คนในวงการกล่าวว่า DeepSeek V4 จะเอาชนะ Claude และ ChatGPT ในด้านการเขียนโค้ด และจะเปิดตัวภายในไม่กี่สัปดาห์
สรุปโดยย่อ
- DeepSeek V4 อาจเปิดตัวภายในไม่กี่สัปดาห์ โดยมุ่งเน้นประสิทธิภาพการเขียนโค้ดระดับสุดยอด
- ผู้เชี่ยวชาญในวงการอ้างว่าอาจเอาชนะ Claude และ ChatGPT ในงานด้านโค้ดที่มีบริบทยาว
- นักพัฒนากำลังเตรียมตัวล่วงหน้าก่อนการเปลี่ยนแปลงที่อาจเกิดขึ้น
DeepSeek รายงานว่ากำลังวางแผนเปิดตัวโมเดล V4 ในช่วงกลางเดือนกุมภาพันธ์ และถ้าการทดสอบภายในเป็นสิ่งบ่งชี้ใด ๆ สาย AI ของซิลิคอนวัลเลย์ควรจะรู้สึกกังวล สตาร์ทอัป AI ที่ตั้งอยู่ในหางโจวนี้อาจตั้งเป้าเปิดตัวในวันที่ 17 กุมภาพันธ์ ซึ่งเป็นวันตรุษจีนตามธรรมชาติ พร้อมโมเดลที่ออกแบบมาเฉพาะสำหรับงานเขียนโค้ด ตามรายงานของ The Information ผู้ที่มีความรู้โดยตรงเกี่ยวกับโครงการอ้างว่า V4 มีประสิทธิภาพดีกว่า Claude ของ Anthropic และซีรีส์ GPT ของ OpenAI ในการทดสอบภายใน โดยเฉพาะเมื่อจัดการกับคำสั่งโค้ดยาวมาก แน่นอนว่า ไม่มีการแชร์ข้อมูลหรือการทดสอบใด ๆ ของโมเดลนี้สาธารณะ จึงเป็นไปไม่ได้ที่จะยืนยันข้ออ้างดังกล่าวโดยตรง DeepSeek เองก็ไม่ได้ยืนยันข่าวลือเหล่านี้เช่นกัน
อย่างไรก็ตาม ชุมชนนักพัฒนาก็ไม่ได้รอคำประกาศอย่างเป็นทางการ Reddit’s r/DeepSeek และ r/LocalLLaMA ก็เริ่มร้อนระอุ ผู้ใช้สะสมเครดิต API กันอย่างเต็มที่ และผู้สนใจบน X ก็รีบแบ่งปันการคาดการณ์ว่ารุ่น V4 อาจทำให้ DeepSeek กลายเป็นผู้ท้าทายที่ไม่ยอมแพ้ต่อกฎเกณฑ์พันล้านดอลลาร์ของซิลิคอนวัลเลย์
Anthropic บล็อกการสมัคร Claude ในแอปของบุคคลที่สาม เช่น OpenCode และรายงานว่าหยุดการเข้าถึง xAI และ OpenAI แล้ว
Claude และ Claude Code ดีมาก แต่ยังไม่ดีกว่า 10 เท่า นี่จะผลักดันให้ห้องปฏิบัติการอื่นเร่งพัฒนารุ่น/เอเจนต์โค้ดของตนเองมากขึ้น
DeepSeek V4 คาดว่าจะเปิดตัว…
— Yuchen Jin (@Yuchenj_UW) 9 มกราคม 2026
นี่ไม่ใช่การเปลี่ยนแปลงครั้งแรกของ DeepSeek เมื่อบริษัทเปิดตัวโมเดลการให้เหตุผล R1 ในเดือนมกราคม 2025 มันก็สร้างความตกใจในตลาดโลกถึง $1 ล้านล้านดอลลาร์ เหตุผลคืออะไร? R1 ของ DeepSeek สามารถเทียบเท่ากับโมเดล o1 ของ OpenAI ในการทดสอบด้านคณิตศาสตร์และการให้เหตุผล ถึงแม้ว่าจะใช้เงินเพียง $6 ล้านดอลลาร์ในการพัฒนา ซึ่งน้อยกว่าคู่แข่งประมาณ 68 เท่า โมเดล V3 ของมันในภายหลังทำคะแนนได้ 90.2% ในการทดสอบ MATH-500 ซึ่งสูงกว่าคะแนน 78.3% ของ Claude และอัปเดตล่าสุด “V3.2 Speciale” ก็ปรับปรุงประสิทธิภาพของมันให้ดีขึ้นอีกด้วย

ภาพ: DeepSeek
โฟกัสด้านการเขียนโค้ดของ V4 จะเป็นการเปลี่ยนกลยุทธ์อย่างมีนัยสำคัญ ในขณะที่ R1 เน้นการให้เหตุผลบริสุทธิ์—ตรรกะ คณิตศาสตร์ และการพิสูจน์ทางการ—V4 เป็นโมเดลแบบไฮบริด (ที่รวมการให้เหตุผลและงานที่ไม่ใช่การให้เหตุผล) ซึ่งมุ่งเป้าไปที่ตลาดนักพัฒนาระดับองค์กร ซึ่งการสร้างโค้ดที่มีความแม่นยำสูงจะส่งผลโดยตรงต่อรายได้
เพื่อครองความเป็นผู้นำ V4 จะต้องเอาชนะ Claude Opus 4.5 ซึ่งปัจจุบันถือสถิติ Verified ใน SWE-bench ที่ 80.9% แต่ถ้าพิจารณาจากการเปิดตัวในอดีตของ DeepSeek ก็อาจไม่ใช่เรื่องที่เป็นไปไม่ได้ แม้จะมีข้อจำกัดต่าง ๆ ที่ห้องปฏิบัติการ AI จีนต้องเผชิญ
ซอสลับลับที่ไม่ค่อยลับ
สมมติว่าข่าวลือเป็นความจริง แล้วห้องปฏิบัติการเล็ก ๆ นี้จะสามารถทำเช่นนี้ได้อย่างไร?
อาวุธลับของบริษัทอาจอยู่ในเอกสารวิจัยเมื่อวันที่ 1 มกราคม: Manifold-Constrained Hyper-Connections หรือ mHC ซึ่งร่วมเขียนโดยผู้ก่อตั้ง Liang Wenfeng วิธีการฝึกใหม่นี้แก้ปัญหาพื้นฐานในการขยายขนาดโมเดลภาษาใหญ่—ว่าจะขยายความสามารถของโมเดลโดยไม่ให้มันเสถียรหรือระเบิดระหว่างการฝึก
โครงสร้าง AI แบบดั้งเดิมบังคับให้ข้อมูลทั้งหมดผ่านเส้นทางแคบเดียว mHC ขยายเส้นทางนั้นเป็นหลายสตรีมที่สามารถแลกเปลี่ยนข้อมูลกันได้โดยไม่ทำให้การฝึกหยุดชะงัก
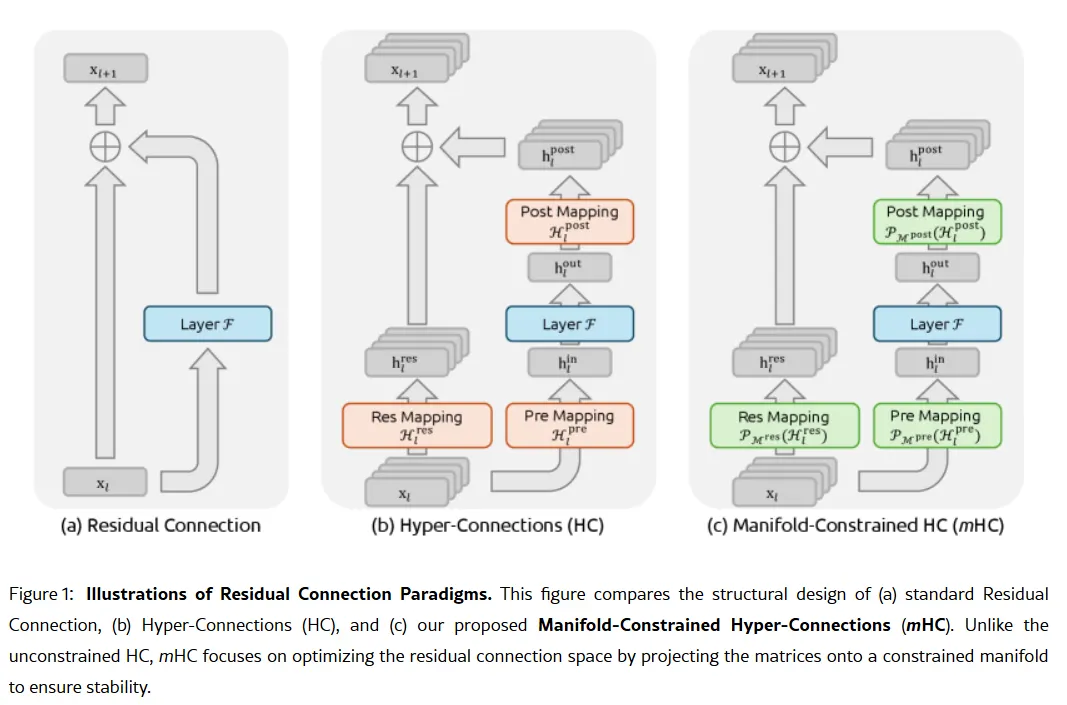
ภาพ: DeepSeek
Wei Sun นักวิเคราะห์หลักด้าน AI จาก Counterpoint Research เรียก mHC ว่าเป็น “ความก้าวหน้าที่น่าทึ่ง” ในคำให้สัมภาษณ์กับ Business Insider เทคนิคนี้แสดงให้เห็นว่า DeepSeek สามารถ “หลีกเลี่ยงคอขวดในการคำนวณและปลดล็อกความก้าวหน้าในด้านปัญญา” แม้จะมีการเข้าถึงชิปขั้นสูงจำกัดเนื่องจากข้อจำกัดการส่งออกของสหรัฐฯ Lian Jye Su นักวิเคราะห์อาวุโสจาก Omdia กล่าวว่าความเต็มใจของ DeepSeek ที่จะเผยแพร่วิธีการของตนเป็นสัญญาณของ “ความมั่นใจใหม่ในอุตสาหกรรม AI ของจีน” วิธีการเปิดเผยของบริษัททำให้กลายเป็นที่ชื่นชอบในหมู่นักพัฒนาที่มองว่าเป็นตัวแทนของสิ่งที่ OpenAI เคยเป็น ก่อนที่จะเปลี่ยนไปใช้โมเดลปิดและรอบระดมทุนพันล้านดอลลาร์
แต่ไม่ใช่ทุกคนจะเชื่อมั่น บางนักพัฒนาบน Reddit บ่นว่าโมเดลการให้เหตุผลของ DeepSeek ใช้คำนวณบนงานง่าย ๆ ในขณะที่นักวิจารณ์อ้างว่ามาตรฐานของบริษัทไม่สะท้อนความยุ่งเหยิงในโลกจริง โพสต์บน Medium ชื่อ “DeepSeek แย่—และฉันก็เลิกแกล้งทำเป็นว่าไม่ใช่” ไปไวในเดือนเมษายน 2025 ซึ่งกล่าวหาว่าโมเดลสร้าง “เนื้อหาน้ำมันและบั๊ก” และ “ไลบรารีที่ hallucinated”
DeepSeek ก็มีภาระหนักเช่นกัน ความกังวลด้านความเป็นส่วนตัวเป็นปัญหากับบริษัท โดยบางรัฐบาลก็ห้ามใช้แอปพลิเคชันพื้นเมืองของ DeepSeek ความสัมพันธ์ของบริษัทกับจีนและคำถามเกี่ยวกับการเซ็นเซอร์ในโมเดลของมันเพิ่มแรงเสียดทานทางภูมิรัฐศาสตร์ในการถกเถียงด้านเทคนิค
อย่างไรก็ตาม โมเมนตัมนี้เป็นสิ่งที่ปฏิเสธไม่ได้ DeepSeek ได้รับการนำไปใช้ในเอเชียอย่างแพร่หลาย และถ้า V4 สามารถทำตามสัญญาเรื่องการเขียนโค้ดได้ การนำไปใช้ในภาคธุรกิจในตะวันตกก็อาจตามมา
ภาพ: Microsoft
ยังมีเรื่องเวลาอีกด้วย ตามรายงานของ Reuters DeepSeek เคยวางแผนเปิดตัว R2 ในเดือนพฤษภาคม 2025 แต่ขยายเวลาการเปิดตัวหลังจากผู้ก่อตั้ง Liang ไม่พอใจกับผลการดำเนินงาน ตอนนี้ ด้วย V4 ที่คาดว่าจะเปิดตัวในกุมภาพันธ์ และ R2 อาจตามในเดือนสิงหาคม บริษัทกำลังเคลื่อนที่ด้วยความเร็วที่บ่งบอกถึงความเร่งด่วน—หรือความมั่นใจ อาจเป็นทั้งสองอย่าง