Когда инференс-нагрузки переходят от тестовых кластеров к реальным бизнес-приложениям, оптимальное решение уже не всегда заключается в полной централизации в ультра-крупных дата-центрах. В статье анализируется логика распределения между периферийными узлами, региональными центрами обработки данных и центральными кластерами с точки зрения задержки, пропускной способности, доступности и соответствия требованиям. Описаны ключевые моменты разделения задач, разграничения данных и операционного управления в гибридных топологиях, а также приводится сравнительный обзор в контексте всей инфраструктурной цепочки ИИ.
В публичных обсуждениях вычислительная мощность ИИ часто отождествляется с «ультра-крупными дата-центрами плюс топовые GPU». Для обучения и ряда централизованных сценариев инференса это определение справедливо. AI Infrastructure подразумевает, что инференс-запросы широко распределены, чувствительны к задержкам, требуют сохранения данных в домене, а перебои в сети или перегрузки недопустимы. В таких случаях топология инференса становится инфраструктурной задачей: вычислительная мощность должна быть не только доступной, но и находиться в нужном географическом положении и сетевом уровне.
Если рассматривать инфраструктуру ИИ как единую цепочку — от чипа до сервисов и управления, — статья фокусируется на топологии и формах размещения: как распределять вычисления и данные между периферией, регионом и центром для баланса между задержкой, стоимостью, доступностью и соответствием. Вопросы энергопитания, упаковки и HBM относятся к upstream-тематике, а детали многомодельной маршрутизации и управления агентами на уровне предприятия дополняют производственные процессы.
Зачем обсуждать «распределённую топологию инференса»
Централизованный инференс обеспечивает унифицированные операции, гибкое масштабирование и высокую загрузку ресурсов. Однако если бизнес характеризуется следующими особенностями, топологические решения существенно влияют на опыт и стоимость:
-
Жёсткие требования к задержке: промышленное управление, взаимодействие в реальном времени, аудио/видео-связь и офлайн-ретейл чувствительны к задержкам; длинные обратные маршруты усиливают джиттер.
-
Суверенитет и локализация данных: персональные данные, финансовые транзакции, государственные услуги и здравоохранение требуют хранения данных в домене, стране или определённом регионе.
-
Пропускная способность и стоимость возврата: массовая загрузка исходных данных с конечных точек в центральный инференс делает магистральные сети и исходящий трафик ключевыми статьями затрат.
-
Доступность и устойчивость: при сбоях в глобальных сетях, колебаниях DNS или региональных перегрузках полностью центральные архитектуры подвержены риску массовой недоступности.
-
Офлайн или слабая сеть: в шахтах, на судах и отдельных производственных площадках требуется локальная работоспособность, а не полная зависимость от онлайн-соединения.
Эти задачи нельзя решить только «усилением центральных моделей», так как их суть — в физическом расстоянии, сетевых маршрутах и политических границах, а не в пиковых вычислениях одного инференса.
Многоуровневое размещение: задачи периферии, региона и центра
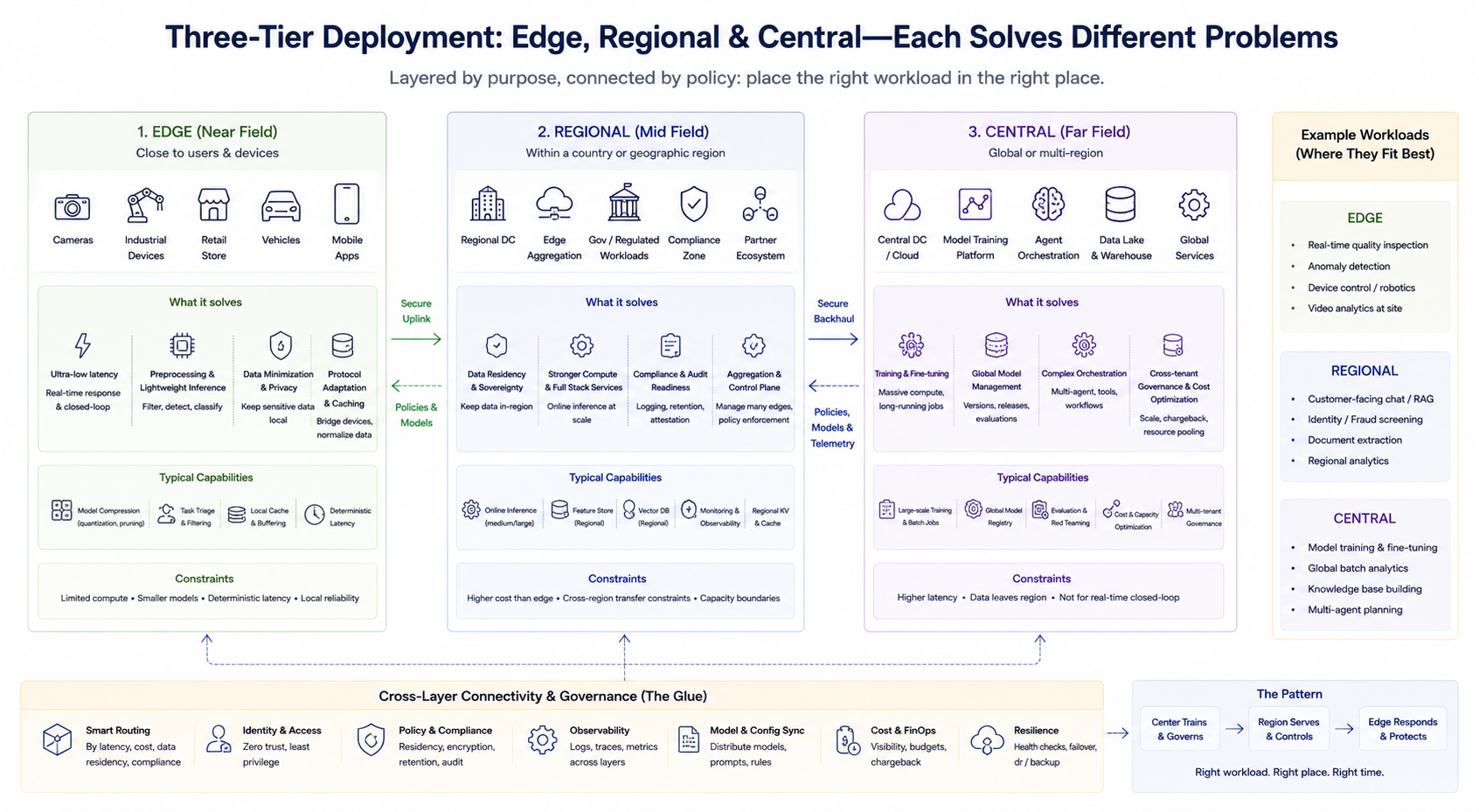
Инженерная практика предполагает не бинарный выбор, а многоуровневую комбинацию. Упрощённая схема помогает понять задачи каждого уровня (конкретные названия могут отличаться):
Периферийный уровень (ближнее поле)
Находится максимально близко к пользователям или устройствам, выполняет задачи с низкой задержкой: предварительная обработка, лёгкий инференс, кэширование, адаптация протоколов. Идеален для замкнутых циклов в реальном времени и минимизации передачи чувствительных данных. Вычислительная мощность ограничена, поэтому акцент на сжатии моделей, сокращении задач и гарантированной задержке.
Региональный уровень (среднее поле)
Обеспечивает большую вычислительную мощность и более полный сервис-стек в рамках страны или региона, решает задачи локализации данных, аудита соответствия и средних по масштабу инференсов. Часто выступает в роли агрегатора и управляющей плоскости для нескольких периферийных узлов.
Центральный уровень (дальнее поле)
Выполняет обучение, крупные пакетные обработки, глобальное управление моделями, сложную оркестрацию агентов, кросс-арендное управление и оптимизацию затрат. Подходит для задач, менее чувствительных к задержке, но требующих высокой вычислительной мощности и агрегации данных.
Эти уровни не образуют жёсткую иерархию, а разделяются по бизнес-задачам. Предприятия могут одновременно запускать центральное обучение, региональный онлайн-инференс и периферийное обнаружение в реальном времени, направляя запросы на нужный уровень по маршрутизационным стратегиям.
Разделение задач: что остаётся на периферии, что возвращается в центр
Принципы разделения обычно строятся по четырём осям: минимизация данных, бюджет задержки, сложность модели и частота обновлений.
Задачи для периферии (при условии достаточной мощности):
-
Извлечение признаков в реальном времени, обнаружение объектов, контроль качества и другие замкнутые циклы с низкой задержкой
-
Лёгкий инференс после локальной десенсибилизации (например, загрузка только векторных признаков вместо исходных медиа)
-
Резервный инференс и стратегии кэширования при слабой сети
Задачи для центра или региона:
-
Агентные процессы с большим контекстом, мощными моделями, сложными инструментами или мультисистемной оркестрацией
-
Аналитический инференс с междепартаментской агрегацией данных
-
Чувствительные вызовы, требующие централизованного аудита и единого управления ключами
Типовые ошибки — попытка запускать на периферии крупные модели с длинным контекстом (OOM) или полностью отправлять замкнутые циклы с низкой задержкой в центр (нарушение ритма производства). Цель — не максимизация периферии, а оптимальное размещение задач с учётом ограничений.
Суверенитет данных и соответствие: топология определяет архитектуру
Требования к суверенитету данных напрямую влияют на размещение инференса. Модели можно загрузить локально, но логи, кэши, векторные индексы и трассировки могут нести риски несоответствия. На практике основные вопросы:
-
Какие данные должны храниться и обрабатываться на периферии или региональном уровне
-
Какие метаданные могут покидать регион или отправляться в облако, требуется ли анонимизация и ограничение сроков хранения
-
Допускается ли кросс-региональное использование разных версий моделей и провайдеров (во избежание «дрейфа соответствия»)
-
Можно ли при аудите восстановить, что вывод был сгенерирован в определённом месте, времени и на основе конкретных данных
Ответы на эти вопросы зачастую определяют возможность запуска системы, а не «открытость исходного кода модели». Соответствие — не надстройка для периферийного инференса, а изначальное условие проектирования топологии.
Сеть, энергопитание и эксплуатация: реальные издержки распределённого размещения
Распределённый инференс несёт системные издержки, которые нужно учитывать при планировании:
-
Сеть: с ростом числа периферийных и региональных узлов усложняются управление сертификатами, выделенные линии / SD‑WAN, DNS и маршрутизация. Хвостовую задержку труднее контролировать при множественных маршрутах.
-
Энергопитание и дата-центры: периферийные площадки рассредоточены, энергоэффективность и охлаждение на единицу мощности часто ниже, чем в крупных центрах; региональные центры занимают промежуточное положение. Скорость подключения питания и установки стоек по-прежнему ограничивает масштабирование, но теперь ограничение — не «один кампус», а «многоточечный параллелизм».
-
Эксплуатация и консистентность версий: при релизе моделей, промптов, маршрутизации и индексов на многих точках возникает дрейф версий. Требуются унифицированные пайплайны релиза, стратегии отката и проверки работоспособности, иначе затраты на устранение сбоев сведут на нет выигрыш по задержке.
-
Расширение периметра безопасности: больше узлов — больше сертификатов, точек входа и локальных носителей. Физическая безопасность и цикл обновления на периферии часто слабее, чем в центре, поэтому нужны минимальные привилегии и удалённое управление.
Распределённая топология — это не просто вынесение вычислений ближе к бизнесу, а перенос части эксплуатационной и управленческой сложности на площадку заказчика. Если организационные возможности и инструменты платформы не соответствуют новому уровню, преимущества топологии реализовать не удастся.
Взаимосвязь с централизованным инференсом: как реализуются гибридные архитектуры
Большинство зрелых решений используют гибридные архитектуры: центр отвечает за обучение, глобальные политики и тяжёлые задачи; регион — за онлайн-сервисы в зонах соответствия; периферия — за низкую задержку и локальную устойчивость. Типовые инженерные паттерны:
-
Многоуровневое кэширование и повторное использование результатов: периферия обслуживает частые запросы, промахи отправляются в центр. Необходимо определить ключи кэша, TTL и политику по чувствительным данным.
-
Разделение моделей и малые модели на периферии: периферия выполняет детекцию или классификацию, центр — слияние крупных моделей и генерацию интерпретаций (по сценарию).
-
Асинхронный возврат и агрегация: периферия принимает решения в реальном времени, затем асинхронно отправляет десенсибилизированные выборки или метрики для итерации моделей и мониторинга.
-
Единая плоскость управления: маршрутизация, квоты, мониторинг и управление ключами централизованы максимально, а выполнение децентрализовано, чтобы избежать изоляции периферии.
Ключ к успешной гибридной архитектуре — единая плоскость управления и многоуровневая плоскость выполнения, а не просто увеличение числа узлов.
Заключение
Суть обсуждения периферийного и распределённого инференса — не в лозунге децентрализации, а в инженерном балансе между задержкой, пропускной способностью, соответствием и эксплуатационными издержками. По мере масштабирования бизнеса топологические решения формируют модели, сетевые архитектуры и процессы управления. Пренебрежение этим уровнем может привести к мощным центральным вычислениям, но нестабильной работе на передовой.









