З розвитком децентралізованих AI-технологій різні проєкти впроваджують унікальні стратегії для вирішення питань довіри до обчислень та підвищення ефективності оптимізації моделей. Розробники часто обирають між продуктивністю інференсу, можливостями навчання та механізмами мотивації, залежно від обраної інфраструктури. Тому порівняння OpenGradient та Bittensor є показовим у цьому напрямку.
Головні відмінності проявляються у трьох площинах: архітектурі мережі, способі обчислень та економічних мотиваціях. Саме ці фактори визначають позиціонування кожної AI-мережі та її сфери використання.
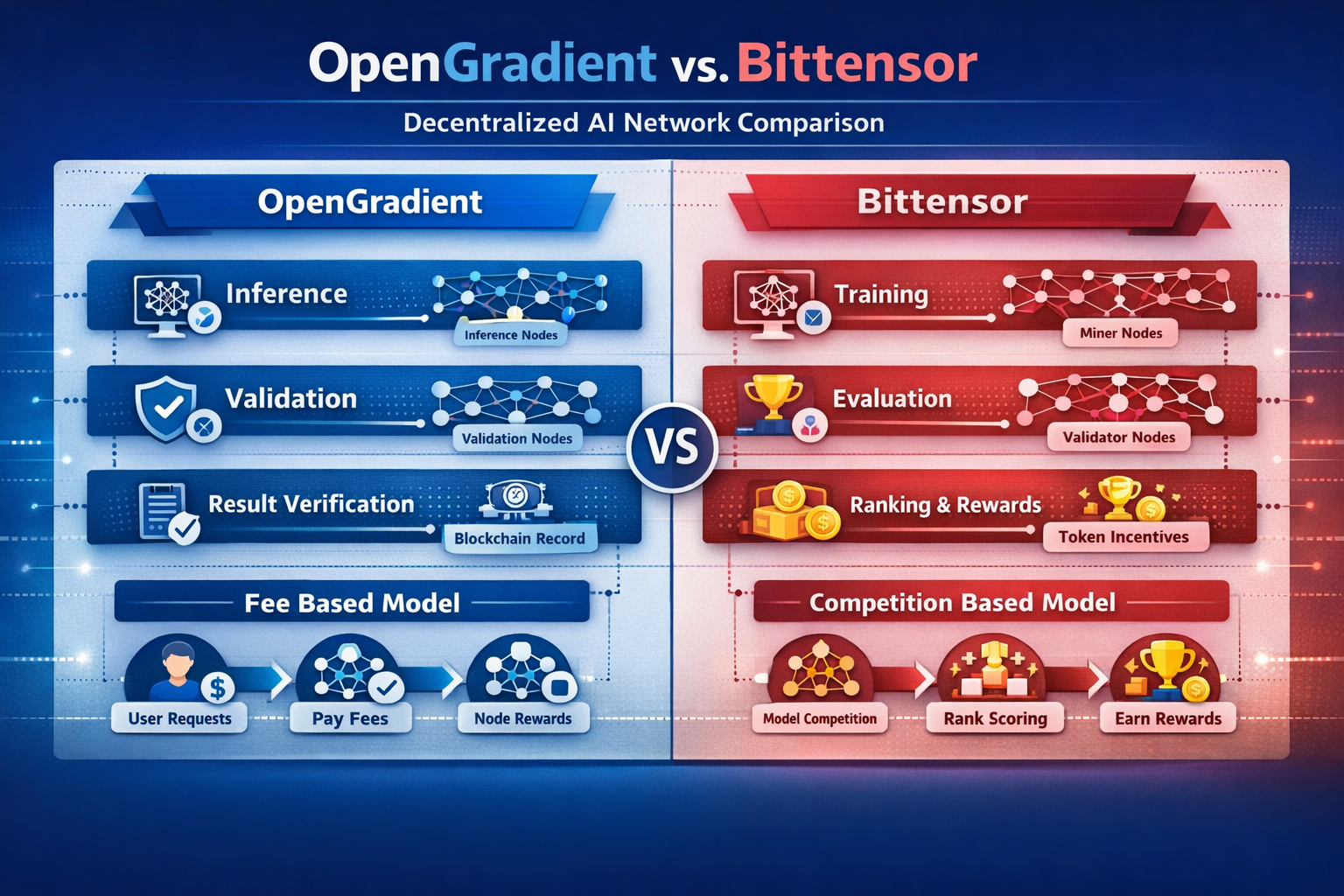
Що таке OpenGradient?
OpenGradient — децентралізована обчислювальна мережа, створена для виконання AI-інференсу та підтвердження результатів.
Система OpenGradient спрямовує запити користувачів до вузлів інференсу, які виконують завдання. Вузли верифікації незалежно перевіряють результати, забезпечуючи їх достовірність. Така архітектура фокусується на перевірених обчисленнях, а не лише на максимальній продуктивності моделей.
Мережа складається із вузлів інференсу, вузлів верифікації та шару даних, що чітко розділяє виконання й перевірку, формуючи багаторівневу обчислювальну систему.
Ця структура дозволяє AI-інференсу працювати без довіри до окремого учасника, тому OpenGradient оптимально підходить для завдань, де важлива точність результату.
Що таке Bittensor?
Bittensor — децентралізована мережа, орієнтована на навчання моделей і підвищення їх конкурентної якості.
Вузли змагаються, подаючи результати моделей, а система розподіляє винагороди за якість виходу, створюючи ринкове середовище для навчання. Це мотивує вузли постійно вдосконалювати моделі задля максимізації прибутку.
Мережа включає майнерів і вузли-валідатори. Валідаційні вузли оцінюють якість виходу моделей і визначають розподіл винагород.
Такий механізм стимулює постійне вдосконалення моделей і самооптимізацію мережі через економічні мотивації.
Як відрізняється архітектура OpenGradient та Bittensor?
OpenGradient і Bittensor обирають різні архітектурні концепції.
OpenGradient побудований на багаторівневій структурі, яка розділяє виконання інференсу та верифікацію. Bittensor використовує конкурентну структуру, де продуктивність моделей підвищується через змагання між вузлами.
OpenGradient акцентує модульність — окремі шари доступу, виконання та перевірки. Bittensor фокусується на внутрішніх системах оцінювання та стимулювання.
| Вимір |
OpenGradient |
Bittensor |
| Тип архітектури |
Багаторівнева структура |
Конкурентна мережа |
| Основні модулі |
Інференс + Верифікація |
Навчання + Оцінка |
| Взаємодія вузлів |
Спільне виконання |
Конкурентне співробітництво |
| Метод розширення |
Модульна експансія |
Конкурентна експансія вузлів |
| Мета |
Достовірність результату |
Оптимізація моделей |
Отже, OpenGradient фокусується на довірі до обчислень, а Bittensor — на підвищенні якості моделей.
Які відмінності між механізмами інференсу OpenGradient та навчанням Bittensor?
Основна різниця — у способі обчислень.
OpenGradient спеціалізується на інференсі — обробці вхідних даних та генерації результатів із незалежною перевіркою. Bittensor орієнтований на навчання, постійно вдосконалюючи моделі через конкуренцію.
У OpenGradient процес фіксований: розподіл запитів, виконання інференсу, перевірка результатів. Bittensor працює через цикли конкуренції та коригування моделей.
Відповідно, OpenGradient підходить для обчислень у реальному часі, а Bittensor — для тривалого навчання та оптимізації моделей.
Як працюють та розподіляються механізми стимулювання?
Мотиваційні структури формують поведінку вузлів.
OpenGradient винагороджує вузли за інференс і верифікацію, компенсація залежить від попиту користувачів. У Bittensor винагороди розподіляються всередині мережі — за якість виходу моделей.
OpenGradient базується на реальному використанні, Bittensor — на конкуренції.
Тобто, доходи OpenGradient напряму залежать від попиту на обчислення, у Bittensor — від внутрішньої оцінки мережі.
Як розподіляється контроль над даними та моделями?
Розподілений контроль визначає відкритість мережі.
У OpenGradient користувачі або розробники надають моделі, а вузли здійснюють виконання та перевірку. У Bittensor вузли самостійно управляють і оптимізують власні моделі.
OpenGradient функціонує як обчислювальна платформа; Bittensor — як ринок моделей.
Отже: OpenGradient підкреслює обчислювальний сервіс, Bittensor — конкурентну цінність моделей.
Як відрізняються сценарії застосування та екосистемні шляхи?
Фокус застосування відображає архітектурні особливості.
OpenGradient оптимальний для інференсу в реальному часі та перевірки результатів — наприклад, автоматизованих рішень чи аналітики даних. Bittensor підходить для навчання моделей та розвитку AI-можливостей.
Екосистема OpenGradient орієнтована на розробників та застосування, Bittensor — на моделі й конкуренцію вузлів.
Таким чином, ці мережі виконують різні функції — вони не є взаємозамінними і призначені для різних фаз розвитку AI-інфраструктури.
Підсумок
OpenGradient та Bittensor — два напрями децентралізованого AI: OpenGradient сфокусований на інференсі та перевірці, забезпечуючи довіру до обчислень, тоді як Bittensor — на навчанні та конкуренції для безперервного вдосконалення моделей.
FAQ
У чому головна різниця між OpenGradient і Bittensor?
OpenGradient орієнтований на інференс і перевірку; Bittensor — на навчання моделей і конкуренцію.
Чому OpenGradient акцентує на перевірці?
Щоб гарантувати достовірність результатів інференсу та виключити залежність від окремих вузлів.
Як працює механізм мотивації Bittensor?
Вузли змагаються, генеруючи якісний вихід моделей, і отримують винагороди відповідно.
Чи підходять ці мережі для одних і тих самих сценаріїв?
Ні — OpenGradient оптимізовано для задач інференсу, Bittensor — для навчання моделей.
Яка мережа краща для розробників?
Залежить від цілей: OpenGradient — для інференсу в реальному часі, Bittensor — для оптимізації моделей.









