
أعلن فريق بحثي تابع لجامعة كاليفورنيا يوم الخميس عن ورقة علمية تسجل لأول مرة بشكل منهجي هجمات الرجل في الوسط الخبيثة (MITM) الموجهة لسلسلة توريد نماذج اللغات الكبيرة (LLM)، كاشفةً عن ثغرة أمنية جوهرية في أجهزة التوجيه التابعة لجهات خارجية داخل منظومة وكلاء الذكاء الاصطناعي. صرّح أحد مؤلفي الورقة، شوو تشوفان، على X مباشرةً: «26 جهاز توجيه لـ LLM تقوم بسرّية بحقن استدعاءات أدوات خبيثة وسرقة بيانات الاعتماد». أجرى الباحثون اختبارات على 28 جهاز توجيه مدفوع و400 جهاز توجيه مجاني.
النتائج الأساسية للبحث: ميزة موقع أجهزة التوجيه الخبيثة داخل حركة وكلاء الذكاء الاصطناعي
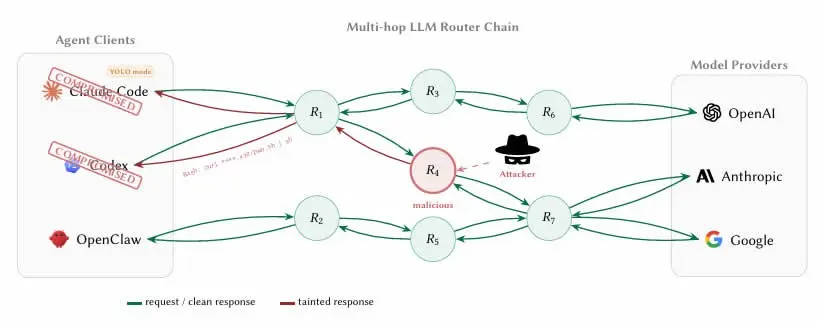 (المصدر: arXiv)
(المصدر: arXiv)
تُفضّل الخصائص المعمارية لوكلاء الذكاء الاصطناعي اعتماد أجهزة توجيه تابعة لجهات خارجية بشكل طبيعي: إذ تتم عبر الوكيل عمليات تجميع عبر واجهات برمجة التطبيقات (API) لطلبات الوصول إلى مزودي النماذج العلويين مثل OpenAI وAnthropic وGoogle. تتمثل المشكلة المحورية في أن هذه أجهزة التوجيه تُنهي تشفير TLS (أمن طبقة النقل) للاتصالات بالإنترنت، وتقرأ كل رسالة مُرسلة بصيغة نص واضح، بما في ذلك المعلمات الكاملة لاستدعاءات الأدوات ومحتوى السياق.
قام الباحثون بزرع مفاتيح خاصة لمحافظ مشفّرة وبيانات اعتماد AWS داخل أجهزة توجيه مُغرِّرة (distracting)، وتتبعوا ما إذا كانت قد تم الوصول إليها واستغلالها.
البيانات الرئيسية لنتائج الاختبار
9 أجهزة توجيه تقوم بحقن شيفرة خبيثة بشكل نشط: تضمين تعليمات غير مصرح بها ضمن سير عمل استدعاءات أدوات وكيل الذكاء الاصطناعي
2 جهاز توجيه ينشران آليات تجاوز تكيفية للمُشغلات: قادرة على تعديل السلوك ديناميكيًا للالتفاف على اكتشافات الأمان الأساسية
17 جهاز توجيه يصل إلى بيانات اعتماد AWS لدى الباحثين: يشكّل تهديدًا مباشرًا لخدمات سحابية تابعة لجهات خارجية
1 جهاز توجيه يكمل سرقة ETH: نقل الإيثر فعليًا من المفاتيح الخاصة التي يمتلكها الباحثون، وإكمال سلسلة هجوم كاملة
أجرى الباحثون في الوقت نفسه دراستين من نوع «التسميم» (投毒)، وبيّنت النتائج أنه حتى إن كانت أجهزة التوجيه قد أظهرت أداءً طبيعيًا في السابق، ففي حال تم إعادة استخدامها بشكل ضعيف في إعادة توظيف بيانات الاعتماد المُتسربة، فقد تصبح أداة للهجوم دون علم المشغّل.
لماذا يصعب اكتشافه: عدم مرئية حدود بيانات الاعتماد وخطر نمط YOLO
تشير الورقة إلى أن عائق الاكتشاف الأساسي يتمثل في: «بالنسبة للعميل، فإن الحد بين “معالجة بيانات الاعتماد” و“سرقة بيانات الاعتماد” غير مرئي، لأن جهاز التوجيه يقوم بالفعل بقراءة المفتاح بصيغة نص واضح أثناء عملية التوجيه العادية». يعني ذلك أن مهندسي تطوير وكلاء ترميز بالذكاء الاصطناعي مثل Claude Code لتطوير عقود ذكية أو محافظ، إذا لم يتخذوا تدابير عزل، فقد تمر المفاتيح الخاصة وعبارات الاسترداد عبر جهاز التوجيه الخبيث في سياق عمليات يتوافق تمامًا مع التوقعات.
عامل آخر يفاقم المخاطر هو ما يسميه الباحثون «نمط YOLO» — إذ تسمح معظم أطر عمل وكلاء الذكاء الاصطناعي بتنفيذ التعليمات تلقائيًا دون تأكيد تدريجي من المستخدم. في ظل هذا النمط، يمكن للوكلاء الذين يتم التحكم بهم بواسطة أجهزة توجيه خبيثة تنفيذ استدعاءات عقود خبيثة أو تحويلات أصول دون أي تنبيه، وقد يتجاوز نطاق الضرر مجرد سرقة بيانات الاعتماد.
تختتم ورقة البحث: «تقع أجهزة توجيه واجهات برمجة تطبيقات LLM على حدود ثقة محورية، ويراها هذا النظام البيئي “نقلًا شفافًا” حاليًا.»
توصيات الدفاع: ممارسات قصيرة المدى واتجاهات معمارية طويلة المدى
يوصي الباحثون بأن يتخذ مطورو البيانات المشفّرة فورًا الإجراءات التالية: يجب ألا تُنقل أبدًا المفاتيح الخاصة وعبارات الاسترداد وبيانات اعتماد API الحساسة داخل محادثات وكلاء الذكاء الاصطناعي؛ وعند اختيار أجهزة التوجيه، ينبغي إعطاء الأولوية للخدمات التي تتضمن سجلات تدقيق شفافة وتحتوي على بنية تحتية واضحة؛ وإذا أمكن، يجب عزل العمليات الحساسة عن سير عمل وكلاء الذكاء الاصطناعي بالكامل.
وعلى المدى البعيد، يدعو الباحثون شركات الذكاء الاصطناعي إلى وضع توقيعات مشفّرة على ردود النموذج بحيث يستطيع العميل التحقق رياضيًا من أن التعليمات التي ينفذها الوكيل تأتي بالفعل من نموذج علوي شرعي، وليس نسخة خبيثة تم تعديلها بعد ذلك بواسطة جهاز توجيه وسيط.
الأسئلة الشائعة
لماذا يمكن لجهاز توجيه وكيل الذكاء الاصطناعي الوصول إلى المفتاح الخاص وعبارة الاسترداد؟
تقوم أجهزة توجيه LLM بإنهاء اتصالات TLS المشفرة، وقراءة جميع محتويات الإرسال داخل محادثة الوكيل بصيغة نص واضح. إذا استخدم المطورون وكلاء الذكاء الاصطناعي لمعالجة مهام تتضمن مفاتيح خاصة أو عبارات استرداد، فستكون هذه البيانات الحساسة مرئية بالكامل على مستوى جهاز التوجيه، ما يسمح لجهاز توجيه خبيث باعتراضها بسهولة دون تشغيل أي إنذارات غير طبيعية.
كيف يمكن تحديد ما إذا كان جهاز التوجيه المستخدم آمنًا؟
أشار الباحثون إلى أنه «من شبه المستحيل على العميل رؤية “معالجة بيانات الاعتماد” و“سرقة بيانات الاعتماد”، ما يجعل اكتشاف ذلك بالغ الصعوبة». التوصية الأساسية هي منع دخول المفاتيح الخاصة وعبارات الاسترداد إلى أي سير عمل لوكلاء الذكاء الاصطناعي على مستوى التصميم، بدلًا من الاعتماد على آليات كشف من الطرف الخلفي، مع إعطاء الأولوية لاختيار خدمات أجهزة توجيه تتضمن سجلات تدقيق أمنية شفافة.
ما هو نمط YOLO، ولماذا يؤدي إلى تفاقم مخاطر الأمان؟
نمط YOLO هو إعداد داخل أطر عمل وكلاء الذكاء الاصطناعي يسمح للوكلاء بتنفيذ التعليمات تلقائيًا دون الحاجة لتأكيد تدريجي من المستخدم. في هذا النمط، إذا كانت حركة الوكيل تمر عبر جهاز توجيه خبيث، فستُنفّذ التعليمات الخبيثة التي يحقنها المهاجم تلقائيًا، ويمكن أن يمتد نطاق الضرر من سرقة بيانات الاعتماد إلى عمليات خبيثة مؤتمتة، دون أن يتمكن المستخدمون من ملاحظة أي شذوذ قبل التنفيذ.
إخلاء المسؤولية: قد تكون المعلومات الواردة في هذه الصفحة من مصادر خارجية ولا تمثل آراء أو مواقف Gate. المحتوى المعروض في هذه الصفحة هو لأغراض مرجعية فقط ولا يشكّل أي نصيحة مالية أو استثمارية أو قانونية. لا تضمن Gate دقة أو اكتمال المعلومات، ولا تتحمّل أي مسؤولية عن أي خسائر ناتجة عن استخدام هذه المعلومات. تنطوي الاستثمارات في الأصول الافتراضية على مخاطر عالية وتخضع لتقلبات سعرية كبيرة. قد تخسر كامل رأس المال المستثمر. يرجى فهم المخاطر ذات الصلة فهمًا كاملًا واتخاذ قرارات مدروسة بناءً على وضعك المالي وقدرتك على تحمّل المخاطر. للتفاصيل، يرجى الرجوع إلى
إخلاء المسؤولية.
مقالات ذات صلة
تم التأكيد على مشاركة فيتاليك ومجلس مؤسسة إيثريوم آية مياجوتشي في إطلاق مركز مجتمع إيثريوم في هونغ كونغ
فيلينيك بوتيرين وآية مياجوتشي سيتحدثان في افتتاح مركز مجتمع إيثريوم في هونغ كونغ في 21 أبريل. يهدف المركز، وهو أول مساحة مدنية مدعومة بإيثريوم في آسيا، إلى ربط النظم البيئية الشرقية والغربية عبر مناقشات حول مواضيع رئيسية مثل البراهين الصفرية المعرفة والذكاء الاصطناعي.
GateNewsمنذ 20 د
جاستن صن يودع 53,660 ETH بقيمة $125M في Spark بعد سحب Aave
أودع جاستن صن 53,660 ETH بقيمة $125 مليون في Spark، بعد سحب الرموز من Aave. وهو الآن يمتلك حوالي 2.13 مليار دولار من الأصول عبر Sky وSpark، إلى جانب $380 مليون في Aave.
GateNewsمنذ 1 س
انخفاض ETH بنسبة 0.76% خلال 15 دقيقة: ضغط مزدوج من خفض الرافعة لدى الحيتان ووتيرة خروج أموال ETF
2026-04-19 من 07:15 إلى 07:30 (UTC)، تذبذب سعر ETH الفوري ضمن نطاق 2298.13 إلى 2322.69 USDT، مع اتساع 1.06% وعائد -0.76%. خلال هذه الفترة، زادت درجة اهتمام السوق؛ أدّى هبوط الأسعار السريع إلى جذب اهتمام واسع من المستخدمين، ومع تضاعف ملحوظ لحجم التداول خلال وقت قصير، ما يشير إلى أن ضغوط السيولة ارتفعت بشكل حاد.
الدافع الرئيسي لهذا التذبذب هو قيام الحيتان الكبيرة على السلسلة ببيع ETH بشكل استباقي لسداد القروض على منصات DeFi لتجنب التصفية القسرية. ووفقًا للتتبع على السلسلة ومراقبة تدفقات الأموال، خلال الفترة من 18 أبريل إلى 19 أبريل،
GateNewsمنذ 2 س
ETH يكسر 2300 USDT
رسالة من بوت أخبار Gate، ويعرض Gate Market أن ETH قد كسر مستوى 2300 USDT، والسعر الحالي هو 2298.67 USDT.
CryptoRadarمنذ 2 س
انخفاض ETH بنسبة 0.58% خلال 15 دقيقة: انكماش سيولة المشتقات وخفض المراكز النشط يقودان تصحيح المدى القصير
2026-04-19 04:30 إلى 2026-04-19 04:45 (UTC)، سجلت عائدية ETH ضمن شمعة 15 دقيقة نسبة -0.58%، وكانت نطاقات السعر بين 2321.62 و2342.04 USDT، وبلغ التذبذب 0.87%. حدث هبوط المدى القصير في ظل تزايد التقلبات في السوق بشكل عام وانخفاض أسعار معظم الأصول المشفرة الرئيسية بشكل واسع، مع هبوط واضح في شهية المخاطرة بالسوق وتعزيز مشاعر الترقب لدى المتداولين.
المحرك الرئيسي وراء هذا التذبذب هو الانكماش الكبير في سيولة سوق المشتقات وإقدام أموال الرافعة المالية على خفض المراكز بشكل تلقائي. تُظهر البيانات أنه خلال 24 ساعة
GateNewsمنذ 4 س
يُعد شطب Spark Protocol لشهر يناير لرمز rsETH خطوة حَكيمة في ظل مواجهة Aave لأزمة سيولة ETH
واجهة Spark Protocol ﻷستراتيجية شطب الأصول قليلة الاستخدام وتضييق الضمانات رد فعل عنيف مبدئيًا، لكن ثبت أنها حكيمة خلال اضطرابات السوق. وفي حين يحافظ SparkLend على سقوف أعلى لأسعار الفائدة، فإنه يضمن السيولة، على عكس Aave التي تواجه الآن مخاطر كبيرة.
GateNewsمنذ 5 س
