Insider sagen, DeepSeek V4 wird Claude und ChatGPT beim Programmieren übertreffen, Veröffentlichung innerhalb von Wochen
Kurzfassung
- DeepSeek V4 könnte innerhalb von Wochen erscheinen und auf erstklassige Programmierleistung abzielen.
- Insidern zufolge könnte es Claude und ChatGPT bei Langzeit-Codeaufgaben übertreffen.
- Entwickler sind bereits vor der möglichen Marktveränderung hype.
DeepSeek plant Berichten zufolge, sein V4-Modell um Mitte Februar zu veröffentlichen, und wenn interne Tests ein Indikator sind, sollten die KI-Giganten aus dem Silicon Valley nervös werden. Das in Hangzhou ansässige KI-Startup könnte eine Veröffentlichung um den 17. Februar anstreben—natürlich zum Chinesischen Neujahr—mit einem speziell für Programmieraufgaben entwickelten Modell, so The Information. Personen mit direktem Wissen über das Projekt behaupten, V4 übertrifft sowohl Anthropic’s Claude als auch OpenAI’s GPT-Serie in internen Benchmarks, insbesondere bei der Verarbeitung extrem langer Code-Eingaben. Natürlich wurden weder Benchmarks noch Informationen über das Modell öffentlich geteilt, sodass eine direkte Überprüfung solcher Behauptungen unmöglich ist. DeepSeek hat die Gerüchte ebenfalls nicht bestätigt.
Dennoch wartet die Entwicklergemeinschaft nicht auf offizielle Ankündigungen. Reddit’s r/DeepSeek und r/LocalLLaMA heizen bereits auf, Nutzer häufen API-Guthaben an, und Enthusiasten auf X teilen schnell ihre Vorhersagen, dass V4 die Position von DeepSeek als der kämpferische Underdog festigen könnte, der sich weigert, nach den milliardenschweren Regeln des Silicon Valley zu spielen.
Anthropic hat Claude-Abonnements in Drittanbieter-Apps wie OpenCode blockiert und angeblich den Zugang zu xAI und OpenAI abgeschaltet.
Claude und Claude Code sind großartig, aber noch nicht 10x besser. Das wird andere Labs nur dazu antreiben, bei ihren Programmiermodellen/-agenten schneller voranzukommen.
DeepSeek V4 soll erscheinen…
— Yuchen Jin (@Yuchenj_UW) 9. Januar 2026
Dies wäre nicht die erste Marktveränderung von DeepSeek. Als das Unternehmen im Januar 2025 sein R1-Reasoning-Modell veröffentlichte, löste es einen $1 trillionen-Verkauf in den globalen Märkten aus. Der Grund? DeepSeek’s R1 erreichte trotz angeblich nur $6 Millionen Entwicklungskosten die Leistung des OpenAI o1-Modells bei Mathematik- und Reasoning-Benchmarks—ungefähr 68-mal günstiger als die Konkurrenz. Sein V3-Modell erreichte später 90,2 % beim MATH-500-Benchmark, übertraf Claude mit 78,3 %, und das kürzlich aktualisierte „V3.2 Speciale“ verbesserte die Leistung noch weiter.
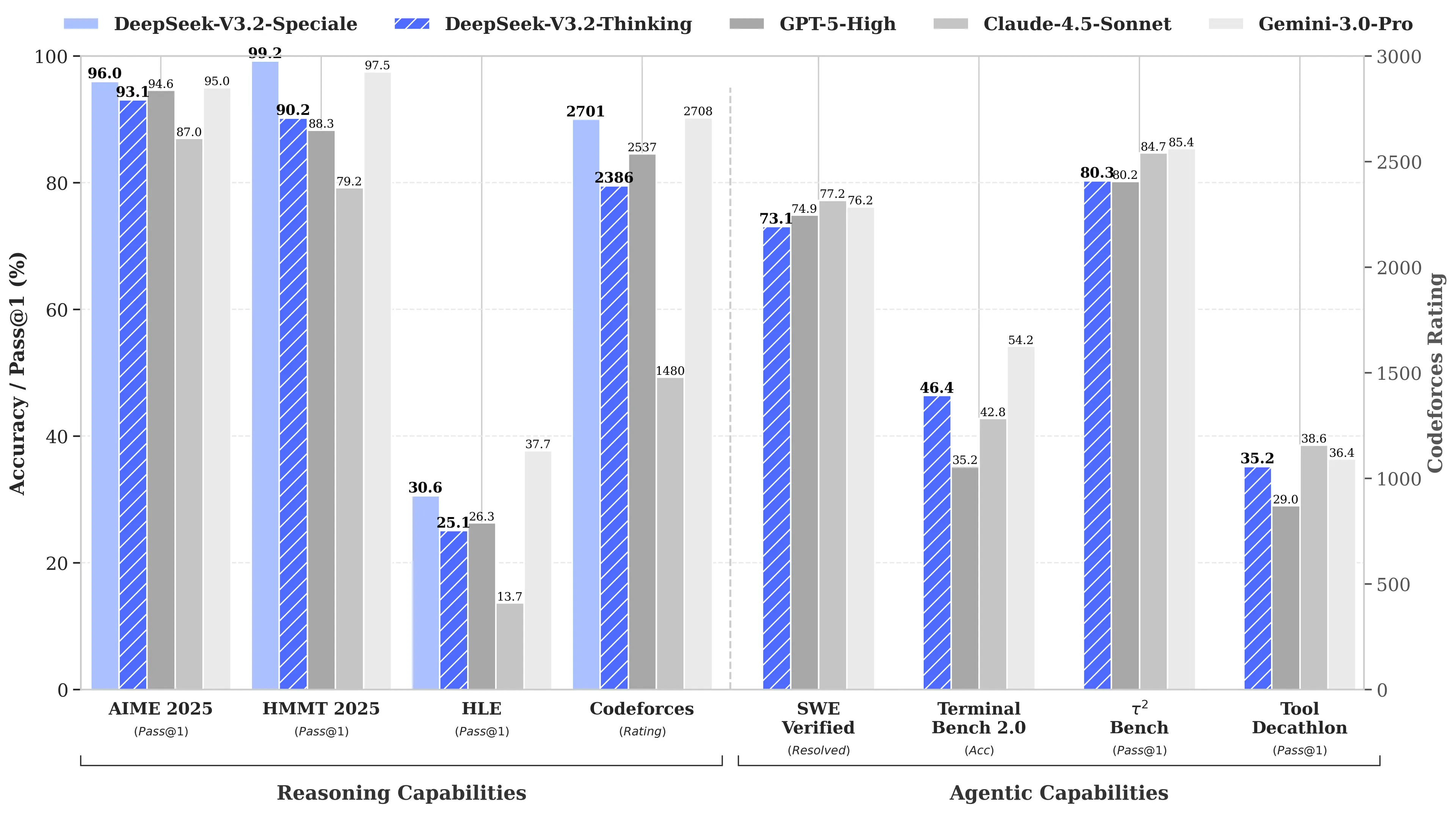
Bild: DeepSeek
Der Fokus von V4 auf Programmierung wäre eine strategische Neuausrichtung. Während R1 reines Reasoning—Logik, Mathematik, formale Beweise—betonte, ist V4 ein Hybridmodell (für Reasoning- und Nicht-Reasoning-Aufgaben), das den Markt für Unternehmenskunden ansprechen soll, bei denen hochpräzise Codegenerierung direkt in Umsatz umgewandelt wird.
Um die Dominanz zu behaupten, müsste V4 Claude Opus 4.5 übertreffen, das derzeit den SWE-bench Verified-Rekord bei 80,9 % hält. Aber wenn man sich an den bisherigen Launches von DeepSeek orientiert, ist das möglicherweise sogar mit allen Einschränkungen eines chinesischen KI-Labors erreichbar.
Das geheime Erfolgsrezept
Wenn die Gerüchte stimmen, wie kann dieses kleine Labor eine solche Leistung erbringen?
Die geheime Waffe des Unternehmens könnte in seinem Forschungsbericht vom 1. Januar liegen: Manifold-Constrained Hyper-Connections, oder mHC. Co-Autor ist Gründer Liang Wenfeng. Die neue Trainingsmethode adressiert ein grundlegendes Problem beim Skalieren großer Sprachmodelle—wie man die Kapazität eines Modells erweitern kann, ohne dass es während des Trainings instabil wird oder explodiert.
Traditionelle KI-Architekturen leiten alle Informationen durch einen einzigen engen Pfad. mHC erweitert diesen Pfad in mehrere Ströme, die Informationen austauschen können, ohne das Training zum Kollaps zu bringen.
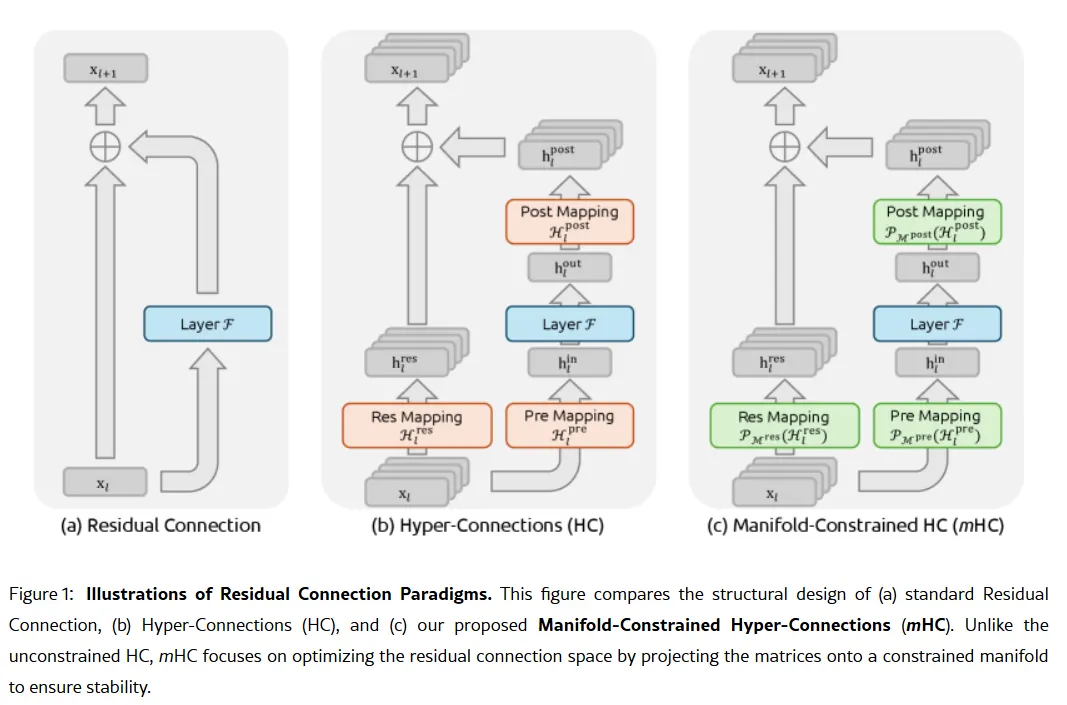
Bild: DeepSeek
Wei Sun, leitende Analystin für KI bei Counterpoint Research, bezeichnete mHC in einem Kommentar gegenüber Business Insider als „bahnbrechenden Durchbruch“. Die Technik, so Sun, zeigt, dass DeepSeek „Rechenengpässe umgehen und Sprünge in der Intelligenz freisetzen kann“, selbst bei begrenztem Zugang zu fortschrittlichen Chips aufgrund von US-Exportbeschränkungen. Lian Jye Su, Chefanalyst bei Omdia, bemerkte, dass die Bereitschaft von DeepSeek, seine Methoden zu veröffentlichen, ein „neues Selbstvertrauen in die chinesische KI-Industrie“ signalisiert. Der Open-Source-Ansatz des Unternehmens hat es bei Entwicklern beliebt gemacht, die darin das verkörperte, was OpenAI früher war, bevor es auf geschlossene Modelle und milliardenschwere Finanzierungsrunden umstellte.
Nicht jeder ist überzeugt. Einige Entwickler auf Reddit klagen, dass DeepSeek’s Reasoning-Modelle Rechenleistung bei einfachen Aufgaben verschwenden, während Kritiker argumentieren, dass die Benchmarks des Unternehmens die Realität nicht widerspiegeln. Ein Medium-Post mit dem Titel „DeepSeek ist Mist—Und ich höre auf, so zu tun, als wäre es anders“ ging im April 2025 viral, in dem die Modelle beschuldigt werden, „ boilerplate Unsinn mit Bugs“ und „Halluzinationen bei Bibliotheken“ zu produzieren.
DeepSeek trägt auch Ballast mit sich. Datenschutzbedenken haben das Unternehmen geplagt, einige Regierungen haben die native App von DeepSeek verboten. Die Verbindungen des Unternehmens zu China und Fragen zur Zensur in seinen Modellen sorgen für geopolitische Spannungen in den technischen Debatten.
Dennoch ist der Schwung unübersehbar. DeepSeek ist in Asien weit verbreitet, und wenn V4 seine Programmierversprechen einhält, könnte die Akzeptanz im Unternehmensektor im Westen folgen.
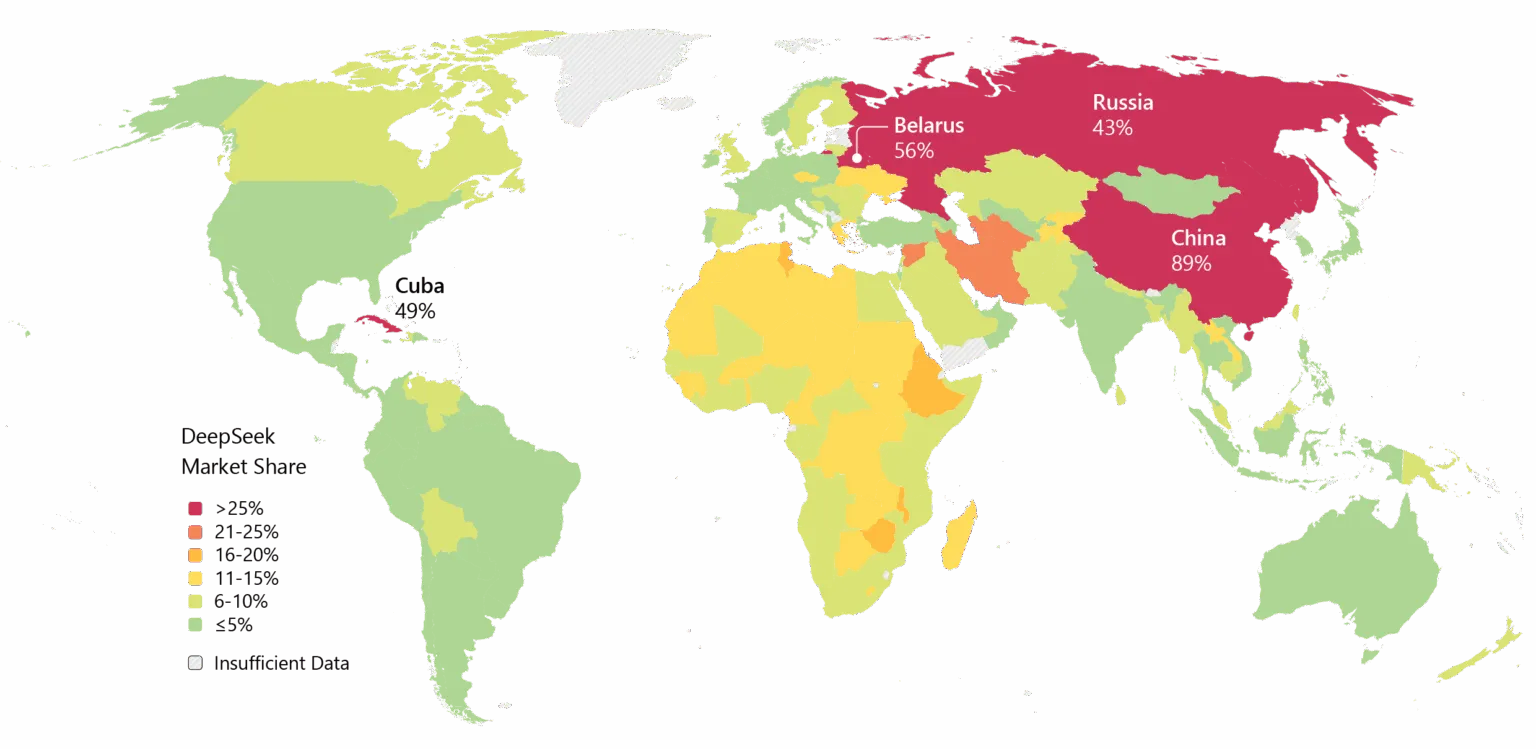
Bild: Microsoft
Auch der Zeitpunkt spielt eine Rolle. Laut Reuters hatte DeepSeek ursprünglich geplant, sein R2-Modell im Mai 2025 zu veröffentlichen, verlängerte aber die Frist, nachdem Gründer Liang mit der Leistung unzufrieden war. Jetzt, mit V4, das angeblich im Februar erscheinen soll, und R2 möglicherweise im August, bewegt sich das Unternehmen in einem Tempo, das Dringlichkeit—oder Selbstvertrauen—vermuten lässt. Vielleicht beides.