X热文》重来一次我会这样入门量化交易:18个月进入初级年薪30万美元门槛
動區BlockTempo
量化(Quant)交易员 gemchange_ltd 在 X 上发布了一篇长文,列出他“如果重来一次,会按什么顺序学习”的完整路线图,从概率论到随机微积分,五个数学关卡,18 个月就能从什么都不会到真正入门量化交易。本文源自他在 X 上发布的热门文章《How I’d Become a Quant If I Had to Start Over Tomorrow》,由翻书 Flip 编译和重新整理。
(前情提要:不靠佣金、不晒单,一名交易员只凭分析周期的常胜策略)
(背景补充:顶级加密女交易员万字生存笔记:别被“速成致富”毁掉)
本文目录
Toggle
- Part I:概率论,不确定性的语言
- Part II:统计学——学会聆听数据
- Part III:线性代数——驱动一切的机器
- Part IV:微积分与优化——变化的语言
- Part V:随机微积分——真正的 Quant 门槛
- Polymarket
- LMSR 如何为信念定价
- 量化交易职业版图:四种原型
- 工具箱与书单
- 三件作者希望自己早点知道的事
编译声明:本文不构成投资建议,市场有风险,请做好自己的研究。
先说几个数字:2025 年,顶尖机构的应届 Quant 年薪总包在 30 万至 50 万美元之间。金融业 AI/ML 招聘年增 88%。这条路,有没有地图?
这篇文章,是作者希望自己起步时有人能递给他的东西。学习路线按照“你应该学的顺序”排好了,每个概念都建立在前一个之上,就像电玩游戏一样,你没办法跳关。但如果你真的认真做,不是去 YouTube 上看什么无聊的金融入门影片(那只是浪费时间),而是真解题、动手做——大概 18 个月,你就能从什么都不懂,变成真的懂一些东西。
把所有你以为知道的交易知识先放旁边。大多数人以为量化交易是在选股、对特斯拉有看法、预测财报。其实不是。Quant 交易是数学。你做的是统计关系、定价低效率,以及那些“市场是被会犯系统性错误的人在跑的复杂系统”这个事实所带来的结构性优势。
Part I:概率论,不确定性的语言
量化金融的每件事,最后都可以简化成一个问题:胜率多少?胜率站在我这边吗?
这就是概率。如果你对概率没有深刻的理解,这篇文章后面的东西对你来说都没有意义。
条件概率:Quant 的思考方式
一般人用绝对值思考:这件事是真的还是假的。Quant 用条件思考:根据我现在知道的,这件事有多大的概率?
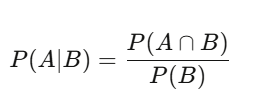
P(A|B) = P(A∩B) / P(B)——给定 B 发生,A 的概率等于两者同时发生的概率除以 B 的概率。听起来简单,但影响很深远。一支股票有 60% 的天数是上涨的——这是基础概率。但在成交量高于平均的日子,上涨概率是 75%。这个条件概率才是有意义的信息;原本那个 60% 反而充满杂讯。
贝叶斯定理:即时更新你的判断
后验 = (在假说成立的情况下,看到这笔资料的概率)× 先验 ÷ (在任何假说下,看到这笔资料的总概率)。在实作中,你用蒙特卡洛采样来计算。逻辑是一样的:贝叶斯是你在面对新信息时即时调整判断的方式。模型说一支股票应该值 50 美元,财报出来,营收比预期高 3%——贝叶斯后验向上移动。更新最快、更新最准的人,赢得报酬。
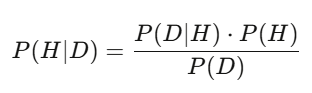
期望值与方差:你最好的两个朋友
期望值是你的信念强度;方差是你的风险。如果你的策略有正期望值,而且你能撑过方差带来的震荡,你很可能会赚钱。
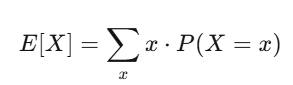
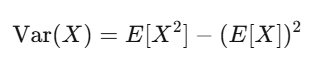
Level 1 作业(每天 2 小时,3-4 周)
-
读:Blitzstein & Hwang,《Introduction to Probability》(哈佛免费 PDF),把第 1-6 章每道题目都做一遍
-
写程序:模拟 10,000 次抛硬币,用可视化验证大数定律
-
写程序:自己实现一个贝叶斯更新器,输入先验和似然,输出后验
import numpy as np import matplotlib.pyplot as plt
大数定律:执行平均收敛到真实概率
np.random.seed(42) flips = np.random.choice([0, 1], size=10000, p=[0.5, 0.5]) running_avg = np.cumsum(flips) / np.arange(1, 10001)
plt.figure(figsize=(10, 4)) plt.plot(running_avg, linewidth=0.7) plt.axhline(y=0.5, color=‘r’, linestyle=‘–’, label=‘真实概率’) plt.xlabel(‘抛掷次数’) plt.ylabel(‘执行平均’) plt.title(‘大数定律实际演示’) plt.legend() plt.savefig(‘lln.png’, dpi=150) print(f"10,000 次后: {running_avg[-1]:.4f}(真实: 0.5000)")
Part II:统计学——学会聆听数据
学会说概率这个语言之后,你要学的是从数据中听出什么。统计学教给你的第一课是:大多数看起来有意义的发现,其实只是杂讯。

假说检验:你的滤杂讯侦测器
你建了一个模型,回测年化报酬率 15%。这是真的吗?设立虚无假说 H₀:「这个策略的期望报酬是零」,计算检验统计量,算出 p 值。但注意:如果你测试 1,000 个随机策略,纯靠运气,就有 50 个 p 值会低于 0.05。这是多重比较问题。解法是 Bonferroni 修正(显著水准除以测试次数),或 Benjamini-Hochberg 控制伪发现率。每个初学者都大幅高估自己找到了什么有意义的东西。你前 10 个策略全部都是杂讯。现在就接受这件事,帮自己省很多钱。
回归分析:拆解报酬
线性回归 y=Xβ+ε 是金融业的主力工具。你把策略报酬对已知的风险因子做回归,截距 α 就是你的超额报酬——那个无法被已知因子解释的部分。
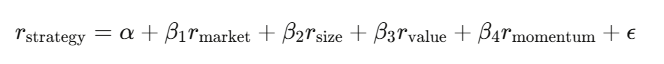
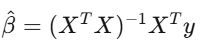
如果在控制各因子后 α 为零,你所谓的“优势”只是伪装过的市场暴露。要用 Newey-West 标准误,因为金融数据有自相关和异质变异,用普通最小平方法的标准误,就像开着裂掉的挡风玻璃在高速公路上行驶。
最大似然估计(MLE)
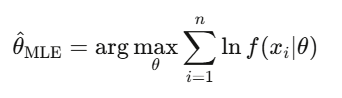
这是金融业校正每个模型的方法,不管是拟合 GARCH 波动率模型、估计跳跃扩散参数,还是把期权定价校正到市场报价。当有人说“校准”一个模型,几乎都是在说 MLE。
Level 2 作业(4-5 周)
- 读:Wasserman,《All of Statistics》,第 1-13 章
- 下载真实股票报酬(yfinance),测试正态性(一定会失败),用 MLE 拟合 t 分布,比对结果
- 用 statsmodels 对股票组合跑 Fama-French 三因子回归
- 实作排列检验:把日期打乱 10,000 次,把打乱后的绩效和真实绩效比较
Part III:线性代数——驱动一切的机器
线性代数听起来很无聊,但它是驱动一切的机器:投资组合建构、主成分分析、神经网络、协方差估计、因子模型。不会矩阵,就做不了 Quant。

矩阵思维
协方差矩阵 Σ 捕捉了每一个资产相对于其他每个资产的移动方式。对于 500 支股票,Σ 是 500×500 的矩阵,有 125,250 个独特的值。组合变异数可以简化成一个表达式:w’Σw,这个二次型是 Markowitz 投资组合理论、风险管理、所有东西的核心。
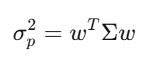
特征值:真正重要的东西
看 500 支股票的宇宙,前 5 个特征向量解释了 70% 的总变异。其他的都是杂讯。第一次用特征值分解,世界就变了:这是降维,也是因子投资的基础。
Level 3 作业(4-6 周)
-
看:Gilbert Strang 的 MIT 18.06 线性代数课程,全部,不能跳过
-
读:Strang,《Introduction to Linear Algebra》,把题目做完
-
对 S&P 500 报酬做 PCA,画特征值频谱,找出前三个主成分
-
从头实现 Markowitz 均值方差优化
import numpy as np import cvxpy as cp
np.random.seed(42) n_assets = 10 mu = np.random.uniform(0.04, 0.15, n_assets) A = np.random.randn(n_assets, n_assets) * 0.1 cov = A @ A.T + np.eye(n_assets) * 0.01
w = cp.Variable(n_assets) objective = cp.Minimize(cp.quad_form(w, cov)) constraints = [ mu @ w >= 0.08, # 最低报酬要求 cp.sum(w) == 1, # 全部投入 w >= -0.1, # 最多 10% 放空 w <= 0.3 # 最多 30% 做多 ]
prob = cp.Problem(objective, constraints) prob.solve()
ret = mu @ w.value vol = np.sqrt(w.value @ cov @ w.value) sharpe = (ret - 0.03) / vol
print(f"组合报酬: {ret:.4f}“) print(f"组合波动: {vol:.4f}”) print(f"夏普比率: {sharpe:.4f}")
Part IV:微积分与优化——变化的语言
微积分是描述变化的语言。在金融里,什么都在变:价格、波动率、相关性,整个概率分布每秒都在移动。微积分描述并利用这些变化。导数出现在每个神经网络的反向传播和每个期权希腊字母计算中。
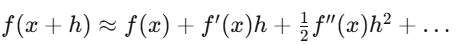
泰勒展开式是 Delta 避险的一阶近似,Gamma 避险加入二阶修正。Itô 微积分和普通微积分不同,正是因为随机过程的二阶泰勒项不会消失。
Level 4 作业(4-5 周)
- 读:Boyd & Vandenberghe,《凸优化》(史丹佛免费 PDF),第 1-5 章
- 从头实现梯度下降,最小化 Rosenbrock 函数
- 用 cvxpy 解一个含交易成本约束的投资组合优化问题
Part V:随机微积分——真正的 Quant 门槛
学随机微积分之前,你只是个喜欢金融的数据科学家。学完之后,你才算是 Quant。这是你学会在连续时间里建模随机性、从第一原理推导 Black-Scholes 方程式,以及理解为什么上兆美元的衍生品市场是这样运作的地方。

布朗运动:将随机性形式化
布朗运动(维纳过程)W_t 是连续时间的随机漫步。最关键的洞察——后面一切都依赖于此——是 dW_t 的“大小”是 √dt,意思是 (dW_t)² = dt。听起来像技术细节,但这是量化金融里最重要的一个事实。
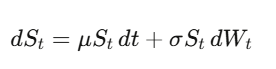
Itô 引理
在普通微积分里,你做泰勒展开,(dx)² 小到可以省略。但当 x 是随机过程,(dW_t)² = dt 是一阶项,你省略不了。Itô 引理:df = (∂f/∂t + μ∂f/∂x + ½σ²∂²f/∂x²)dt + σ∂f/∂x dW_t。把这个应用到期权价格,你就得到了 Black-Scholes。
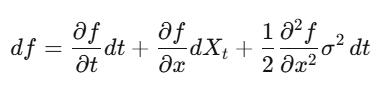
从头推导 Black-Scholes
Step 1:设 V(S,t) 是期权价格,对其用 Itô 引理。
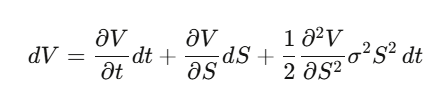
Step 2:建立 Delta 避险投资组合 Π = V − (∂V/∂S)·S,计算 dΠ——dW_t 项完美消掉,这个组合在局部是无风险的。
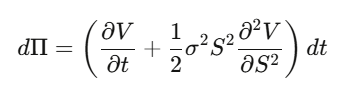
Step 3:无风险投资组合必须以无风险利率增值。
Step 4:代入整理,得到 Black-Scholes 偏微分方程式。
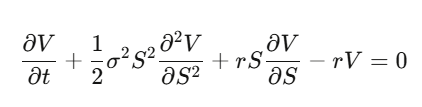
注意发生了什么事:漂移率 μ 消失了。期权的价格跟股票的预期报酬无关,跟风险偏好也无关。你可以把每个人都当成风险中性来为期权定价。第一次真正理解这件事,真的会让人脑袋打结。
对于一个履约价为 K、到期日为 T 的欧式买权,解这个偏微分方程(PDE)可以得到:
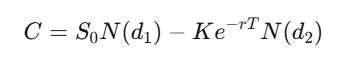
where d_1=
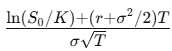
d_2=
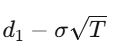
希腊字母
-
Delta Δ:每 1 美元股价移动,期权移动多少,也就是你的避险比率
-
Gamma Γ:Delta 变化的速度,你的凸性暴露
-
Theta Θ:时间价值损耗,长仓通常是负值
-
Vega V:对波动率的敏感度,大多数衍生品的钱在这里赚
-
Rho ρ:对利率的敏感度
import numpy as np from scipy.stats import norm
def black_scholes(S, K, T, r, sigma, option_type=‘call’): d1 = (np.log(S/K) + (r + sigma**2/2)T) / (sigmanp.sqrt(T)) d2 = d1 - sigmanp.sqrt(T) if option_type == ‘call’: return Snorm.cdf(d1) - Knp.exp(-rT)norm.cdf(d2) else: return Knp.exp(-r*T)norm.cdf(-d2) - Snorm.cdf(-d1)
def monte_carlo_option(S0, K, T, r, sigma, n_sims=500_000): Z = np.random.standard_normal(n_sims) ST = S0 * np.exp((r - sigma**2/2)T + sigmanp.sqrt(T)Z) payoffs = np.maximum(ST - K, 0) price = np.exp(-rT) * np.mean(payoffs) stderr = np.exp(-r*T) * np.std(payoffs) / np.sqrt(n_sims) return price, stderr
S, K, T, r, sigma = 100, 105, 1.0, 0.05, 0.2 bs = black_scholes(S, K, T, r, sigma) mc, err = monte_carlo_option(S, K, T, r, sigma) print(f"Black-Scholes: ${bs:.4f}“) print(f"Monte Carlo: ${mc:.4f} ± {err:.4f}”)
Level 5 作业(6-8 周,最难的一关)
- 读:Shreve,《Stochastic Calculus for Finance II》,金标标准
- 替代选项:Arguin,《A First Course in Stochastic Calculus》,新一点,更容易入门
- 自己推导:对 f(S) = ln(S) 用 Itô 引理,推出那个 -σ²/2
- 自己推导:完整的 Black-Scholes 方程式,从 Delta 避险论证开始
- 写程序:从头实现 Black-Scholes,和蒙特卡洛比较,验证收敛
Polymarket
这是目前世界上最有趣的市场,而其背后的数学把本文中的所有主题连接在一起:
概率(probability)、信息理论(information theory)、凸优化(convex optimization)、整数规划(integer programming)。
LMSR 如何为信念定价
对数市场评分规则(Logarithmic Market Scoring Rule,LMSR)
由 Robin Hanson 发明,用于驱动自动化的预测市场。
对于 n 个结果(outcomes),其成本函数为:
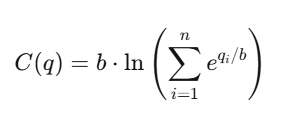
其中:
-
q_i 表示 结果 i 已经发行的未平仓份额(outstanding shares)
-
b 是 流动性参数(liquidity parameter)
结果 i 的价格为:
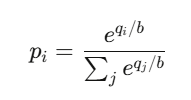
这其实就是 softmax 函数 ——
也就是 所有神经网络分类器(neural network classifiers)背后使用的函数。
其性质包括:
-
所有价格 加总永远等于 1
-
所有价格 永远落在 (0,1) 之间
-
市场 始终存在价格,等同于提供无限流动性
而 做市商(market maker)的最大损失
被限制在:b×ln(n)
(b×ln(n))
量化交易职业版图:四种原型
Quant Researcher(QR):在 PB 级数据里找规律,建预测模型,设计策略,需要博士级数学/统计/机器学习,或是大学阶段就特别突出的。在 Jane Street 这类机构,QR 手边有几万张 GPU。
Quant Developer/Engineer(QD):负责建造,交易平台、执行引擎、实时数据管道,让研究员的模型真的能跑起来交易。需要生产级别的 C++/Rust/Python 和低延迟系统。
Quant Trader(QT):决策者,管理资本、控制风险、做即时判断。薪资变异最大,顶尖年份可以到八位数。
Risk Quant:守门人,模型验证、VaR、压力测试、法规遵循,职业路径比较稳定,但天花板较低。新兴的 AI/ML Quant 角色(用深度学习产生信号)是成长最快的方向,2025 年招聘年增 88%。
薪资行情如下(美国顶尖机构,Jane Street、Citadel、HRT):
- 应届毕业生:$30 万至 $50 万+总包
- 中阶(3-7 年):$55 万至 $95 万
- 资深(8 年+):$100 万至 $300 万+
- 明星交易员/PM:$300 万至 $3000 万+
中型机构(Two Sigma、DE Shaw)应届毕业生约 $25 万至 $35 万总包。Jane Street 的员工平均薪酬在 2025 上半年达到每年 140 万美元,这个是平均值。
面试流程:简历筛选 → 在线测试(心算用 Zetamac,目标 50 分以上,逻辑题)→ 电话面试(概率问题、赌博游戏)→ Superday(3-5 轮连续面试,模拟交易、代码、白板推导)。Jane Street 故意出难题自己解不完的题,考的是你怎么利用提示和跟人协作。他们近期实习生班超过三分之二读信息工程,三分之一读数学,金融知识通常不要求。
面试准备首推 Xinfeng Zhou 的《Green Book》(量化金融面试实战指南,200 道以上真实题目),搭配 QuantGuide.io(量化版 LeetCode)和 Brainstellar 练习。
工具箱与书单
Python 技术栈:数据处理用 pandas/polars(Polars 在大型数据集上快 10-50 倍),数值计算用 numpy/scipy,表格型机器学习用 xgboost/lightgbm,深度学习用 pytorch,优化用 cvxpy,衍生品用 QuantLib,统计用 statsmodels,回测用 NautilusTrader 或 vectorbt。
免费数据来源:yfinance、Finnhub(每分钟 60 次请求)、Alpha Vantage。中阶用 Polygon.io(每月 $199,延迟低于 20ms)。企业级是 Bloomberg Terminal(每年约 $32,000)。
书单(按顺序)
- 数学基础:Blitzstein & Hwang《概率论》→ Strang《线性代数》→ Wasserman《All of Statistics》→ Boyd & Vandenberghe《凸优化》→ Shreve《随机微积分 I & II》
- 量化金融:Hull《期权、期货与其他衍生品》→ Natenberg《期权波动率与定价》→ López de Prado《金融机器学习进阶》→ Ernest Chan《量化交易》→ Zuckerman《解开市场谜题的人》
- 面试:Zhou《Green Book》→ Crack《Heard on the Street》→ Joshi《Quant 面试题》
- 竞赛:Jane Street Kaggle(10 万美元奖金)、WorldQuant BRAIN(超过 10 万用户,付钱买 alpha 信号)、Citadel Datathon(快速通道到正职)
三件作者希望自己早点知道的事
**估计误差才是真正的敌人。**Full Kelly 下注、无约束 Markowitz、特征数量太多的机器学习模型——失败的原因都一样:过度拟合参数估计中的杂讯。数学在真实参数下完美运作。你从来没有真实参数。理论和实践之间的差距,永远都是估计误差,最好的 Quant 是那些真正尊重这件事的人。
**工具已经民主化,但判断力没有。**任何人都能取得 QuantLib、Polygon.io 和 PyTorch。技术是必要条件,但不是充分条件。优势存在于独特的数据、独特的模型,或是独特的执行能力,不在于更好的 pip install。
**数学是护城河。**AI 可以写代码、提策略。但能够推导出为什么 Itô 引理有那个多出来的项、能够证明在风险中性测度下折现价格是鞅、能够知道在组合套利问题中凸松弛是紧的还是松的——这种数学流畅度,才是区分“建立优势的 Quant”和“借用别人优势的 Quant”的东西。借来的优势有到期日。

免责声明:本页面信息可能来自第三方,不代表 Gate 的观点或意见。页面显示的内容仅供参考,不构成任何财务、投资或法律建议。Gate 对信息的准确性、完整性不作保证,对因使用本信息而产生的任何损失不承担责任。虚拟资产投资属高风险行为,价格波动剧烈,您可能损失全部投资本金。请充分了解相关风险,并根据自身财务状况和风险承受能力谨慎决策。具体内容详见声明。
评论
0/400
暂无评论