claude від Anthropic, так і серії GPT від OpenAI у внутрішніх бенчмарках, особливо при обробці дуже довгих кодових підказок. Звичайно, жоден бенчмарк або інформація про модель не були публічно оприлюднені, тому безпосередньо перевірити такі твердження неможливо. DeepSeek також не підтвердив ці чутки.
Проте, спільнота розробників не чекає офіційних слів. Reddit-спільноти r/DeepSeek та r/LocalLLaMA вже активно обговорюють, користувачі накопичують кредити API, а ентузіасти на X швидко діляться своїми прогнозами, що V4 може закріпити позицію DeepSeek як бійця, що відмовляється грати за правилами Кремнієвої долини з мільярдними бюджетами.
Це не буде першим збуренням DeepSeek. Коли компанія випустила свою модель розуміння R1 у січні 2025 року, вона спричинила $1 трілионний розпродаж на світових ринках. Причина? R1 DeepSeek співпав з моделлю o1 від OpenAI у бенчмарках з математики та логіки, при цьому, за повідомленнями, коштував лише $6 мільйонів на розробку — приблизно у 68 разів дешевше, ніж витрати конкурентів. Пізніше його модель V3 досягла 90.2% у бенчмарку MATH-500, обігнавши Claude з 78.3%, а оновлення “V3.2 Speciale” ще більше покращило його продуктивність.
Зображення: DeepSeek
Фокус на кодуванні у V4 стане стратегічним поворотом. У той час як R1 наголошував на чистому розумінні — логіці, математиці, формальних доведеннях — V4 є гібридною моделлю (з розумінням та нерозумінням), що орієнтована на корпоративний ринок розробників, де високоточне генерування коду безпосередньо перетворюється на дохід. Щоб домінувати, V4 потрібно перевершити Claude Opus 4.5, який наразі тримає рекорд SWE-bench Verified з 80.9%. Але якщо орієнтуватися на минулі запуски DeepSeek, то досягти цього цілком можливо навіть з урахуванням усіх обмежень, з якими стикається китайська лабораторія штучного інтелекту. Неповна таємна складова Якщо чутки правдиві, то як ця невелика лабораторія може досягти такого результату? Таємною зброєю компанії може бути її дослідження від 1 січня: Manifold-Constrained Hyper-Connections, або mHC. Співавтором цієї нової методики навчання є засновник Лян Веньфенг, і вона вирішує фундаментальну проблему масштабування великих мовних моделей — як розширити здатність моделі без її нестабільності або вибуху під час тренування. Традиційні архітектури ШІ змушують всю інформацію проходити через один вузький шлях. mHC розширює цей шлях у кілька потоків, які можуть обмінюватися інформацією без руйнування тренування.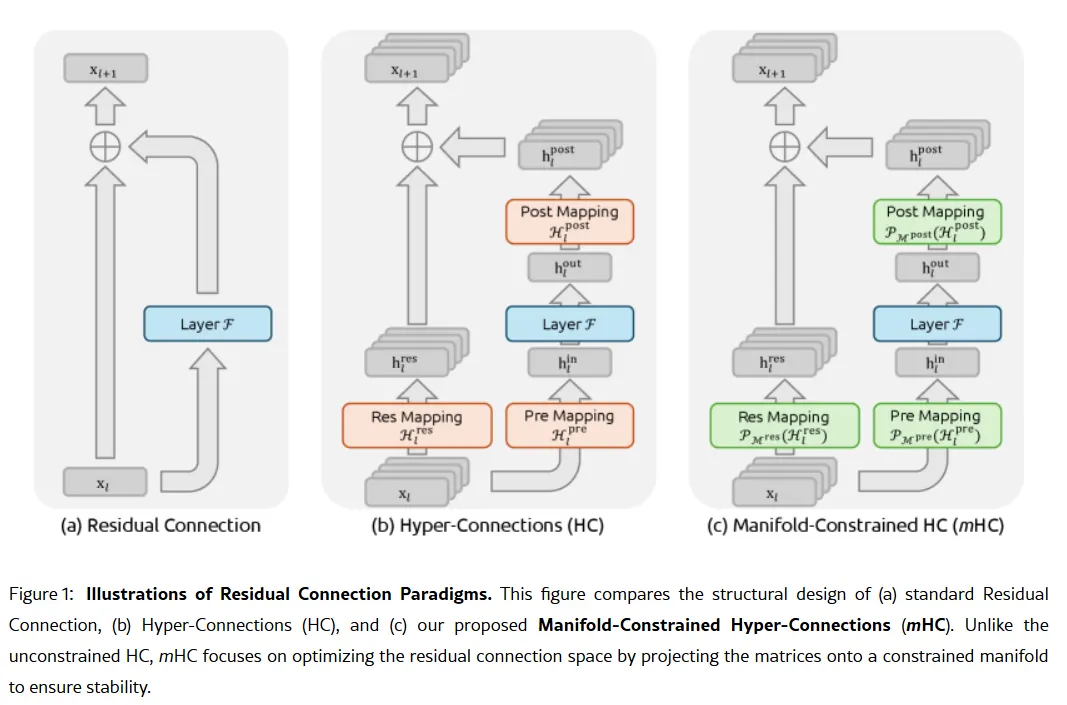
Зображення: DeepSeek
Вей Су, головний аналітик з AI у Counterpoint Research, назвала mHC “вражаючим проривом” у коментарях до Business Insider. Вона зазначила, що ця техніка показує, що DeepSeek може “обійти обмеження обчислень і відкрити нові прориви в інтелекті,” навіть за умов обмеженого доступу до сучасних чипів через американські експортні обмеження. Лян Джей Су, головний аналітик у Omdia, відзначив, що готовність DeepSeek публікувати свої методи свідчить про “нову впевненість у китайській індустрії штучного інтелекту.” Відкритий підхід компанії зробив її улюбленицею серед розробників, які бачать у ній втілення того, чим раніше була OpenAI, перш ніж вона перейшла до закритих моделей і раундів залучення мільярдів.
Не всі переконані. Деякі розробники на Reddit скаржаться, що моделі розуміння DeepSeek марнують обчислення на прості завдання, тоді як критики стверджують, що бенчмарки компанії не відображають реальну складність світу. Один пост на Medium під назвою “DeepSeek — це погано, і я вже не буду прикидатися, що це інакше” став вірусним у квітні 2025 року, звинувачуючи моделі у створенні “шаблонного нісенітниці з багами” та “галюцинаційних бібліотеках.” DeepSeek також має свої проблеми. Питання конфіденційності турбували компанію, і деякі уряди заборонили застосунок DeepSeek. Зв’язки компанії з Китаєм і питання цензури у її моделях додають геополітичного напруження до технічних дебатів. Проте, динаміка незаперечна. DeepSeek широко впроваджений у Азії, і якщо V4 виконає свої обіцянки щодо кодування, то й корпоративне впровадження у Заході може не забаритися.
Зображення: Microsoft
Ще один аспект — час. За даними Reuters, спочатку DeepSeek планував випустити модель R2 у травні 2025 року, але відтермінував її запуск через незадоволення засновника Ляна її продуктивністю. Тепер, коли V4 нібито орієнтований на лютий, а R2 можливо з’явиться у серпні, компанія рухається з такою швидкістю, що натякає на терміновість — або на впевненість. Можливо, і на обидва.