การเทรดเชิงปริมาณ (Quant) โดย gemchange_ltd ได้เผยแพร่บทความยาวบน X ซึ่งเป็นเส้นทางการเรียนรู้แบบสมบูรณ์ว่า “ถ้าทำใหม่อีกครั้ง จะเรียนอะไรเป็นลำดับ” ตั้งแต่ทฤษฎีความน่าจะเป็น ไปจนถึงแคลคูลัสเชิงสัญญาณแบบสุ่ม ห้าหลักสูตรคณิตศาสตร์ ภายใน 18 เดือน คุณจะสามารถเปลี่ยนจากไม่รู้อะไรเลย ไปสู่การเข้าใจเชิงลึกของการเทรดเชิงปริมาณ บทความนี้เป็นการเรียบเรียงและแปลจากบทความยอดนิยมบน X ชื่อ “How I’d Become a Quant If I Had to Start Over Tomorrow” โดย Flip
(สรุปเนื้อหาเบื้องต้น: ไม่พึ่งค่าคอมมิชชั่น ไม่โพสต์คำสั่งล่วงหน้า เทรดเดอร์ที่ใช้วิเคราะห์รอบวัฏจักรกลยุทธ์ชนะบ่อย)
(ข้อมูลเสริม: บันทึกความอยู่รอดของเทรดเดอร์หญิงชั้นนำในวงการคริปโต: อย่าให้ “รวยทางลัด” ทำลายตัวเอง)
สารบัญบทความ
Toggle
- Part I: ทฤษฎีความน่าจะเป็น ภาษาแห่งความไม่แน่นอน
- Part II: สถิติ—เรียนรู้การฟังข้อมูล
- Part III: พีชคณิตเชิงเส้น—เครื่องจักรที่ขับเคลื่อนทุกอย่าง
- Part IV: แคลคูลัสและการปรับแต่ง—ภาษาของการเปลี่ยนแปลง
- Part V: แคลคูลัสเชิงสัญญาณแบบสุ่ม—ขีดจำกัดที่แท้จริงของ Quant
- Polymarket
- LMSR ทำอย่างไรให้ราคาความเชื่อมั่น
- แผนเส้นทางอาชีพด้านการเทรดเชิงปริมาณ: สี่โปรไฟล์หลัก
- เครื่องมือและหนังสือแนะนำ
- สามสิ่งที่ผู้เขียนหวังว่าตนเองจะรู้เร็วกว่านี้
ประกาศการแปล: บทความนี้ไม่ใช่คำแนะนำการลงทุน ตลาดมีความเสี่ยง ควรศึกษาข้อมูลให้ดี
เริ่มจากตัวเลขกันก่อน: ในปี 2025 ค่าจ้างรวมของ Quant หน้าใหม่จากสถาบันชั้นนำอยู่ระหว่าง 300,000 ถึง 500,000 ดอลลาร์สหรัฐต่อปี อุตสาหกรรมการเงินด้าน AI/ML เพิ่มขึ้นปีละ 88% แล้วเส้นทางนี้ ไม่มีแผนที่ชัดเจนหรือ?
บทความนี้เป็นสิ่งที่ผู้เขียนอยากให้ตัวเองได้รับในตอนเริ่มต้น เรียงลำดับการเรียนรู้ตาม “ลำดับที่ควรเรียน” แต่ละแนวคิดสร้างขึ้นบนแนวคิดก่อนหน้า เหมือนเกมวิดีโอ คุณไม่สามารถข้ามด่านได้ แต่ถ้าทำจริงจัง ไม่ใช่แค่ดูวิดีโอเบื้องต้นบน YouTube (ซึ่งเปลืองเวลา) แต่ลงมือแก้โจทย์ ทำจริง—ประมาณ 18 เดือน คุณจะเปลี่ยนจากไม่รู้อะไรเลย ไปเป็นเข้าใจบางอย่างจริงจัง
อย่ามองข้ามความรู้ด้านการเทรดที่คุณคิดว่ารู้ไปก่อนหน้านี้ ส่วนใหญ่คนเข้าใจผิดว่าการเทรดเชิงปริมาณคือการเลือกหุ้น คิดว่าท็อปเทสล่า หรือทำนายงบการเงิน จริงๆ แล้ว Quant คือคณิตศาสตร์ คุณทำเรื่องความสัมพันธ์ทางสถิติ การตั้งราคาที่ไม่สมดุล และข้อเท็จจริงว่า “ตลาดเป็นระบบซับซ้อนที่คนทำผิดพลาดเป็นระบบ” ซึ่งสร้างความได้เปรียบเชิงโครงสร้าง
Part I: ทฤษฎีความน่าจะเป็น ภาษาแห่งความไม่แน่นอน
ทุกเรื่องในการเงินเชิงปริมาณ สุดท้ายสามารถลดลงเป็นคำถามง่ายๆ: อัตราชนะเท่าไหร่? ชนะในฝั่งของฉันไหม?
นั่นคือความน่าจะเป็น ถ้าคุณไม่เข้าใจความน่าจะเป็นอย่างลึกซึ้ง สิ่งที่ตามมาทั้งหมดในบทความนี้จะไม่มีความหมายสำหรับคุณ
ความน่าจะเป็นเงื่อนไข: วิธีคิดแบบ Quant
คนทั่วไปคิดแบบค่าคงที่: เรื่องนี้เป็นจริงหรือเท็จ Quant คิดแบบเงื่อนไข: จากสิ่งที่ฉันรู้ตอนนี้ โอกาสที่เรื่องนี้จะเป็นจริงเป็นเท่าไหร่?
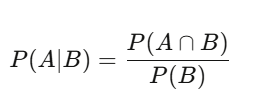
P(A|B) = P(A∩B) / P(B)—ให้ B เกิดขึ้นแล้ว โอกาสที่ A จะเกิดขึ้นคือความน่าจะเป็นร่วมของ A และ B หารด้วยความน่าจะเป็นของ B ฟังดูง่าย แต่ส่งผลลึกซึ้งมาก ตัวอย่างเช่น หุ้นมีวันที่ขึ้น 60% นี่คือความน่าจะเป็นพื้นฐาน แต่ในวันที่ปริมาณการซื้อขายสูงกว่าค่าเฉลี่ย โอกาสขึ้นเป็น 75% ความน่าจะเป็นเงื่อนไขนี้คือข้อมูลที่มีความหมายมากกว่า ค่าความน่าจะเป็น 60% เดิมกลายเป็นเสียงรบกวน
ทฤษฎีเบย์: อัปเดตการตัดสินใจแบบเรียลไทม์
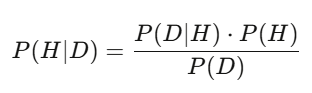
หลังการสันนิษฐาน = (ความน่าจะเป็นของข้อมูลนี้ภายใต้สมมติฐาน) × ความน่าจะเป็นก่อนหน้า ÷ (ความน่าจะเป็นของข้อมูลนี้ภายใต้ทุกสมมติฐาน) ในการใช้งานจริง ใช้การสุ่มตัวอย่างแบบมอนติคาร์โลเพื่อคำนวณ กลยุทธ์คือ เบย์อัปเดตเป็นระยะๆ เมื่อได้รับข้อมูลใหม่ โมเดลบอกว่า หุ้นควรมีมูลค่า 50 ดอลลาร์ หลังประกาศรายได้สูงกว่าคาด 3%—ความน่าจะเป็นหลังอัปเดตจะเพิ่มขึ้น คนที่อัปเดตเร็วและแม่นยำที่สุด จะได้ผลตอบแทนมากที่สุด
ค่าคาดหวังและความแปรปรวน: สองเพื่อนคู่ใจ
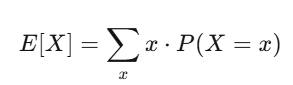
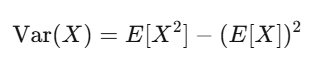
ค่าคาดหวังคือความเชื่อมั่นของคุณ; ความแปรปรวนคือความเสี่ยง ถ้ากลยุทธ์ของคุณมีค่าคาดหวังบวก และคุณสามารถรับมือกับความผันผวนได้ คุณมีโอกาสทำกำไรสูง
งานระดับ 1 (วันละ 2 ชม., 3-4 สัปดาห์)
- อ่าน: Blitzstein & Hwang, 《Introduction to Probability》 (PDF ฟรีจากฮาร์วาร์ด) ทำบทที่ 1-6 ให้ครบทุกโจทย์
- เขียนโปรแกรม: จำลองการโยนเหรียญ 10,000 ครั้ง ใช้ภาพประกอบเพื่อพิสูจน์กฎจำนวนมาก
- เขียนโปรแกรม: สร้างตัวอัปเดตเบย์เอง โดยรับค่าความน่าจะเป็นก่อนหน้าและความน่าจะเป็นของข้อมูล แล้วคำนวณค่าหลัง
import numpy as np
import matplotlib.pyplot as plt
# กฎจำนวนมาก: ค่าเฉลี่ยของการทดลองเข้าใกล้ความจริง
np.random.seed(42)
flips = np.random.choice([0, 1], size=10000, p=[0.5, 0.5])
running_avg = np.cumsum(flips) / np.arange(1, 10001)
plt.figure(figsize=(10, 4))
plt.plot(running_avg, linewidth=0.7)
plt.axhline(y=0.5, color='r', linestyle='--', label='ความน่าจะเป็นจริง')
plt.xlabel('จำนวนการโยนเหรียญ')
plt.ylabel('ค่าเฉลี่ยสะสม')
plt.title('การแสดงกฎจำนวนมาก')
plt.legend()
plt.savefig('lln.png', dpi=150)
print(f"หลัง 10,000 ครั้ง: {running_avg[-1]:.4f} (ความจริง: 0.5000)")
Part II: สถิติ—เรียนรู้การฟังข้อมูล
เมื่อเข้าใจภาษาแห่งความน่าจะเป็นแล้ว สิ่งต่อไปคือการฟังเสียงจากข้อมูล สถิติสอนให้รู้ว่า: การค้นพบที่ดูเหมือนสำคัญ ส่วนใหญ่เป็นเสียงรบกวน

การทดสอบสมมติฐาน: ตัวกรองเสียงรบกวน
คุณสร้างโมเดลที่คาดว่าจะให้ผลตอบแทนรายปี 15% แล้วเป็นจริงไหม? ตั้งสมมติฐานว่าง: H₀: ค่าคาดหวังเท่ากับศูนย์ คำนวณสถิติทดสอบและ p-value แต่ระวัง: ถ้าทดสอบกลยุทธ์ 1,000 รายการ โดยบังเอิญ ก็อาจพบ p-value ต่ำกว่า 0.05 ถึง 50 รายการ นี่คือปัญหาการเปรียบเทียบหลายรายการ วิธีแก้คือ Bonferroni correction หรือการควบคุม false discovery rate ด้วย Benjamini-Hochberg นักเทรดมือใหม่มักประเมินค่าความสำคัญผิด ควรยอมรับความจริงว่ากลยุทธ์ส่วนใหญ่เป็นเสียงรบกวน เพื่อประหยัดเงิน
การวิเคราะห์ถดถอย: แยกแยะผลตอบแทน
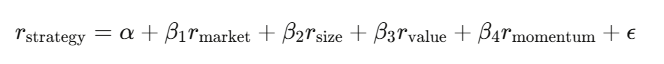
การถดถอยเชิงเส้น y = Xβ + ε เป็นเครื่องมือหลักในวงการการเงิน คุณนำผลตอบแทนกลยุทธ์ไปถดถอยกับปัจจัยเสี่ยงที่รู้จักกัน แล้วค่าคงที่ α คือผลตอบแทนเกินพอร์ต—ส่วนที่ไม่สามารถอธิบายด้วยปัจจัยที่รู้
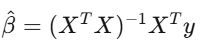
ถ้าเมื่อควบคุมปัจจัยแล้ว α เป็นศูนย์ แปลว่าความได้เปรียบของคุณเป็นเพียงการเปิดเผยความเสี่ยงของตลาดเท่านั้น ต้องใช้ standard error แบบ Newey-West เพราะข้อมูลการเงินมี autocorrelation และ heteroskedasticity standard error แบบธรรมดาเหมือนขับรถบนถนนที่แตกเป็นรู
การประมาณค่าที่เป็นไปได้มากที่สุด (MLE)
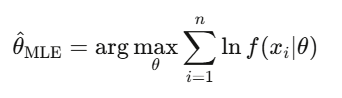
เป็นวิธีการปรับแต่งโมเดลในวงการการเงิน ไม่ว่าจะเป็นการปรับ GARCH, การประมาณพารามิเตอร์ jump diffusion หรือการปรับราคาออปชันให้ตรงกับราคาตลาด เมื่อใครพูดว่า “calibrating” โมเดล ก็หมายถึง MLE ทั้งนั้น
งานระดับ 2 (4-5 สัปดาห์)
- อ่าน: Wasserman, 《All of Statistics》 บทที่ 1-13
- ดาวน์โหลดข้อมูลผลตอบแทนหุ้นจริง (yfinance) ทดสอบความเป็นปกติ (แน่นอนว่าไม่สำเร็จ) แล้วปรับ fit ด้วย t-distribution ด้วย MLE เปรียบเทียบผล
- ใช้ statsmodels ทำการถดถอย Fama-French 3-factor กับพอร์ตหุ้น
- เขียนการทดสอบแบบ permutation: สลับวัน 10,000 ครั้ง แล้วเปรียบเทียบผลลัพธ์กับผลจริง
Part III: พีชคณิตเชิงเส้น—เครื่องจักรที่ขับเคลื่อนทุกอย่าง
พีชคณิตเชิงเส้นอาจดูน่าเบื่อ แต่เป็นเครื่องจักรหลัก: การสร้างพอร์ต การวิเคราะห์องค์ประกอบหลัก (PCA) เครือข่ายประสาท (Neural Networks) การประมาณค่าความแปรปรวนร่วม (Covariance) โมเดลปัจจัย ถ้าไม่รู้ matrix ก็ทำ Quant ไม่ได้

แนวคิดเมทริกซ์
Covariance matrix Σ จับการเคลื่อนไหวของสินทรัพย์แต่ละตัวเมื่อเทียบกับตัวอื่น สำหรับ 500 หุ้น Σ เป็นเมทริกซ์ 500×500 มีค่าไม่ต่ำกว่า 125,250 ค่า การคำนวณความแปรปรวนของพอร์ตสามารถเขียนเป็นนิพจน์ง่ายๆ: w’Σw ซึ่งเป็น quadratic form ที่เป็นแกนหลักของทฤษฎีพอร์ต Markowitz การบริหารความเสี่ยง และอื่นๆ
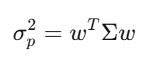
Eigenvalues: สิ่งสำคัญจริงๆ
เมื่อดูพอร์ตหุ้น 500 ตัว พบว่า 5 eigenvectors แรกอธิบายได้ 70% ของความแปรปรวนทั้งหมด ส่วนที่เหลือเป็น noise การใช้การวิเคราะห์ eigen เป็นครั้งแรก เปลี่ยนโลก: เป็นการลดมิติ และเป็นรากฐานของการลงทุนเชิงปัจจัย
งานระดับ 3 (4-6 สัปดาห์)
- ดู: คอร์ส Linear Algebra ของ Gilbert Strang จาก MIT 18.06 ทั้งคอร์ส ห้ามข้าม
- อ่าน: Strang, 《Introduction to Linear Algebra》 ทำโจทย์ให้ครบ
- ทำ PCA กับผลตอบแทน S&P 500 แล้ววาด eigenvalue spectrum หาค่า 3 อันดับแรกของ principal components
- เขียนโปรแกรมสร้างพอร์ต Markowitz จากศูนย์
import numpy as np
import cvxpy as cp
np.random.seed(42)
n_assets = 10
mu = np.random.uniform(0.04, 0.15, n_assets)
A = np.random.randn(n_assets, n_assets) * 0.1
cov = A @ A.T + np.eye(n_assets) * 0.01
w = cp.Variable(n_assets)
objective = cp.Minimize(cp.quad_form(w, cov))
constraints = [
mu @ w >= 0.08, # ผลตอบแทนขั้นต่ำ
cp.sum(w) == 1, # ลงทุนเต็มจำนวน
w >= -0.1, # ขายชอร์ตสูงสุด 10%
w <= 0.3 # ซื้อยาวสูงสุด 30%
]
prob = cp.Problem(objective, constraints)
prob.solve()
ret = mu @ w.value
vol = np.sqrt(w.value @ cov @ w.value)
sharpe = (ret - 0.03) / vol
print(f"ผลตอบแทนพอร์ต: {ret:.4f}")
print(f"ความผันผวน: {vol:.4f}")
print(f"อัตราส่วนชาร์พ: {sharpe:.4f}")
Part IV: แคลคูลัสและการปรับแต่ง—ภาษาของการเปลี่ยนแปลง
แคลคูลัสคือภาษาของการอธิบายการเปลี่ยนแปลง ในการเงิน ทุกอย่างเปลี่ยนแปลง: ราคาสินทรัพย์ ความผันผวน ความสัมพันธ์ ทั่วทั้ง distribution เปลี่ยนทุกวินาที แคลคูลัสอธิบายและใช้ประโยชน์จากการเปลี่ยนแปลงเหล่านี้ อนุพันธ์ (Derivative) ปรากฏใน backpropagation ของ neural networks และใน Greek letters ของออปชัน
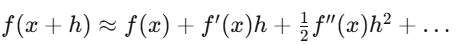
Taylor expansion เป็น approximation ขั้นแรกของ Delta hedge, Gamma hedge เพิ่มการปรับแก้ระดับสอง Itô calculus แตกต่างจากแคลคูลัสธรรมดา เพราะ stochastic processes มี second-order terms ที่ไม่หายไป
งานระดับ 4 (4-5 สัปดาห์)
- อ่าน: Boyd & Vandenberghe, 《Convex Optimization》 (PDF ฟรีจาก Stanford) บทที่ 1-5
- เขียน gradient descent จากศูนย์ เพื่อ minimization ฟังก์ชัน Rosenbrock
- ใช้ cvxpy แก้ปัญหา portfolio optimization ที่มี transaction cost
Part V: แคลคูลัสเชิงสัญญาณแบบสุ่ม—ขีดจำกัดที่แท้จริงของ Quant
ก่อนเรียนแคลคูลัสเชิงสัญญาณ คุณเป็นแค่ Data Scientist ที่ชอบการเงิน หลังเรียนจบ คุณคือ Quant ตัวจริง นั่นคือการสร้างโมเดลความไม่แน่นอนในเวลาเชิงต่อเนื่อง การ derive สมการ Black-Scholes จากหลักการแรก และเข้าใจว่าทำไมตลาดอนุพันธ์มูลค่าหลายล้านล้านดอลลาร์ถึงทำงานแบบนี้

Brownian Motion: การทำให้ความไม่แน่นอนเป็นรูปธรรม
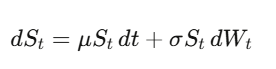
W_t เป็น stochastic process แบบต่อเนื่อง จุดสำคัญคือ (dW_t) มีขนาดเท่ากับ √dt ซึ่งหมายความว่า (dW_t)^2 = dt นี่คือข้อเท็จจริงสำคัญที่สุดใน Quant
Itô’s Lemma
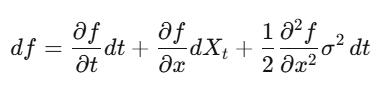
ในแคลคูลัสธรรมดา การขยาย Taylor ทำให้ (dx)² เล็กมากจนละทิ้งได้ แต่ใน stochastic calculus เมื่อ x เป็น stochastic process (dW_t)^2 เท่ากับ dt เป็น first-order term ที่ไม่สามารถละทิ้งได้ Itô’s Lemma ให้สูตร: df = (∂f/∂t + μ∂f/∂x + ½σ²∂²f/∂x²)dt + σ∂f/∂x dW_t เมื่อใช้กับการคำนวณราคาออปชัน จะได้สมการ Black-Scholes
การสอนสมการ Black-Scholes จากศูนย์
ขั้นตอนที่ 1: ตั้ง V(S,t) เป็นราคาของออปชัน แล้วใช้ Itô’s Lemma กับ V
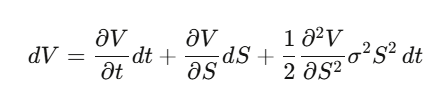
ขั้นตอนที่ 2: สร้างพอร์ต Delta-hedged Π = V − (∂V/∂S)·S แล้วคำนวณ dΠ—ความไม่แน่นอนของ dW_t จะถูกยกเลิกในที่สุด
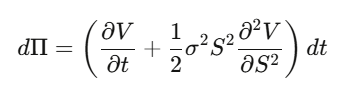
ขั้นตอนที่ 3: พอร์ตที่ไม่มีความเสี่ยงจะต้องเติบโตในอัตราดอกเบี้ยไร้ความเสี่ยง
ขั้นตอนที่ 4: จัดเรียงสมการให้ได้สมการเชิงอนุพันธ์ของ Black-Scholes
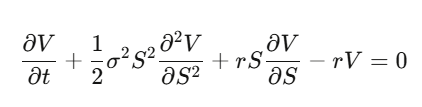
สังเกตว่า ความคาดหวังของผลตอบแทน μ หายไป ราคาของออปชันจึงไม่ขึ้นอยู่กับความคาดหวังของราคาหุ้น แต่ขึ้นอยู่กับความเสี่ยงและความไม่แน่นอนเท่านั้น คุณสามารถใช้แนวคิด risk-neutral measure เพื่อประเมินราคาได้ ซึ่งเป็นความเข้าใจที่สำคัญที่สุดในวงการ
สำหรับออปชันแบบ European ที่มีราคาใช้ strike K และเวลาถึงหมดอายุ T สมการคือ:
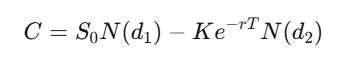
โดยที่
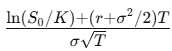
และ
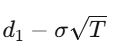
Greek Letters
- Delta Δ: อัตราการเปลี่ยนแปลงของราคาของออปชันต่อการเปลี่ยนแปลงของราคาหุ้น
- Gamma Γ: อัตราการเปลี่ยนแปลงของ Delta
- Theta Θ: การเสื่อมค่าของมูลค่าเวลา
- Vega V: ความไวต่อความผันผวน
- Rho ρ: ความไวต่ออัตราดอกเบี้ย
import numpy as np
from scipy.stats import norm
def black_scholes(S, K, T, r, sigma, option_type='call'):
d1 = (np.log(S/K) + (r + sigma**2/2)*T) / (sigma*np.sqrt(T))
d2 = d1 - sigma*np.sqrt(T)
if option_type == 'call':
return S*norm.cdf(d1) - K*np.exp(-r*T)*norm.cdf(d2)
else:
return K*np.exp(-r*T)*norm.cdf(-d2) - S*norm.cdf(-d1)
def monte_carlo_option(S0, K, T, r, sigma, n_sims=500_000):
Z = np.random.standard_normal(n_sims)
ST = S0 * np.exp((r - sigma**2/2)*T + sigma*np.sqrt(T)*Z)
payoffs = np.maximum(ST - K, 0)
price = np.exp(-r*T) * np.mean(payoffs)
stderr = np.exp(-r*T) * np.std(payoffs) / np.sqrt(n_sims)
return price, stderr
S, K, T, r, sigma = 100, 105, 1.0, 0.05, 0.2
bs_price = black_scholes(S, K, T, r, sigma)
mc_price, mc_err = monte_carlo_option(S, K, T, r, sigma)
print(f"Black-Scholes: ${bs_price:.4f}")
print(f"Monte Carlo: ${mc_price:.4f} ± {mc_err:.4f}")
งานระดับ 5 (6-8 สัปดาห์, ข้อสอบที่ยากที่สุด)
- อ่าน: Shreve, 《Stochastic Calculus for Finance II》 (มาตรฐานระดับทอง)
- ตัวเลือกทางเลือก: Arguin, 《A First Course in Stochastic Calculus》 (ใหม่กว่า เข้าใจง่ายขึ้น)
- ลอง Derive: สำหรับ f(S) = ln(S) ใช้ Itô’s Lemma เพื่อหา drift term
- Derive สมการ Black-Scholes อย่างเต็มรูปแบบ จากการอธิบายการ hedge แบบ Delta
- เขียนโปรแกรมสร้าง Black-Scholes จากศูนย์ แล้วเปรียบเทียบกับ Monte Carlo เพื่อดู convergence
Polymarket
นี่คือหนึ่งในตลาดที่น่าสนใจที่สุดในโลก ซึ่งเชื่อมโยงทุกหัวข้อในบทความนี้:
ความน่าจะเป็น (probability), ทฤษฎีข้อมูล (information theory), การปรับแต่งเชิงอนุพันธ์ (convex optimization), การวางแผนเชิงจำนวน (integer programming)
LMSR ทำอย่างไรให้ราคาความเชื่อมั่น
Logarithmic Market Scoring Rule (LMSR)
พัฒนาโดย Robin Hanson สำหรับตลาดทำนายอัตโนมัติ
สำหรับผลลัพธ์ n ผลลัพธ์ ค่าฟังก์ชันต้นทุนคือ:
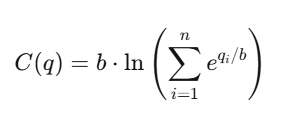
โดยที่:
- q_i คือ จำนวนหน่วยที่ออกสู่ตลาดของผลลัพธ์ i
- b คือ พารามิเตอร์ความคล่องตัว (liquidity parameter)
ราคาของผลลัพธ์ i คือ:
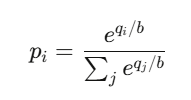
ซึ่งก็คือ ฟังก์ชัน softmax — เป็นฟังก์ชันพื้นฐานของ classifier ใน neural networks
คุณสมบัติของมันคือ:
- ผลรวมของราคาทุกผลลัพธ์เท่ากับ 1
- ราคาทุกตัวอยู่ในช่วง (0,1)
- ตลาดมีราคาตลอดเวลา เสมือนมีสภาพคล่องไม่จำกัด
และความเสียหายสูงสุดของ Market Maker ถูกจำกัดอยู่ที่: b×ln(n)
แผนเส้นทางอาชีพด้านการเทรดเชิงปริมาณ: สี่โปรไฟล์หลัก
Quant Researcher (QR): ค้นหา pattern ในข้อมูลจำนวนมหาศาล สร้างโมเดลทำนาย ออกแบบกลยุทธ์ ต้องมีปริญญาเอกด้านคณิตศาสตร์ สถิติ หรือ machine learning หรือโดดเด่นตั้งแต่ระดับปริญญาตรี ในองค์กรอย่าง Jane Street มี GPU หลายหมื่นตัว
Quant Developer/Engineer (QD): สร้างแพลตฟอร์มเทรด เอนจินการดำเนินการ และ data pipeline แบบเรียลไทม์ เพื่อให้โมเดลของ Researcher ทำงานได้ ต้องใช้ C++/Rust/Python ระดับอุตสาหกรรม ระบบ latency ต่ำ
Quant Trader (QT): ผู้ตัดสินใจ จัดการทุน ควบคุมความเสี่ยง ตัดสินใจแบบทันที ปีหนึ่งรายได้สูงสุดอาจถึงหลักสิบล้าน
Risk Quant: ตรวจสอบโมเดล คำนวณ VaR ทดสอบความเครียด และปฏิบัติตามกฎระเบียบ เส้นทางอาชีพมั่นคง แต่เพดานต่ำกว่า roles อื่นๆ roles ใหม่ที่ใช้ deep learning เพื่อสร้างสัญญาณ (เช่น AI/ML Quant) เป็นแนวโน้มเติบโตเร็วที่สุด ปี 2025 เพิ่มขึ้น 88%
อัตราเงินเดือนในสหรัฐอเมริกา (บริษัทชั้นนำเช่น Jane Street, Citadel, HRT):
- จบใหม่: 300,000 - 500,000 ดอลลาร์ รวมโบนัส
- ระดับกลาง (3-7 ปี): 550,000 - 950,000 ดอลลาร์
- ระดับสูง (8 ปีขึ้นไป): 1,000,000 - 3,000,000 ดอลลาร์+
- Top Trader/PM: 3,000,000 - 30,000,000 ดอลลาร์+
บริษัทขนาดกลาง (Two Sigma, DE Shaw) จ้างจบใหม่ประมาณ 250,000 - 350,000 ดอลลาร์ รวมโบนัส ค่าเฉลี่ยของ Jane Street ในปี 2025 อยู่ที่ประมาณ 1.4 ล้านดอลลาร์ต่อปี
กระบวนการสัมภาษณ์: คัดเลือกเรซูเม่ → ทดสอบออนไลน์ (ใช้ Zetamac สำหรับ mental math, คำถามเชิงตรรกะ) → สัมภาษณ์ทางโทรศัพท์ (คำถามความน่าจะเป็น เกมการพนัน) → Superday (หลายรอบ รวมถึงการเทรดจำลอง การเขียนโปรแกรม การวิเคราะห์บน whiteboard) บริษัทจะตั้งคำถามยากเพื่อดูว่าคุณใช้คำใบ้และการทำงานร่วมกันอย่างไร บางครั้งผู้สมัครเกินครึ่งเป็นสายคอมพิวเตอร์ วิทยาศาสตร์ข้อมูล หรือคณิตศาสตร์ โดยไม่จำเป็นต้องมีความรู้ด้านการเงิน
เตรียมตัวด้วยหนังสือ “Green Book” ของ Zhou (คู่มือสัมภาษณ์ Quant) พร้อมแพลตฟอร์ม QuantGuide.io (LeetCode สำหรับ Quant) และ Brainstellar
เครื่องมือและหนังสือแนะนำ
เทคโนโลยี Python: pandas/polars สำหรับข้อมูล (Polars เร็วกว่า pandas มากในข้อมูลขนาดใหญ่), numpy/scipy สำหรับคำนวณ, xgboost/lightgbm สำหรับ machine learning, pytorch สำหรับ deep learning, cvxpy สำหรับ optimization, QuantLib สำหรับ derivatives, statsmodels สำหรับสถิติ, NautilusTrader หรือ vectorbt สำหรับ backtesting
ข้อมูลฟรี: yfinance, Finnhub (ทุกนาที 60 requests), Alpha Vantage สำหรับข้อมูลทั่วไป, Polygon.io (รายเดือน 199 ดอลลาร์, latency ต่ำกว่า 20ms), Bloomberg Terminal (ประมาณ 32,000 ดอลลาร์ต่อปี)
หนังสือแนะนำ (เรียงตามลำดับ):
- พื้นฐานคณิตศาสตร์: Blitzstein & Hwang 《Probability》 → Strang 《Linear Algebra》 → Wasserman 《All of Statistics》 → Boyd & Vandenberghe 《Convex Optimization》 → Shreve 《Stochastic Calculus I & II》
- การเงินเชิงปริมาณ: Hull 《Options, Futures and Other Derivatives》 → Natenberg 《Option Volatility & Pricing》 → López de Prado 《Advances in Financial Machine Learning》 → Ernest Chan 《Quantitative Trading》 → Zuckerman 《The Man Who Solved the Market》
- สัมภาษณ์งาน: Zhou 《Green Book》 → Crack 《Heard on the Street》 → Joshi 《Quant Interview Questions》
- การแข่งขัน: Kaggle ของ Jane Street (รางวัล 100,000 ดอลลาร์), WorldQuant BRAIN (ผู้ใช้เกิน 100,000, ซื้อ signal alpha), Citadel Datathon (เส้นทางสู่งานเต็มเวลา)
สามสิ่งที่ผู้เขียนหวังว่าตนเองจะรู้เร็วกว่านี้
ความผิดพลาดในการประมาณค่าคือศัตรูตัวจริง การเดิมพัน Full Kelly, Markowitz ที่ไม่มีข้อจำกัด, โมเดล machine learning ที่มี feature เยอะเกินไป ล้วนเกิดจาก overfitting และ noise ในการประมาณค่าพารามิเตอร์ ทั้งในเชิงทฤษฎีและปฏิบัติ คณิตศาสตร์ทำงานได้ดีในพารามิเตอร์จริง แต่เราไม่มีพารามิเตอร์จริงเลย ความแตกต่างระหว่างทฤษฎีและการปฏิบัติคือความผิดพลาดในการประมาณ คำว่า “Quant ที่ดีที่สุด” คือคนที่เข้าใจเรื่องนี้อย่างแท้จริง
เครื่องมือได้กระจายอำนาจแล้ว แต่การตัดสินใจยังไม่ ทุกคนสามารถเข้าถึง QuantLib, Polygon.io, PyTorch ได้ แต่เทคนิคเป็นเพียงส่วนหนึ่ง ความได้เปรียบอยู่ที่ข้อมูลเฉพาะ โมเดลเฉพาะ และความสามารถในการดำเนินการ ไม่ใช่แค่ติดตั้งแพ็กเกจให้เก่ง
คณิตศาสตร์คือแนวป้องกัน (Moat) AI สามารถเขียนโค้ด เสนอแนวทาง กลยุทธ์ได้ แต่ความสามารถในการ derive เหตุผลว่าทำไม Itô’s Lemma ถึงมี term เพิ่มขึ้น, ยืนยันว่าราคาใน measure risk-neutral เป็น martingale, หรือรู้ว่าการ relax convexity ในปัญหา arbitrage เป็น tight หรือไม่—ความคล่องตัวทางคณิตศาสตร์นี้แหละ คือสิ่งที่แยกแยะ Quant ที่สร้างความได้เปรียบ กับ Quant ที่แค่ใช้ประโยชน์จากความได้เปรียบของคนอื่น ความได้เปรียบที่ยืมมาได้มีวันหมดอายุ