Коротко
- DeepSeek V4 може з’явитися протягом кількох тижнів, орієнтуючись на елітну продуктивність у кодуванні.
- Інсайдери стверджують, що він може перевершити Claude та ChatGPT у завданнях з довгим контекстом коду.
- Розробники вже в захваті напередодні потенційних змін.
Згідно з повідомленнями, DeepSeek планує випустити свою модель V4 приблизно наприкінці лютого, і якщо внутрішні тести є будь-якою ознакою, гіганти штучного інтелекту з Кремнієвої долини мають бути насторожі.
Заснований у Ханчжоу AI-стартап може орієнтуватися на випуск приблизно 17 лютого — природно, в День Лунарного Нового року — з моделлю, спеціально розробленою для завдань з кодування, згідно з The Information. Люди, які мають пряме знання про проект, стверджують, що V4 перевищує як Claude від Anthropic, так і серії GPT від OpenAI у внутрішніх бенчмарках, особливо при обробці дуже довгих кодових підказок.
Звичайно, жоден бенчмарк або інформація про модель не були публічно оприлюднені, тому безпосередньо перевірити такі твердження неможливо. DeepSeek також не підтвердив ці чутки.
Проте, спільнота розробників не чекає офіційних слів. Reddit-спільноти r/DeepSeek та r/LocalLLaMA вже активно обговорюють, користувачі накопичують кредити API, а ентузіасти на X швидко діляться своїми прогнозами, що V4 може закріпити позицію DeepSeek як бійця-андердога, який відмовляється грати за правилами Кремнієвої долини з мільярдними бюджетами.
Anthropic заблокував підписки на Claude у сторонніх додатках, таких як OpenCode, і, за повідомленнями, припинив доступ xAI та OpenAI.
Claude та Claude Code чудові, але ще не в 10 разів кращі. Це лише змусить інші лабораторії швидше рухатися у напрямку своїх моделей/агентів для кодування.
Очікується, що DeepSeek V4 з’явиться…
— Ючен Цзін (@Yuchenj_UW) 9 січня 2026
Це не буде першим збуренням DeepSeek. Коли компанія випустила свою модель розуміння R1 у січні 2025 року, вона спричинила $1 трилисячний розпродаж на світових ринках.
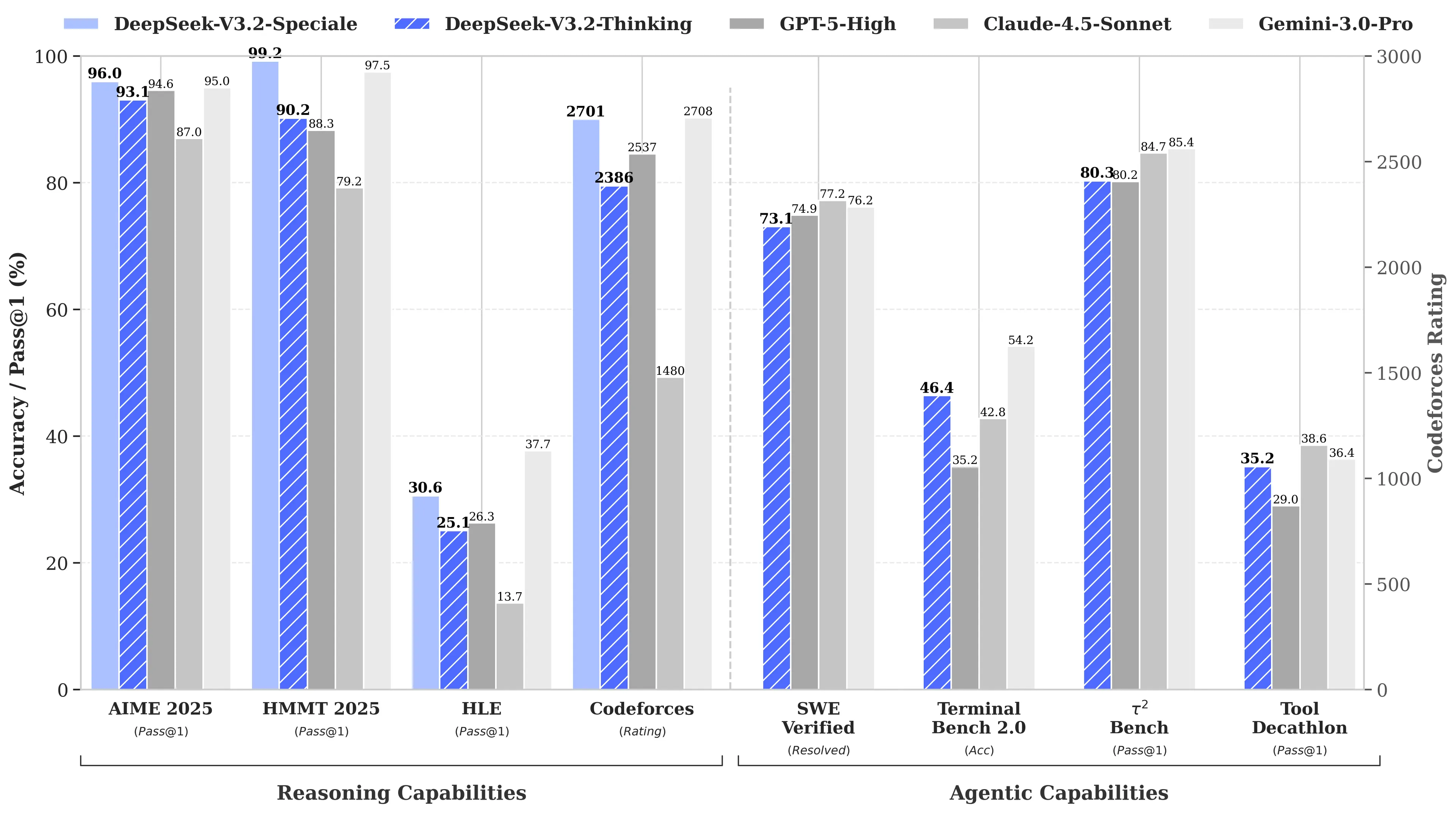
Причина? Модель DeepSeek R1 відповідала моделі OpenAI o1 за бенчмарками з математики та логіки, при цьому, за повідомленнями, коштувала всього $6 мільйонів на розробку — приблизно у 68 разів дешевше, ніж витрати конкурентів. Пізніше її модель V3 досягла 90.2% на бенчмарку MATH-500, обігнавши Claude з 78.3%, а оновлення “V3.2 Speciale” ще більше покращило її продуктивність.
Зображення: DeepSeek
Фокус V4 на кодуванні стане стратегічним поворотом. У той час як R1 наголошував на чистому розумінні — логіці, математиці, формальних доведеннях — V4 є гібридною моделлю (з розумінням та нерозумінням), яка орієнтована на корпоративний ринок розробників, де високоточне генерування коду безпосередньо перетворюється на дохід.
Щоб стати домінуючою, V4 потрібно буде перевершити Claude Opus 4.5, який наразі тримає рекорд SWE-bench Verified з 80.9%. Але якщо судити за минулими запусками DeepSeek, то досягти цього цілком можливо навіть з урахуванням усіх обмежень, з якими стикається китайська лабораторія штучного інтелекту.
Непублічний секрет
Якщо чутки правдиві, то як ця невелика лабораторія може досягти такого результату?
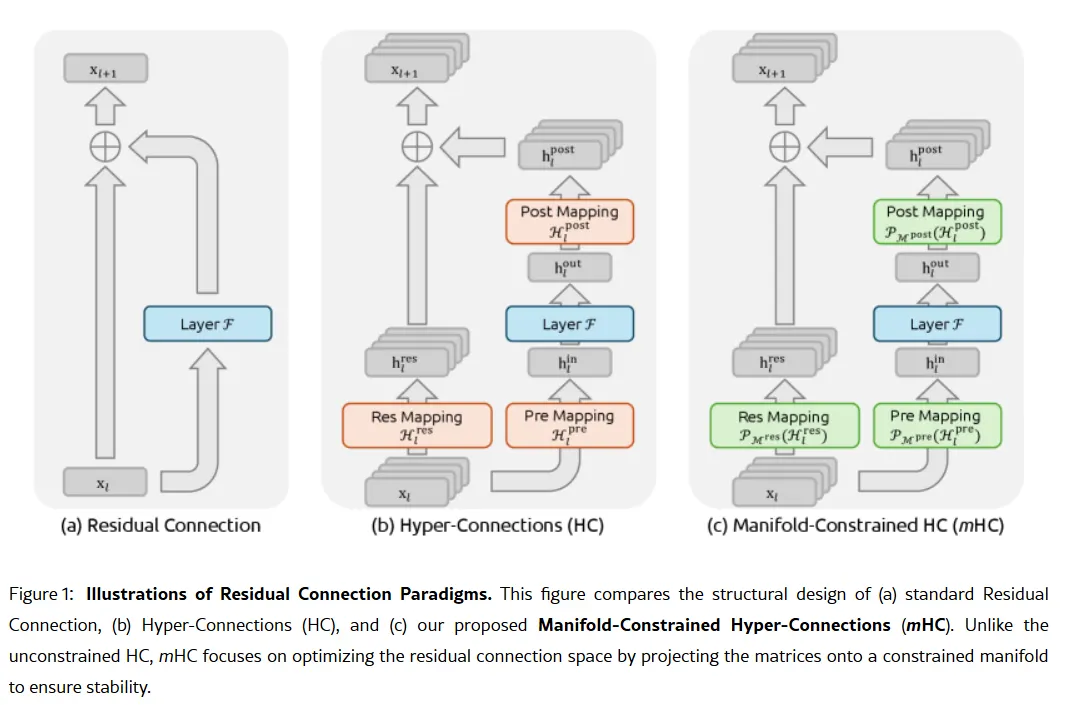
Її секретною зброєю може бути дослідження від 1 січня: Manifold-Constrained Hyper-Connections, або mHC. Співавтором цієї нової методики навчання є засновник Лян Веньфенг, і вона вирішує фундаментальну проблему масштабування великих мовних моделей — як розширити здатність моделі без її нестабільності або вибуху під час тренування.
Традиційні архітектури штучного інтелекту змушують всю інформацію проходити через один вузький шлях. mHC розширює цей шлях у кілька потоків, які можуть обмінюватися інформацією без руйнування тренування.
Зображення: DeepSeek
Вей Су, головний аналітик з AI у Counterpoint Research, назвала mHC “вражаючим проривом” у коментарях до Business Insider. Вона зазначила, що ця техніка показує, що DeepSeek може “обійти обмеження обчислень і відкрити нові прориви в інтелекті,” навіть за умов обмеженого доступу до передових чипів через американські експортні обмеження.
Лян Джей Су, головний аналітик у Omdia, відзначив, що готовність DeepSeek публікувати свої методи свідчить про “нову впевненість у китайській індустрії штучного інтелекту.” Відкритий підхід компанії зробив її улюбленицею серед розробників, які бачать у ній втілення того, чим раніше була OpenAI, перш ніж вона перейшла до закритих моделей і раундів залучення мільярдів.
Не всі переконані. Деякі розробники на Reddit скаржаться, що моделі розуміння DeepSeek марнують обчислення на прості завдання, тоді як критики стверджують, що бенчмарки компанії не відображають реальну складність світу. Один пост на Medium під назвою “DeepSeek — це погано, і я вже втомився прикидатися, що це не так” став вірусним у квітні 2025 року, звинувачуючи моделі у створенні “шаблонного нісенітниці з багами” та “галюцинаційних бібліотеках.”
DeepSeek також має свої проблеми. Питання конфіденційності турбували компанію, і деякі уряди заборонили нативний додаток DeepSeek. Зв’язки компанії з Китаєм і питання цензури у її моделях додають геополітичного напруження до технічних дискусій.
Проте, динаміка незаперечна. DeepSeek широко впроваджений в Азії, і якщо V4 виконає свої обіцянки щодо кодування, то ймовірно, що й корпоративне впровадження на Заході не забариться.
Зображення: Microsoft
Ще один аспект — час. За даними Reuters, спочатку DeepSeek планував випустити модель R2 у травні 2025 року, але відтермінував її запуск через незадоволення засновника Ляна її продуктивністю. Тепер, коли V4 нібито орієнтований на лютий, а R2 можливо з’явиться у серпні, компанія рухається з такою швидкістю, що натякає на терміновість — або впевненість. Можливо, і те, й інше.
Застереження: Інформація на цій сторінці може походити від третіх осіб і не відображає погляди або думки Gate. Вміст, що відображається на цій сторінці, є лише довідковим і не є фінансовою, інвестиційною або юридичною порадою. Gate не гарантує точність або повноту інформації і не несе відповідальності за будь-які збитки, що виникли в результаті використання цієї інформації. Інвестиції у віртуальні активи пов'язані з високим ризиком і піддаються значній ціновій волатильності. Ви можете втратити весь вкладений капітал. Будь ласка, повністю усвідомлюйте відповідні ризики та приймайте обережні рішення, виходячи з вашого фінансового становища та толерантності до ризику. Для отримання детальної інформації, будь ласка, зверніться до
Застереження.

