アーキテクチャと内部構造
ゼロ知識コプロセッサ(ZK Coprocessor)のアーキテクチャは、オフチェーンで動作しながらも暗号学的にオンチェーンシステムと結び付けられた計算エンジンとしての役割を反映しています。このモジュールでは、ZK コプロセッサのシステム構造、内部におけるデータと計算の流れ、そしてトラストレスな検証を可能にする暗号学的プリミティブについて解説します。このアーキテクチャを理解することは、コプロセッサをアプリケーションに統合しようとする開発者にとっても、その信頼性やセキュリティを評価しようとするアナリストにとっても不可欠です。
ZK コプロセッサの中核コンポーネント
ZK コプロセッサはいくつかの基本コンポーネントから構成されており、計算をオフロードしつつ検証可能性を維持するよう連携して動作します。システムの中心にあるのは 実行環境で、多くの場合ゼロ知識仮想マシン(zkVM)やドメイン固有の回路コンパイラとして実装されます。この環境はコードや計算タスクを解釈し、それをゼロ知識証明の生成に適した算術回路へと変換します。
プローバーは計算を実行し、暗号学的証明を生成する主体です。入力データを受け取り、必要なロジックをオフチェーンで実行し、機微な詳細を明かすことなく計算の正しさを保証する簡潔な証明を構築します。 ベリファイアは通常、対象ブロックチェーン上にデプロイされたスマートコントラクトであり、この証明を最小限のリソースで検証します。設計上、検証は元の計算に比べてはるかに軽量であり、効率的なオンチェーン検証を可能にします。
補助的なコンポーネントとして データインターフェース があり、コプロセッサがさまざまなソースから情報にアクセスする方法を管理します。あるコプロセッサはオンチェーンデータを直接照会し、別のものは分散型ストレージネットワークやオフチェーン API といった履歴データや外部データセットを集約します。このデータの整合性もまた証明可能でなければならず、多くの場合は Merkle 証明や類似の暗号学的コミットメントを用いて保証されます。
計算の流れ
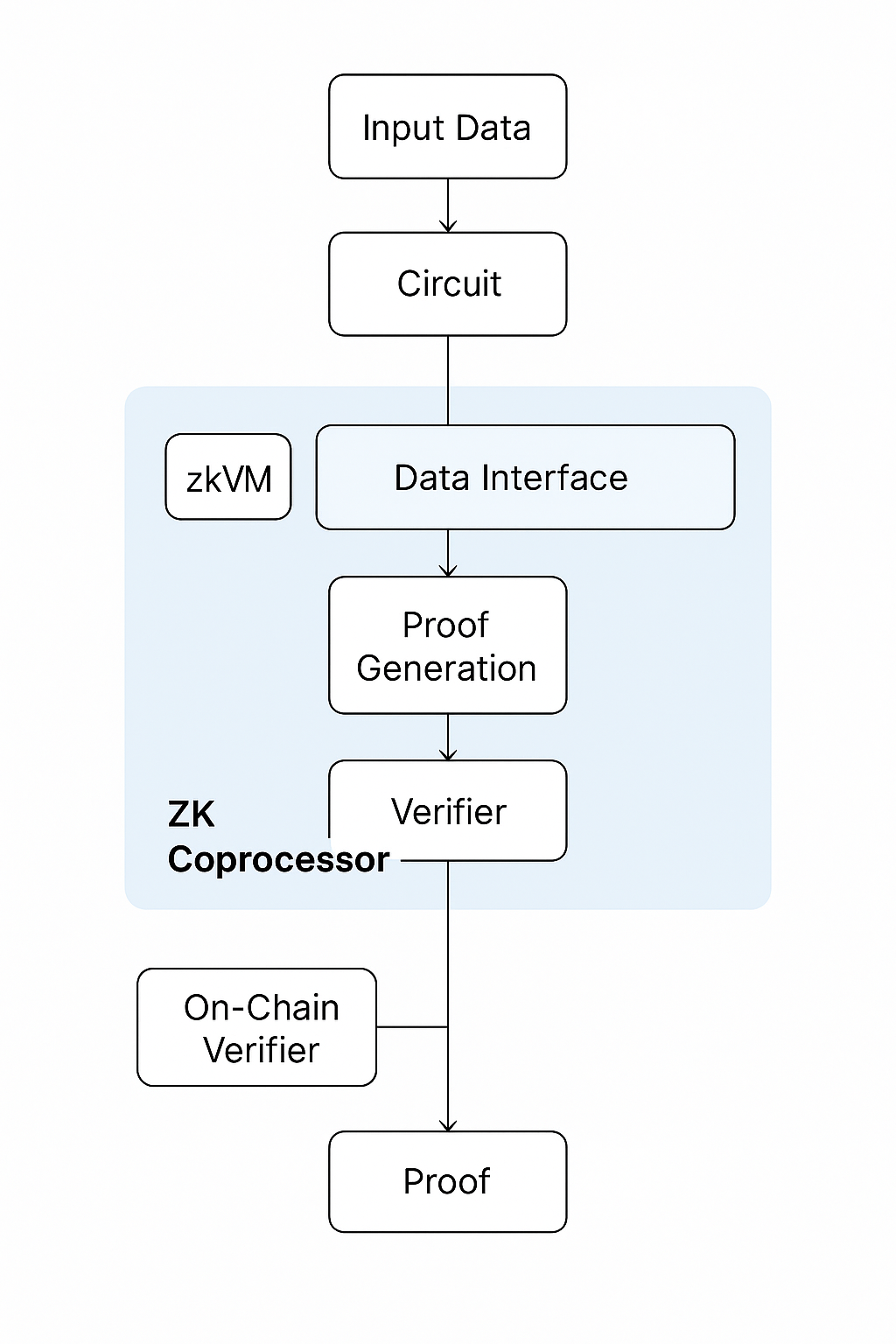
ZK コプロセッサの動作は、大規模な計算処理と軽量な検証を分離する明確な手順に従います。このプロセスは、分散型アプリケーションやスマートコントラクトがオンチェーンで効率的に実行できない計算を要求するところから始まります。この要求はコプロセッサに送られ、コプロセッサはブロックチェーンの状態、外部データフィード、あるいはユーザー提供のソースから必要な入力を収集します。
入力が揃うと、コプロセッサは zkVM または回路環境内で計算を実行します。このステップでは、計算が構造化された算術回路に変換され、ゼロ知識証明の生成が可能になります。この証明は、計算自体を再実行することなく検証できる形で、全体の実行プロセスを要約したものとなります。
証明が生成されると、それはブロックチェーンへ送信されます。その後、ベリファイアのスマートコントラクトが公開されている検証キーを用いて証明を検証します。証明が有効であれば、その計算結果は承認され、オンチェーンの状態更新、スマートコントラクトのロジック実行、あるいはさらなる分散型プロセスの入力として利用できるようになります。このフローによって、効率性を損なうことなく計算の完全性が維持されます。
証明生成の技術
証明の生成は、ZK コプロセッサのアーキテクチャにおいて最も計算負荷の高い要素です。これは、多項式コミットメントやマルチスカラー乗算といった高度な暗号技術に依存しており、計算を代数的制約の集合へと変換します。これらの制約を解くことで、簡潔な証明が生成されます。
現代のシステムでは、このプロセスをいくつかの技術によって最適化しています。 高速フーリエ変換(FFT) や 数論変換(NTT) が、多項式演算を高速化するために用いられます。これらは zk-SNARK や zk-STARK の構成において中心的な役割を果たします。 再帰(Recursion) も注目を集める技術の一つであり、証明を他の証明の中にネストすることを可能にします。再帰的証明システムにより、大規模な計算を小さな証明に分割し、それらを最終的に1つの簡潔な検証に集約する増分的な検証が実現されます。
これらの最適化は、ZK コプロセッサを現実のワークロードへスケールさせるうえで不可欠です。これらの最適化がなければ、証明生成は極めて遅く、またリソースを大量に消費するものとなり、オフチェーン計算の利点を損なってしまう可能性があります。
オンチェーン検証
検証フェーズは対象となるブロックチェーン上で行われ、計算コストを最小限に抑えるよう意図的に設計されています。コプロセッサが証明を提出すると、ベリファイアコントラクトはあらかじめ計算されたパラメータを用いて検証アルゴリズムを実行します。zk-SNARK システムでは、多くの場合一定時間で行えるペアリング検証が使用され、zk-STARK のベリファイアはハッシュベースのコミットメントや FRI(Fast Reed-Solomon Interactive Oracle Proofs of Proximity)プロトコルに依拠します。
ゼロ知識証明の簡潔さにより、検証には通常わずか数キロバイトのデータしか必要とせず、同等のオンチェーン計算に比べてごく一部のガスで実行可能です。この効率性こそが、ZK コプロセッサを実運用環境で実現可能なものにしています。その証明は、計算の正しさだけでなく、入力の完全性や出力の決定性までも確認します。
セキュリティモデルと脅威
ZK コプロセッサのセキュリティは、暗号学的な健全性とシステム設計の両方に依存しています。暗号学的には、その保証は楕円曲線ペアリングやハッシュベースのコミットメントといった基盤となる問題の困難性に依存しています。これらのプリミティブが安全である限り、生成された証明が偽造されることはありません。
しかし、コプロセッサの実装方法やデータの取得方法によっては、脆弱性が生じる可能性があります。悪意あるプローバーは、回路内の制約を回避したり、不正なデータを計算に入力したりすることを試みる可能性があります。これを防ぐために、コプロセッサはしばしば公開入力コミットメント、Merkle Root、あるいは信頼できるデータフィードに依存し、使用された入力が正当であることを証明します。回路の監査や厳密な形式的検証も、設計自体の誤りを防ぐために不可欠です。
より広いシステムの観点では、ライブネスや可用性への対応も必要となります。コプロセッサが中央集権的であったり単一のオペレーターにより管理されていたりすると、潜在的な信頼の前提や検閲リスクが生じます。新たな設計では、コプロセッサネットワークの分散化を目指し、複数のプローバーが証明生成において競争または協力できるようにすることで、特定の主体への依存を軽減しようとしています。
関連コース

暗号資産におけるアイデンティティ:主なプロジェクト

マスターノードトークンの紹介

分散型アイデンティティの基礎

暗号デリバティブ:主なプロジェクト

暗号資産における自分自身の調査(DYOR)を行う
