Autor: CJ_Blockchain
Am 3. Februar 2025 wurde das Modell DeepSeek-R1 still auf der nationalen Supercomputer-Internetplattform eingeführt.
Im folgenden Monat eroberte es die Welt im Sturm, da seine Leistung direkt mit Top-geschlossenen Modellen vergleichbar war und die Trainingskosten fast zum Schnäppchenpreis angeboten wurden.
Dies führte zu einem massiven Absturz der AI-Aktien in den USA und markierte den Beginn des chinesischen AI-“DeepSeek”-Zeitalters.
Am 10. März 2026 kündigte Bittensor’s Subnet 3 Templar die Fertigstellung des größten dezentralen großen Sprachmodells (LLM) in der Geschichte an — Covenant-72B.
Dies ist das größte dezentral vortrainierte große Sprachmodell:
720 Millionen Parameter, trainiert auf einem Dataset von etwa 1,1 Billionen Tokens, vollständig über das Netzwerk von Bittensor Subnet 3 realisiert, ohne Genehmigung, mit über 70 unabhängigen Knoten, die frei teilnehmen.
Bittensor erlebt seinen eigenen DeepSeek-Moment.
1. Templar (SN3): Von Datensammlung zu Kerntrainingsparadigma
Templar war ursprünglich das SN3, betrieben von Omega Labs, das sich in den Anfangszeiten auf die Sammlung und Erschließung multimodaler Daten konzentrierte. Mit der Weiterentwicklung des Bittensor-Mechanismus vollzog dieses Subnetz den strategischen Sprung vom „Datenlieferanten“ zum „Modellschmied“.
Derzeit positioniert sich Templar als Infrastruktur für das globale verteilte Vortraining großer Modelle. Es nutzt Anreizmechanismen, um heterogene Rechenleistung weltweit zu bündeln, mit dem Ziel, die extrem hohen Rechenkosten und die Zentralisierung bei der Überprüfung großer Modelle zu lösen. Der erfolgreiche Abschluss von Covenant-72B bestätigt die Reife dieses dezentralen Produktionsmodells.
2. Covenant-72B: Durchbrechung der Skalierungshürde bei dezentralem Training
Covenant-72B ist ein Meilenstein, der von Templar hervorgebracht wurde, und das derzeit größte dichte Vortrainingsmodell in einem dezentralen Netzwerk.
- Kernparameter: 72 Milliarden Parameter, vortrainiert auf einem Hochleistungs-DCLM-Korpus.
- Leistungsniveau: In Basistests vergleichbar mit Meta’s Llama-2-70B.
- Anweisungsoptimierung: Nach Feinabstimmung zeigt Covenant-72B-Chat in den Bereichen IFEval (Befolgen von Anweisungen) und MATH (mathematisches Denken) eine starke Wettbewerbsfähigkeit, sogar in bestimmten Metriken besser als geschlossene Modelle gleicher Größe.
- Inferenzeffizienz: Das Modell erreicht eine Durchsatzrate von 450 Tokens/sec, was die Antwortlatenz in der Praxis deutlich reduziert.
3. SparseLoCo-Algorithmus: Die zugrunde liegende Engine für dezentrales Training
Das Training eines 72B-Modells im normalen Internetumfeld ist vor allem durch die Bandbreitenbegrenzung zwischen den Knoten herausfordernd. Templar hat mit dem Kernalgorithmus SparseLoCo einen qualitativen Durchbruch erzielt:
- Extrem komprimiert: Der Algorithmus überträgt nur 1-3 % der Kern-Gradienten und quantisiert die Daten auf 2 Bits, was den Netzwerkbedarf erheblich senkt.
- Niedrige Synchronisationsfrequenz: Anders als bei traditionellen Clustern, die bei jedem Schritt synchronisieren, erlaubt SparseLoCo den Knoten, nach 15-250 lokalen Iterationen eine globale Synchronisation durchzuführen.
- Fehlerkompensation: Durch lokale Gradientenakkumulation wird sichergestellt, dass die Konvergenzgenauigkeit auch bei Verlust von über 97 % der Informationen erhalten bleibt.
Diese technische Herangehensweise beweist: Auch ohne teure InfiniBand-Cluster kann man mit normalen Netzwerken weltweit Top-Intelligenz produzieren.
4. Branchenbewertungen und Marktreaktionen
Die technischen Errungenschaften von Templar haben die Aufmerksamkeit der Mainstream-AI-Szene und der Kapitalmärkte auf sich gezogen:
- Anerkennung durch Autoritäten:
Jack Clark, Mitbegründer von Anthropic, klassifizierte Templar in seinem Analysebericht als das weltweit größte aktive dezentrale Trainingsnetzwerk und hob die unerwartete Geschwindigkeit seiner Entwicklung hervor.
Jason Calacanis (Moderator des All-In Podcasts und bekannter Silicon-Valley-Investor) stellte in seinem Blog ausführlich das Bittensor-Mechanismus vor und deutete an, dass man in den Kauf investieren sollte.
- Institutionelle Positionierung:
Grayscale erhöht kontinuierlich seine TAO-Bestände und sieht es als Kerninvestment im dezentralen AI-Sektor.
DCG hat Yuma gegründet, das sich auf die Beschleunigung der Bittensor (TAO)-Ökologie spezialisiert hat, und gilt als die größte und direkteste Wette von DCG auf dezentrale AI.
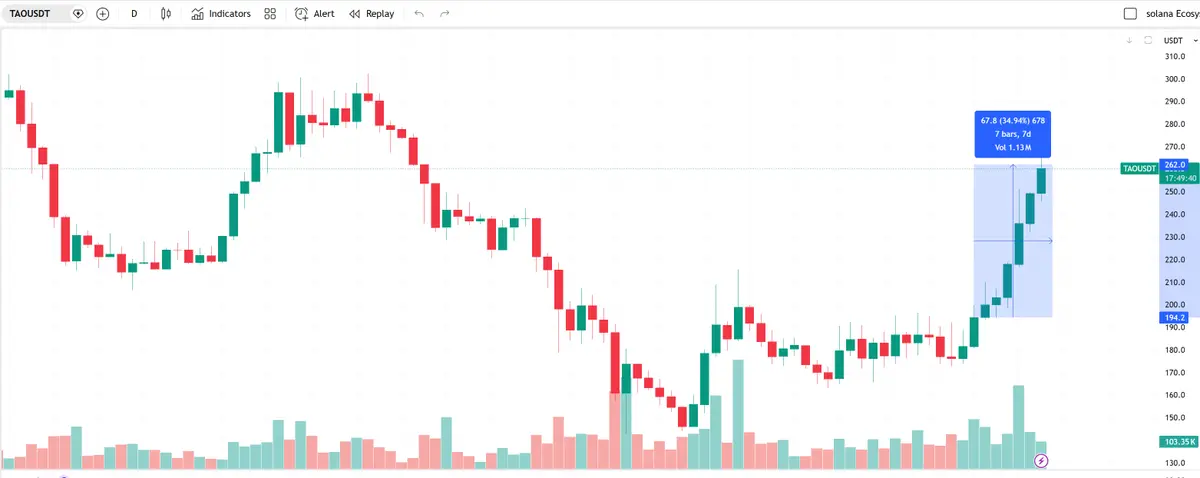
$TAO: Nach der Ankündigung von Templar, das 72B-Modell fertigzustellen, stieg TAO um über 30 %, zeigte in der schwankenden BTC-Phase eine starke Performance.
$Templar (SN-3): Templar stieg innerhalb von 7 Tagen um 75 %, gilt als das derzeit dominierende Projekt bei der Emissionserfassung von Bittensor. Derzeitige Marktkapitalisierung nur 70 Mio.
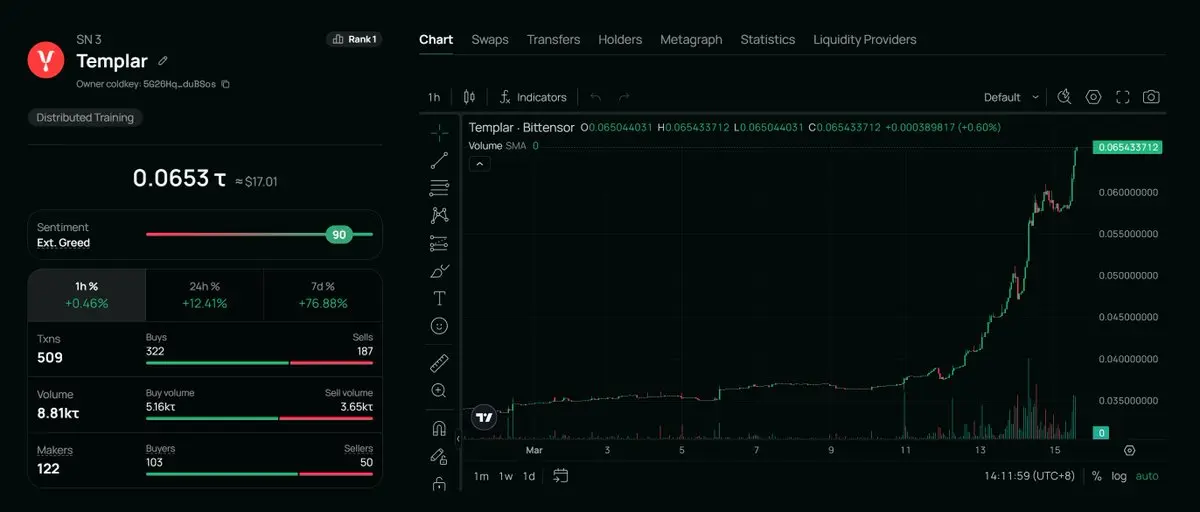
5. Investitionspotenzial der Subnetze und ökologische Grenzen
Der Erfolg von Templar eröffnet völlig neue Perspektiven für das Bittensor-Ökosystem:
- Werteschaffung: Langfristig wurde Bittensor bisher nur als „Luft-Token“ kritisiert. Templar beweist, dass das Protokoll produktive Werkzeuge mit kommerziellem Potenzial hervorbringen kann, wodurch die Bewertung von TAO von „Narrativ“ zu „Produkt“ verschoben wird.
- Potenzial heterogener Rechenleistung: Mit der Entwicklung von „Heterogenem SparseLoCo“ könnten künftig Konsumenten-Grafikkarten (wie RTX 4090) direkt an der Ausbildung von Billionen-Parameter-Modellen teilnehmen, was die Ressourcenverteilung demokratisiert.
- Chancen für Subnetze: Im Rahmen des dTAO-Mechanismus besitzen Subnetze wie Templar, die über technische Barrieren verfügen und kontinuierlich leistungsstarke Modelle produzieren, ein hohes langfristiges Wertsteigerungspotenzial.
Templar aktueller Marktwert (MC) = 75 Mio., FDV = 350 Mio.
Im Vergleich dazu: OpenAI mit einer Bewertung von 840 Mrd., Anthropic 350 Mrd., Minimax 45 Mrd.
Es geht nicht darum, Templar direkt mit diesen Unternehmen zu vergleichen, aber in einer Welt, in der narratives Fehlen, Aufmerksamkeit schwindet und das Vertrauen in dezentrale Ansätze schwindet, ist Templar zweifellos ein starker Impuls für dezentrale AI.
Schlusswort
Templar beweist, dass dezentrale Umgebungen nicht nur Daten speichern, sondern auch intelligente Produkte hervorbringen können. Covenant-72B ist nur der Anfang. Mit der vertikalen Integration von SN3 (Vortraining), SN39 (Rechenleistung) und SN81 (Verstärkendes Lernen) entsteht eine auf Blockchain basierende, dezentrale Version von OpenAI.
Seit der Gründung der Crypto-Branche wurden unzählige Narrative widerlegt. Die populären Konzepte von dezentralem Speicher, Rechenleistung und Computing scheinen ebenfalls widerlegt. Dennoch gibt es Projekte, die unbeirrt auf dem Weg der Dezentralisierung voranschreiten und Erfolge erzielen.
Der Erfolg von Templar ist nicht nur der DeepSeek-Moment von Bittensor, sondern möglicherweise auch der DeepSeek-Moment der Crypto-Welt.
Disclaimer: The information on this page may come from third parties and does not represent the views or opinions of Gate. The content displayed on this page is for reference only and does not constitute any financial, investment, or legal advice. Gate does not guarantee the accuracy or completeness of the information and shall not be liable for any losses arising from the use of this information. Virtual asset investments carry high risks and are subject to significant price volatility. You may lose all of your invested principal. Please fully understand the relevant risks and make prudent decisions based on your own financial situation and risk tolerance. For details, please refer to
Disclaimer.
